 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Deep Learning-based Rumex Obtusifolius Detection from Drone Images
Apr 28, 2026Domain adaptation (DA) addresses the challenge of transferring a machine learning model trained on a source domain to a target domain with a different data distribution. In this work, we study DA for the task of Rumex obtusifolius (Rumex) image classification. We train models on a published, ground vehicle-based dataset (source) and evaluate their performance on a custom target dataset acquired by unmanned aerial vehicles (UAVs). We find that Convolutional Neural Network (CNN) models, specifically ResNets, generalize poorly to the target domain, even after fine-tuning on the source data. Applying moment-matching and maximum classifier discrepancy, two established DA techniques, substantially improves target-domain performance. However, Vision Transformer (ViT) models pretrained with self-supervised objectives (DINOv2, DINOv3) handle domain shifts intrinsically well, surpassing even moment-matching-trained ResNets, likely due to the rich, general-purpose representations acquired during large-scale pretraining. Using ViTs fine-tuned on the source dataset, we demonstrate high classification performances in the range of F1=0.8 on our target dataset. To support further research on DA for weed detection in grassland systems, we publicly release our UAV-based target dataset AGSMultiRumex, comprising data from 15 flights over Swiss meadows.
Making Foundation Models Probabilistic via Singular Value Ensembles
Jan 29, 2026Foundation models have become a dominant paradigm in machine learning, achieving remarkable performance across diverse tasks through large-scale pretraining. However, these models often yield overconfident, uncalibrated predictions. The standard approach to quantifying epistemic uncertainty, training an ensemble of independent models, incurs prohibitive computational costs that scale linearly with ensemble size, making it impractical for large foundation models. We propose Singular Value Ensemble (SVE), a parameter-efficient implicit ensemble method that builds on a simple, but powerful core assumption: namely, that the singular vectors of the weight matrices constitute meaningful subspaces of the model's knowledge. Pretrained foundation models encode rich, transferable information in their weight matrices. If the singular vectors are indeed meaningful (orthogonal) "knowledge directions". To obtain a model ensemble, we modulate only how strongly each direction contributes to the output. Rather than learning entirely new parameters, we freeze the singular vectors and only train per-member singular values that rescale the contribution of each direction in that shared knowledge basis. Ensemble diversity emerges naturally as stochastic initialization and random sampling of mini-batches during joint training cause different members to converge to different combinations of the same underlying knowledge. SVE achieves uncertainty quantification comparable to explicit deep ensembles while increasing the parameter count of the base model by less than 1%, making principled uncertainty estimation accessible in resource-constrained settings. We validate SVE on NLP and vision tasks with various different backbones and show that it improves calibration while maintaining predictive accuracy.
Model-Agnostic, Temperature-Informed Sampling Enhances Cross-Year Crop Mapping with Deep Learning
Jun 15, 2025Conventional benchmarks for crop type classification from optical satellite time series typically assume access to labeled data from the same year and rely on fixed calendar-day sampling. This limits generalization across seasons, where crop phenology shifts due to interannual climate variability, and precludes real-time application when current-year labels are unavailable. Furthermore, uncertainty quantification is often neglected, making such approaches unreliable for crop monitoring applications. Inspired by ecophysiological principles of plant growth, we propose a simple, model-agnostic sampling strategy that leverages growing degree days (GDD), based on daily average temperature, to replace calendar time with thermal time. By uniformly subsampling time series in this biologically meaningful domain, the method emphasizes phenologically active growth stages while reducing temporal redundancy and noise. We evaluate the method on a multi-year Sentinel-2 dataset spanning all of Switzerland, training on one growing season and testing on other seasons. Compared to state-of-the-art baselines, our method delivers substantial gains in classification accuracy and, critically, produces more calibrated uncertainty estimates. Notably, our method excels in low-data regimes and enables significantly more accurate early-season classification. With only 10 percent of the training data, our method surpasses the state-of-the-art baseline in both predictive accuracy and uncertainty estimation, and by the end of June, it achieves performance similar to a baseline trained on the full season. These results demonstrate that leveraging temperature data not only improves predictive performance across seasons but also enhances the robustness and trustworthiness of crop-type mapping in real-world applications.
