 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
May 08, 2025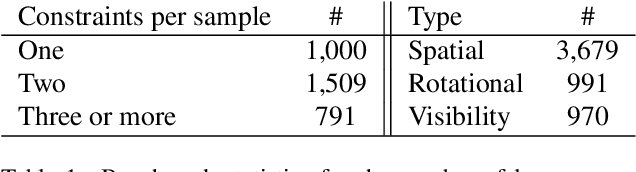
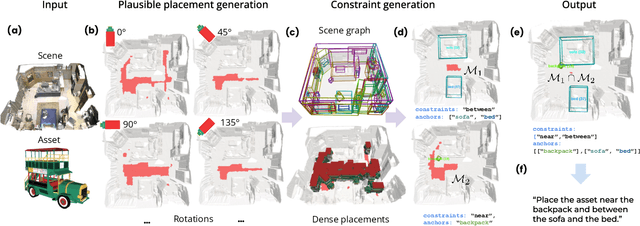
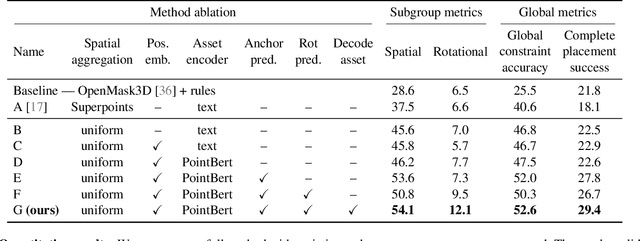
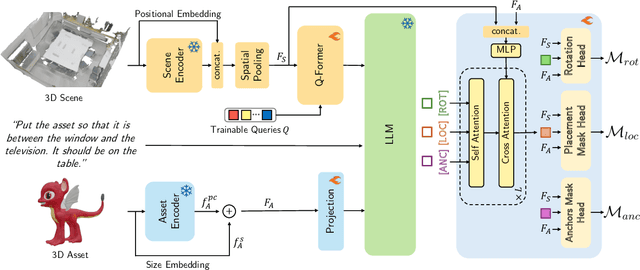
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.
Explorer: Robust Collection of Interactable GUI Elements
Apr 12, 2025Automation of existing Graphical User Interfaces (GUIs) is important but hard to achieve. Upstream of making the GUI user-accessible or somehow scriptable, even the data-collection to understand the original interface poses significant challenges. For example, large quantities of general UI data seem helpful for training general machine learning (ML) models, but accessibility for each person can hinge on the ML's precision on a specific app. We therefore take the perspective that a given user needs confidence, that the relevant UI elements are being detected correctly throughout one app or digital environment. We mostly assume that the target application is known in advance, so that data collection and ML-training can be personalized for the test-time target domain. The proposed Explorer system focuses on detecting on-screen buttons and text-entry fields, i.e. interactables, where the training process has access to a live version of the application. The live application can run on almost any popular platform except iOS phones, and the collection is especially streamlined for Android phones or for desktop Chrome browsers. Explorer also enables the recording of interactive user sessions, and subsequent mapping of how such sessions overlap and sometimes loop back to similar states. We show how having such a map enables a kind of path planning through the GUI, letting a user issue audio commands to get to their destination. Critically, we are releasing our code for Explorer openly at https://github.com/varnelis/Explorer.
MVSAnywhere: Zero-Shot Multi-View Stereo
Mar 28, 2025Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.
