 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete Gaussian Splats from a Single Image with Denoising Diffusion Models
Aug 29, 2025Gaussian splatting typically requires dense observations of the scene and can fail to reconstruct occluded and unobserved areas. We propose a latent diffusion model to reconstruct a complete 3D scene with Gaussian splats, including the occluded parts, from only a single image during inference. Completing the unobserved surfaces of a scene is challenging due to the ambiguity of the plausible surfaces. Conventional methods use a regression-based formulation to predict a single "mode" for occluded and out-of-frustum surfaces, leading to blurriness, implausibility, and failure to capture multiple possible explanations. Thus, they often address this problem partially, focusing either on objects isolated from the background, reconstructing only visible surfaces, or failing to extrapolate far from the input views. In contrast, we propose a generative formulation to learn a distribution of 3D representations of Gaussian splats conditioned on a single input image. To address the lack of ground-truth training data, we propose a Variational AutoReconstructor to learn a latent space only from 2D images in a self-supervised manner, over which a diffusion model is trained. Our method generates faithful reconstructions and diverse samples with the ability to complete the occluded surfaces for high-quality 360-degree renderings.
MVSAnywhere: Zero-Shot Multi-View Stereo
Mar 28, 2025Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Apr 22, 2024We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
Two-View Geometry Scoring Without Correspondences
Jun 02, 2023Camera pose estimation for two-view geometry traditionally relies on RANSAC. Normally, a multitude of image correspondences leads to a pool of proposed hypotheses, which are then scored to find a winning model. The inlier count is generally regarded as a reliable indicator of "consensus". We examine this scoring heuristic, and find that it favors disappointing models under certain circumstances. As a remedy, we propose the Fundamental Scoring Network (FSNet), which infers a score for a pair of overlapping images and any proposed fundamental matrix. It does not rely on sparse correspondences, but rather embodies a two-view geometry model through an epipolar attention mechanism that predicts the pose error of the two images. FSNet can be incorporated into traditional RANSAC loops. We evaluate FSNet on fundamental and essential matrix estimation on indoor and outdoor datasets, and establish that FSNet can successfully identify good poses for pairs of images with few or unreliable correspondences. Besides, we show that naively combining FSNet with MAGSAC++ scoring approach achieves state of the art results.
DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models
Feb 23, 2023Under good conditions, Neural Radiance Fields (NeRFs) have shown impressive results on novel view synthesis tasks. NeRFs learn a scene's color and density fields by minimizing the photometric discrepancy between training views and differentiable renders of the scene. Once trained from a sufficient set of views, NeRFs can generate novel views from arbitrary camera positions. However, the scene geometry and color fields are severely under-constrained, which can lead to artifacts, especially when trained with few input views. To alleviate this problem we learn a prior over scene geometry and color, using a denoising diffusion model (DDM). Our DDM is trained on RGBD patches of the synthetic Hypersim dataset and can be used to predict the gradient of the logarithm of a joint probability distribution of color and depth patches. We show that, during NeRF training, these gradients of logarithms of RGBD patch priors serve to regularize geometry and color for a scene. During NeRF training, random RGBD patches are rendered and the estimated gradients of the log-likelihood are backpropagated to the color and density fields. Evaluations on LLFF, the most relevant dataset, show that our learned prior achieves improved quality in the reconstructed geometry and improved generalization to novel views. Evaluations on DTU show improved reconstruction quality among NeRF methods.