LoRA-Ensemble: Efficient Uncertainty Modelling for Self-attention Networks
May 23, 2024Numerous crucial tasks in real-world decision-making rely on machine learning algorithms with calibrated uncertainty estimates. However, modern methods often yield overconfident and uncalibrated predictions. Various approaches involve training an ensemble of separate models to quantify the uncertainty related to the model itself, known as epistemic uncertainty. In an explicit implementation, the ensemble approach has high computational cost and high memory requirements. This particular challenge is evident in state-of-the-art neural networks such as transformers, where even a single network is already demanding in terms of compute and memory. Consequently, efforts are made to emulate the ensemble model without actually instantiating separate ensemble members, referred to as implicit ensembling. We introduce LoRA-Ensemble, a parameter-efficient deep ensemble method for self-attention networks, which is based on Low-Rank Adaptation (LoRA). Initially developed for efficient LLM fine-tuning, we extend LoRA to an implicit ensembling approach. By employing a single pre-trained self-attention network with weights shared across all members, we train member-specific low-rank matrices for the attention projections. Our method exhibits superior calibration compared to explicit ensembles and achieves similar or better accuracy across various prediction tasks and datasets.
FiLM-Ensemble: Probabilistic Deep Learning via Feature-wise Linear Modulation
May 31, 2022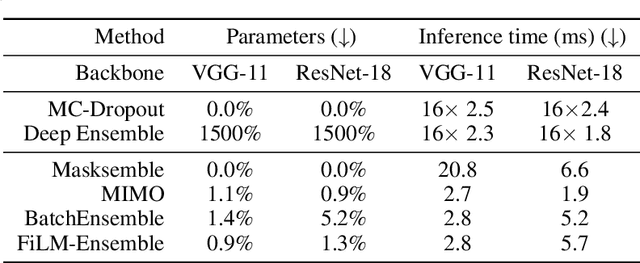
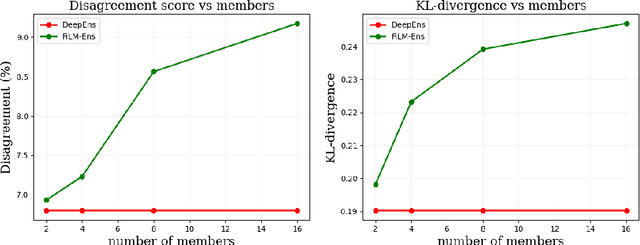
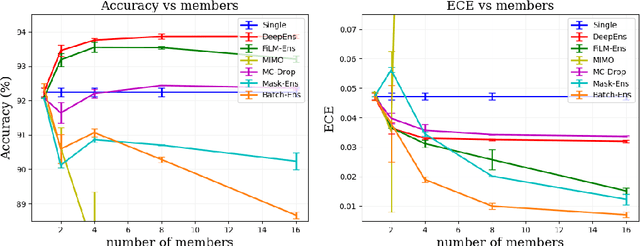
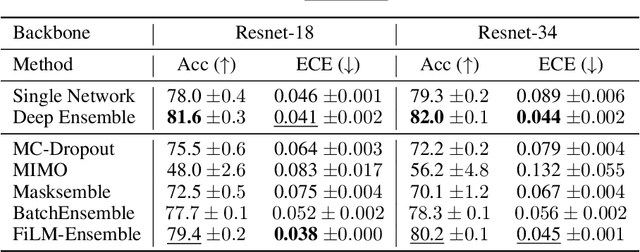
The ability to estimate epistemic uncertainty is often crucial when deploying machine learning in the real world, but modern methods often produce overconfident, uncalibrated uncertainty predictions. A common approach to quantify epistemic uncertainty, usable across a wide class of prediction models, is to train a model ensemble. In a naive implementation, the ensemble approach has high computational cost and high memory demand. This challenges in particular modern deep learning, where even a single deep network is already demanding in terms of compute and memory, and has given rise to a number of attempts to emulate the model ensemble without actually instantiating separate ensemble members. We introduce FiLM-Ensemble, a deep, implicit ensemble method based on the concept of Feature-wise Linear Modulation (FiLM). That technique was originally developed for multi-task learning, with the aim of decoupling different tasks. We show that the idea can be extended to uncertainty quantification: by modulating the network activations of a single deep network with FiLM, one obtains a model ensemble with high diversity, and consequently well-calibrated estimates of epistemic uncertainty, with low computational overhead in comparison. Empirically, FiLM-Ensemble outperforms other implicit ensemble methods, and it and comes very close to the upper bound of an explicit ensemble of networks (sometimes even beating it), at a fraction of the memory cost.