INQUIRE: A Natural World Text-to-Image Retrieval Benchmark
Nov 04, 2024We introduce INQUIRE, a text-to-image retrieval benchmark designed to challenge multimodal vision-language models on expert-level queries. INQUIRE includes iNaturalist 2024 (iNat24), a new dataset of five million natural world images, along with 250 expert-level retrieval queries. These queries are paired with all relevant images comprehensively labeled within iNat24, comprising 33,000 total matches. Queries span categories such as species identification, context, behavior, and appearance, emphasizing tasks that require nuanced image understanding and domain expertise. Our benchmark evaluates two core retrieval tasks: (1) INQUIRE-Fullrank, a full dataset ranking task, and (2) INQUIRE-Rerank, a reranking task for refining top-100 retrievals. Detailed evaluation of a range of recent multimodal models demonstrates that INQUIRE poses a significant challenge, with the best models failing to achieve an mAP@50 above 50%. In addition, we show that reranking with more powerful multimodal models can enhance retrieval performance, yet there remains a significant margin for improvement. By focusing on scientifically-motivated ecological challenges, INQUIRE aims to bridge the gap between AI capabilities and the needs of real-world scientific inquiry, encouraging the development of retrieval systems that can assist with accelerating ecological and biodiversity research. Our dataset and code are available at https://inquire-benchmark.github.io
Deep learning-based ecological analysis of camera trap images is impacted by training data quality and size
Aug 26, 2024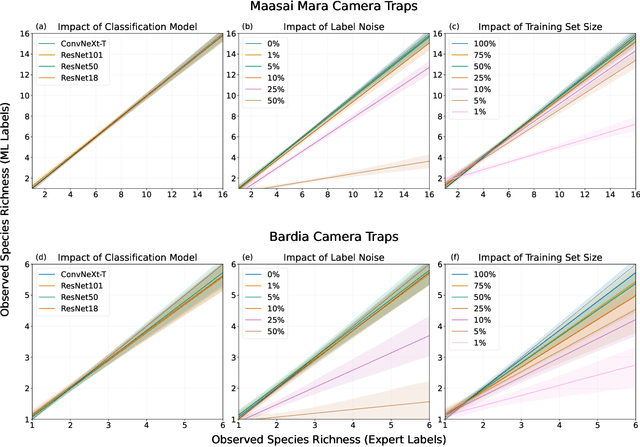
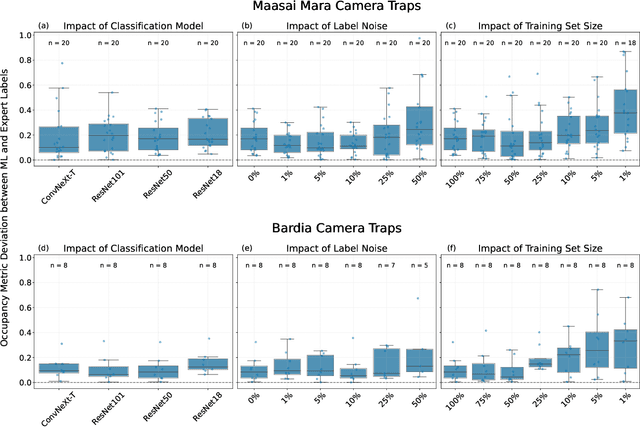
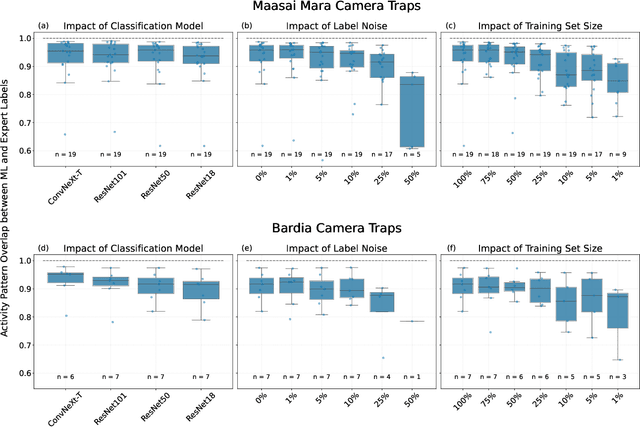
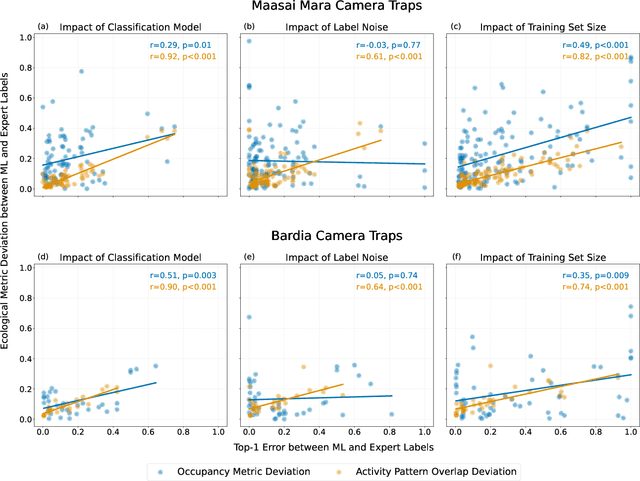
Large wildlife image collections from camera traps are crucial for biodiversity monitoring, offering insights into species richness, occupancy, and activity patterns. However, manual processing of these data is time-consuming, hindering analytical processes. To address this, deep neural networks have been widely adopted to automate image analysis. Despite their growing use, the impact of model training decisions on downstream ecological metrics remains unclear. Here, we analyse camera trap data from an African savannah and an Asian sub-tropical dry forest to compare key ecological metrics derived from expert-generated species identifications with those generated from deep neural networks. We assess the impact of model architecture, training data