 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Camera Re-Localization Using Graph Neural Networks and Relative Pose Supervision
Paper and Code
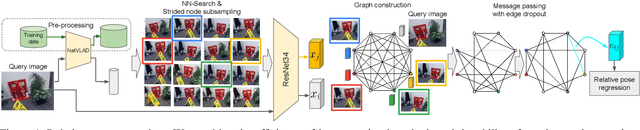
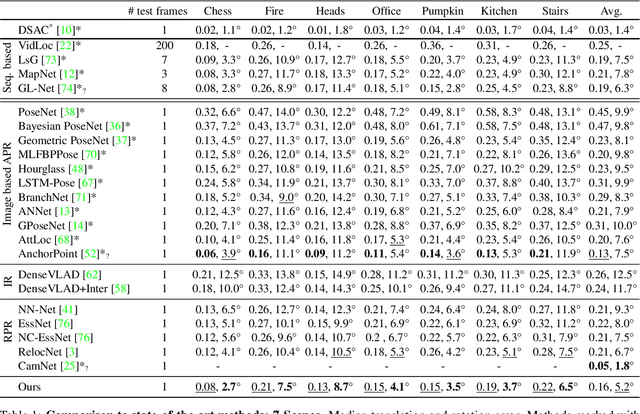
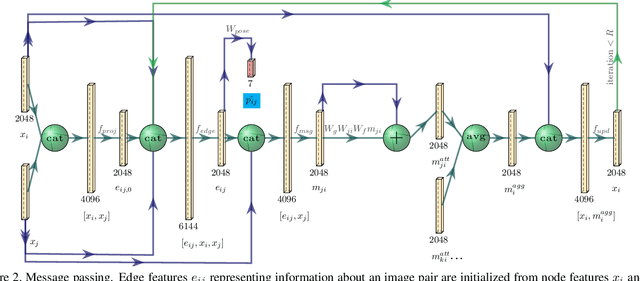

Visual re-localization means using a single image as input to estimate the camera's location and orientation relative to a pre-recorded environment. The highest-scoring methods are "structure based," and need the query camera's intrinsics as an input to the model, with careful geometric optimization. When intrinsics are absent, methods vie for accuracy by making various other assumptions. This yields fairly good localization scores, but the models are "narrow" in some way, eg., requiring costly test-time computations, or depth sensors, or multiple query frames. In contrast, our proposed method makes few special assumptions, and is fairly lightweight in training and testing. Our pose regression network learns from only relative poses of training scenes. For inference, it builds a graph connecting the query image to training counterparts and uses a graph neural network (GNN) with image representations on nodes and image-pair representations on edges. By efficiently passing messages between them, both representation types are refined to produce a consistent camera pose estimate. We validate the effectiveness of our approach on both standard indoor (7-Scenes) and outdoor (Cambridge Landmarks) camera re-localization benchmarks. Our relative pose regression method matches the accuracy of absolute pose regression networks, while retaining the relative-pose models' test-time speed and ability to generalize to non-training scenes.