Visual Camera Re-Localization Using Graph Neural Networks and Relative Pose Supervision
Apr 12, 2021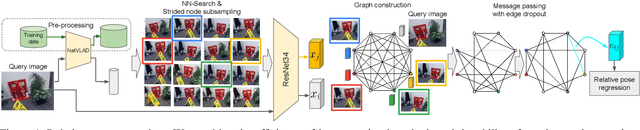
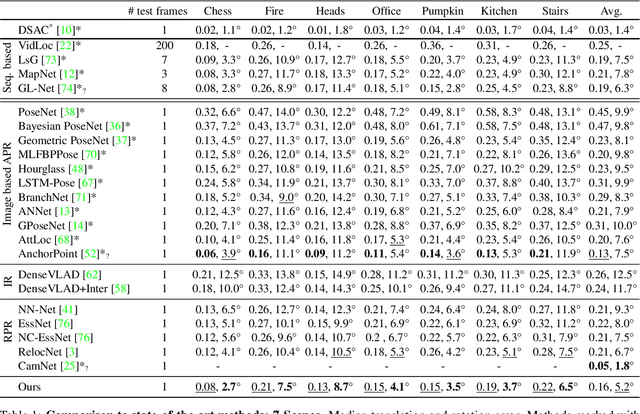
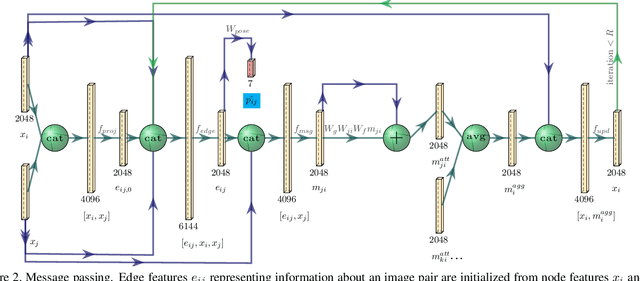

Visual re-localization means using a single image as input to estimate the camera's location and orientation relative to a pre-recorded environment. The highest-scoring methods are "structure based," and need the query camera's intrinsics as an input to the model, with careful geometric optimization. When intrinsics are absent, methods vie for accuracy by making various other assumptions. This yields fairly good localization scores, but the models are "narrow" in some way, eg., requiring costly test-time computations, or depth sensors, or multiple query frames. In contrast, our proposed method makes few special assumptions, and is fairly lightweight in training and testing. Our pose regression network learns from only relative poses of training scenes. For inference, it builds a graph connecting the query image to training counterparts and uses a graph neural network (GNN) with image representations on nodes and image-pair representations on edges. By efficiently passing messages between them, both representation types are refined to produce a consistent camera pose estimate. We validate the effectiveness of our approach on both standard indoor (7-Scenes) and outdoor (Cambridge Landmarks) camera re-localization benchmarks. Our relative pose regression method matches the accuracy of absolute pose regression networks, while retaining the relative-pose models' test-time speed and ability to generalize to non-training scenes.