noise, and dataset size on ecological metrics, including species richness, occupancy, and activity patterns. Our results show that while model architecture has minimal impact, large amounts of noise and reduced dataset size significantly affect these metrics. Nonetheless, estimated ecological metrics are resilient to considerable noise, tolerating up to 10% error in species labels and a 50% reduction in training set size without changing significantly. We also highlight that conventional metrics like classification error may not always be representative of a model's ability to accurately measure ecological metrics. We conclude that ecological metrics derived from deep neural network predictions closely match those calculated from expert labels and remain robust to variations in the factors explored. However, training decisions for deep neural networks can impact downstream ecological analysis. Therefore, practitioners should prioritize creating large, clean training sets and evaluate deep neural network solutions based on their ability to measure the ecological metrics of interest.
GroundUp: Rapid Sketch-Based 3D City Massing
Jul 17, 2024



We propose GroundUp, the first sketch-based ideation tool for 3D city massing of urban areas. We focus on early-stage urban design, where sketching is a common tool and the design starts from balancing building volumes (masses) and open spaces. With Human-Centered AI in mind, we aim to help architects quickly revise their ideas by easily switching between 2D sketches and 3D models, allowing for smoother iteration and sharing of ideas. Inspired by feedback from architects and existing workflows, our system takes as a first input a user sketch of multiple buildings in a top-down view. The user then draws a perspective sketch of the envisioned site. Our method is designed to exploit the complementarity of information in the two sketches and allows users to quickly preview and adjust the inferred 3D shapes. Our model has two main components. First, we propose a novel sketch-to-depth prediction network for perspective sketches that exploits top-down sketch shapes. Second, we use depth cues derived from the perspective sketch as a condition to our diffusion model, which ultimately completes the geometry in a top-down view. Thus, our final 3D geometry is represented as a heightfield, allowing users to construct the city `from the ground up'.
TAPVid-3D: A Benchmark for Tracking Any Point in 3D
Jul 08, 2024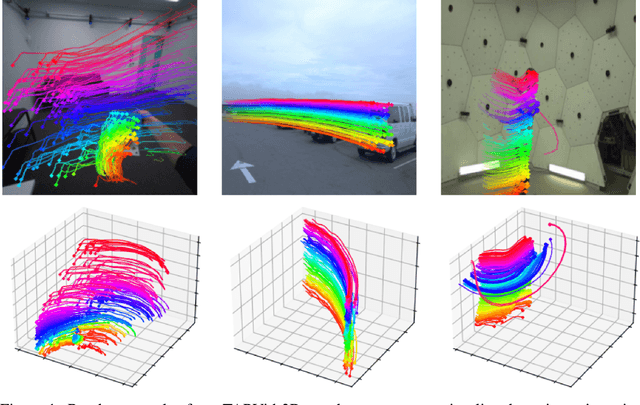
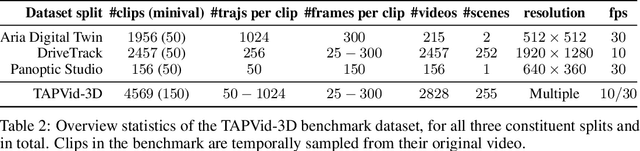
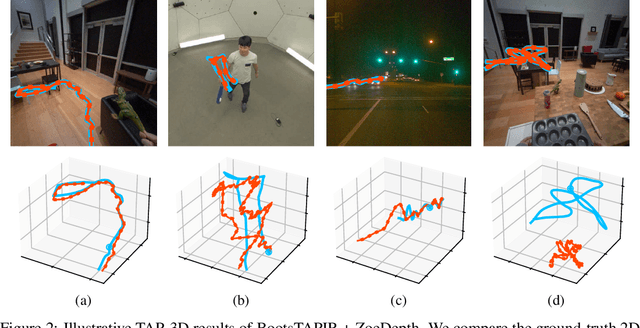
We introduce a new benchmark, TAPVid-3D, for evaluating the task of long-range Tracking Any Point in 3D (TAP-3D). While point tracking in two dimensions (TAP) has many benchmarks measuring performance on real-world videos, such as TAPVid-DAVIS, three-dimensional point tracking has none. To this end, leveraging existing footage, we build a new benchmark for 3D point tracking featuring 4,000+ real-world videos, composed of three different data sources spanning a variety of object types, motion patterns, and indoor and outdoor environments. To measure performance on the TAP-3D task, we formulate a collection of metrics that extend the Jaccard-based metric used in TAP to handle the complexities of ambiguous depth scales across models, occlusions, and multi-track spatio-temporal smoothness. We manually verify a large sample of trajectories to ensure correct video annotations, and assess the current state of the TAP-3D task by constructing competitive baselines using existing tracking models. We anticipate this benchmark will serve as a guidepost to improve our ability to understand precise 3D motion and surface deformation from monocular video. Code for dataset download, generation, and model evaluation is available at https://tapvid3d.github.io
DoubleTake: Geometry Guided Depth Estimation
Jun 26, 2024
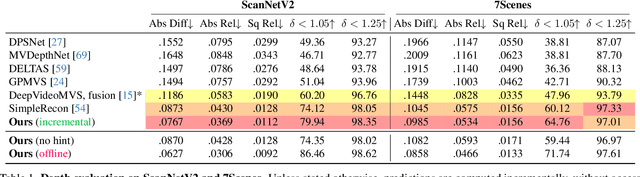
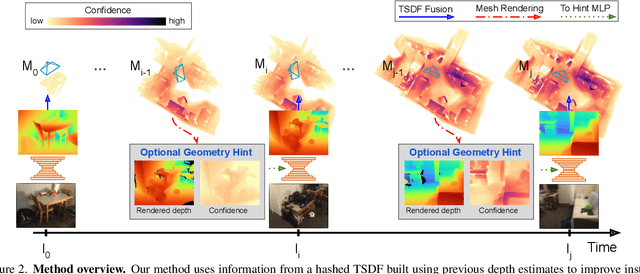
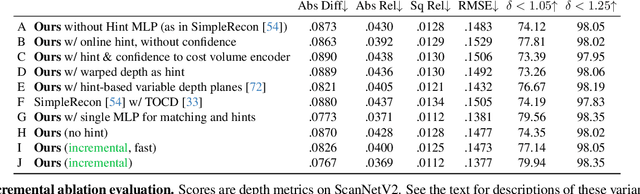
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
AirPlanes: Accurate Plane Estimation via 3D-Consistent Embeddings
Jun 13, 2024Extracting planes from a 3D scene is useful for downstream tasks in robotics and augmented reality. In this paper we tackle the problem of estimating the planar surfaces in a scene from posed images. Our first finding is that a surprisingly competitive baseline results from combining popular clustering algorithms with recent improvements in 3D geometry estimation. However, such purely geometric methods are understandably oblivious to plane semantics, which are crucial to discerning distinct planes. To overcome this limitation, we propose a method that predicts multi-view consistent plane embeddings that complement geometry when clustering points into planes. We show through extensive evaluation on the ScanNetV2 dataset that our new method outperforms existing approaches and our strong geometric baseline for the task of plane estimation.
Removing Objects From Neural Radiance Fields
Dec 22, 2022Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.