Crop mapping from image time series: deep learning with multi-scale label hierarchies
Feb 17, 2021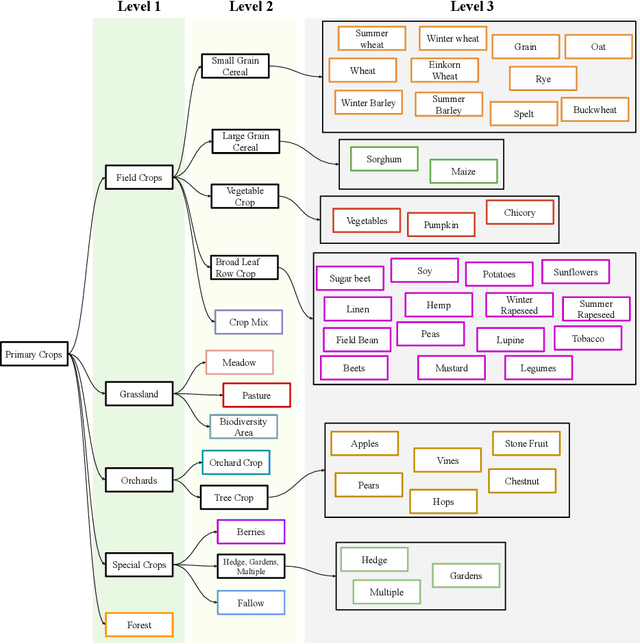
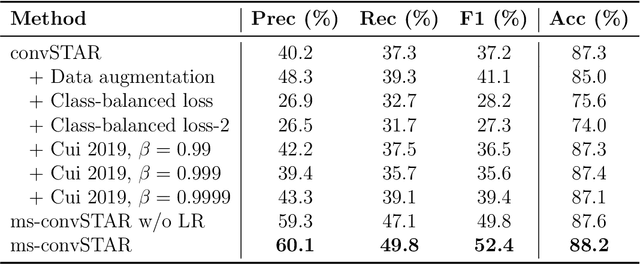
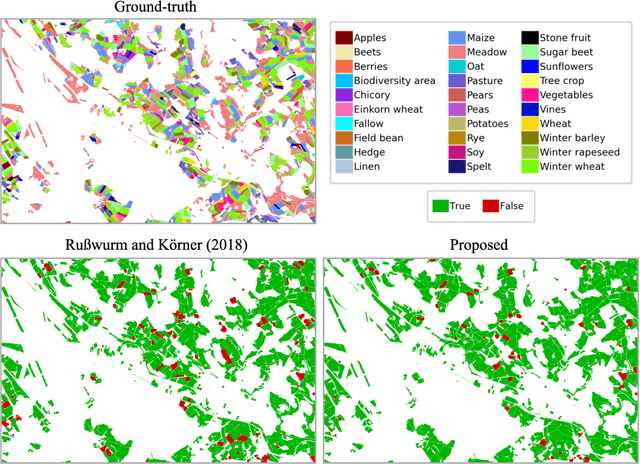
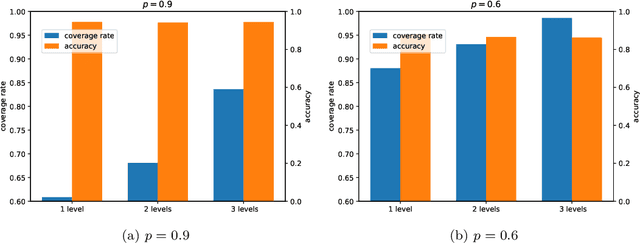
The aim of this paper is to map agricultural crops by classifying satellite image time series. Domain experts in agriculture work with crop type labels that are organised in a hierarchical tree structure, where coarse classes (like orchards) are subdivided into finer ones (like apples, pears, vines, etc.). We develop a crop classification method that exploits this expert knowledge and significantly improves the mapping of rare crop types. The three-level label hierarchy is encoded in a convolutional, recurrent neural network (convRNN), such that for each pixel the model predicts three labels at different level of granularity. This end-to-end trainable, hierarchical network architecture allows the model to learn joint feature representations of rare classes (e.g., apples, pears) at a coarser level (e.g., orchard), thereby boosting classification performance at the fine-grained level. Additionally, labelling at different granularity also makes it possible to adjust the output according to the classification scores; as coarser labels with high confidence are sometimes more useful for agricultural practice than fine-grained but very uncertain labels. We validate the proposed method on a new, large dataset that we make public. ZueriCrop covers an area of 50 km x 48 km in the Swiss cantons of Zurich and Thurgau with a total of 116'000 individual fields spanning 48 crop classes, and 28,000 (multi-temporal) image patches from Sentinel-2. We compare our proposed hierarchical convRNN model with several baselines, including methods designed for imbalanced class distributions. The hierarchical approach performs superior by at least 9.9 percentage points in F1-score.
Crop Classification under Varying Cloud Cover with Neural Ordinary Differential Equations
Dec 04, 2020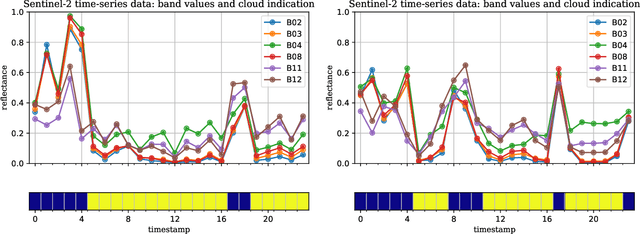

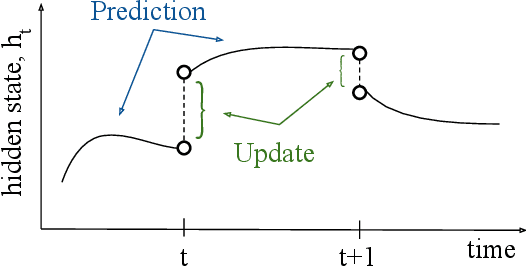
Optical satellite sensors cannot see the Earth's surface through clouds. Despite the periodic revisit cycle, image sequences acquired by Earth observation satellites are therefore irregularly sampled in time. State-of-the-art methods for crop classification (and other time series analysis tasks) rely on techniques that implicitly assume regular temporal spacing between observations, such as recurrent neural networks (RNNs). We propose to use neural ordinary differential equations (NODEs) in combination with RNNs to classify crop types in irregularly spaced image sequences. The resulting ODE-RNN models consist of two steps: an update step, where a recurrent unit assimilates new input data into the model's hidden state; and a prediction step, in which NODE propagates the hidden state until the next observation arrives. The prediction step is based on a continuous representation of the latent dynamics, which has several advantages. At the conceptual level, it is a more natural way to describe the mechanisms that govern the phenological cycle. From a practical point of view, it makes it possible to sample the system state at arbitrary points in time, such that one can integrate observations whenever they are available, and extrapolate beyond the last observation. Our experiments show that ODE-RNN indeed improves classification accuracy over common baselines such as LSTM, GRU, and temporal convolution. The gains are most prominent in the challenging scenario where only few observations are available (i.e., frequent cloud cover). Moreover, we show that the ability to extrapolate translates to better classification performance early in the season, which is important for forecasting.
Gating Revisited: Deep Multi-layer RNNs That Can Be Trained
Nov 25, 2019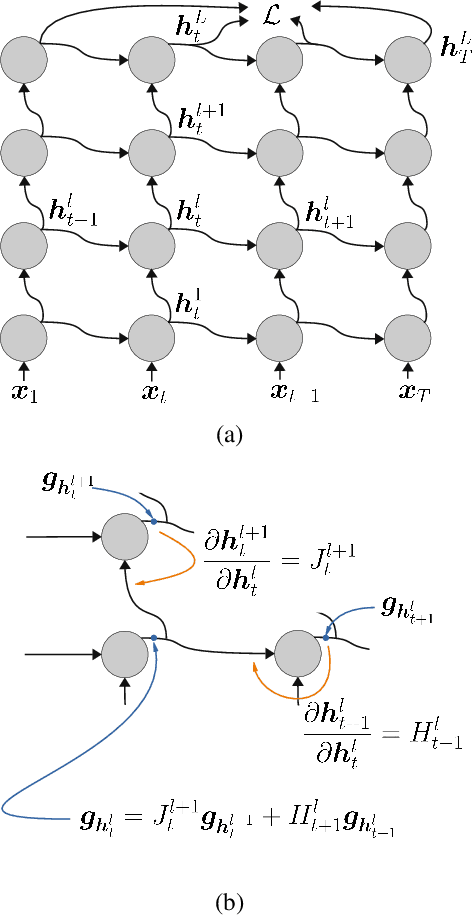
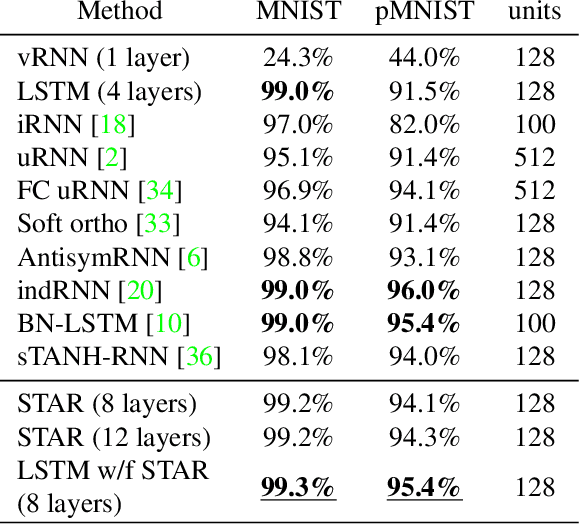


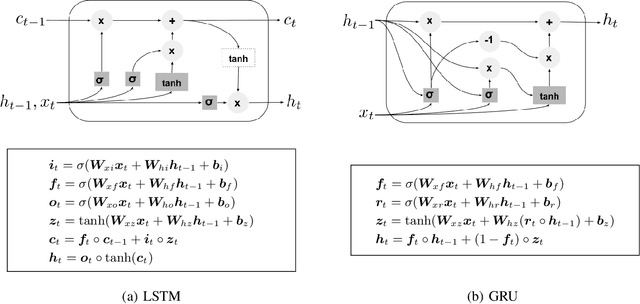
We propose a new stackable recurrent cell (STAR) for recurrent neural networks (RNNs) that has significantly less parameters than widely used LSTM and GRU while being more robust against vanishing or exploding gradients. Stacking multiple layers of recurrent units has two major drawbacks: i) many recurrent cells (e.g., LSTM cells) are extremely eager in terms of parameters and computation resources, ii) deep RNNs are prone to vanishing or exploding gradients during training. We investigate the training of multi-layer RNNs and examine the magnitude of the gradients as they propagate through the network in the "vertical" direction. We show that, depending on the structure of the basic recurrent unit, the gradients are systematically attenuated or amplified. Based on our analysis we design a new type of gated cell that better preserves gradient magnitude. We validate our design on a large number of sequence modelling tasks and demonstrate that the proposed STAR cell allows to build and train deeper recurrent architectures, ultimately leading to improved performance while being computationally efficient.
A Layer-Based Sequential Framework for Scene Generation with GANs
Feb 02, 2019


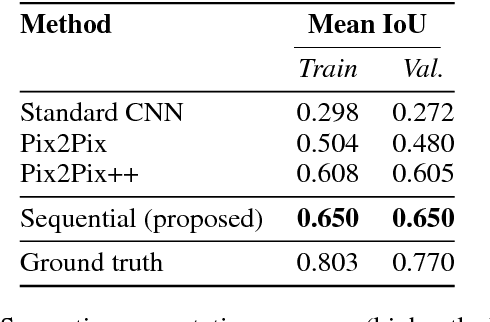
The visual world we sense, interpret and interact everyday is a complex composition of interleaved physical entities. Therefore, it is a very challenging task to generate vivid scenes of similar complexity using computers. In this work, we present a scene generation framework based on Generative Adversarial Networks (GANs) to sequentially compose a scene, breaking down the underlying problem into smaller ones. Different than the existing approaches, our framework offers an explicit control over the elements of a scene through separate background and foreground generators. Starting with an initially generated background, foreground objects then populate the scene one-by-one in a sequential manner. Via quantitative and qualitative experiments on a subset of the MS-COCO dataset, we show that our proposed framework produces not only more diverse images but also copes better with affine transformations and occlusion artifacts of foreground objects than its counterparts.