Map-free Visual Relocalization: Metric Pose Relative to a Single Image
Oct 11, 2022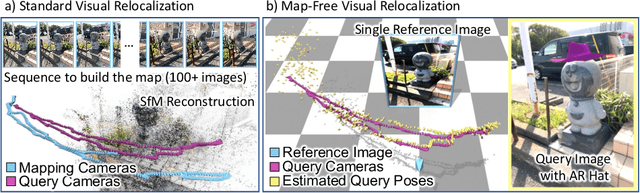

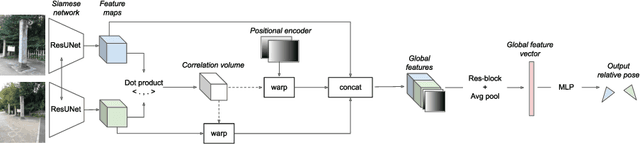

Can we relocalize in a scene represented by a single reference image? Standard visual relocalization requires hundreds of images and scale calibration to build a scene-specific 3D map. In contrast, we propose Map-free Relocalization, i.e., using only one photo of a scene to enable instant, metric scaled relocalization. Existing datasets are not suitable to benchmark map-free relocalization, due to their focus on large scenes or their limited variability. Thus, we have constructed a new dataset of 655 small places of interest, such as sculptures, murals and fountains, collected worldwide. Each place comes with a reference image to serve as a relocalization anchor, and dozens of query images with known, metric camera poses. The dataset features changing conditions, stark viewpoint changes, high variability across places, and queries with low to no visual overlap with the reference image. We identify two viable families of existing methods to provide baseline results: relative pose regression, and feature matching combined with single-image depth prediction. While these methods show reasonable performance on some favorable scenes in our dataset, map-free relocalization proves to be a challenge that requires new, innovative solutions.
Single Image Depth Estimation using Wavelet Decomposition
Jun 03, 2021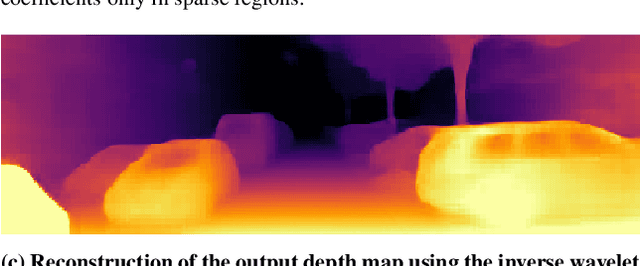
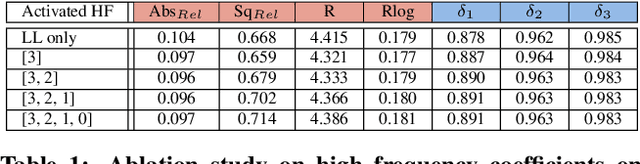
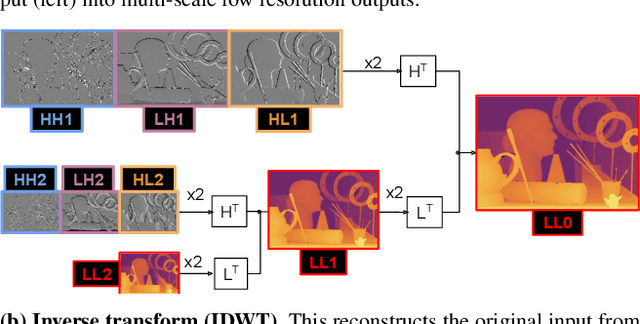
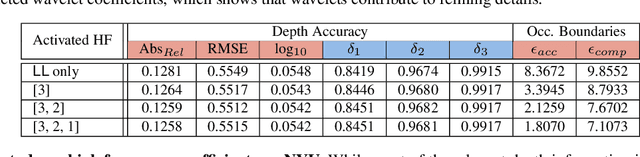
We present a novel method for predicting accurate depths from monocular images with high efficiency. This optimal efficiency is achieved by exploiting wavelet decomposition, which is integrated in a fully differentiable encoder-decoder architecture. We demonstrate that we can reconstruct high-fidelity depth maps by predicting sparse wavelet coefficients. In contrast with previous works, we show that wavelet coefficients can be learned without direct supervision on coefficients. Instead we supervise only the final depth image that is reconstructed through the inverse wavelet transform. We additionally show that wavelet coefficients can be learned in fully self-supervised scenarios, without access to ground-truth depth. Finally, we apply our method to different state-of-the-art monocular depth estimation models, in each case giving similar or better results compared to the original model, while requiring less than half the multiply-adds in the decoder network. Code at https://github.com/nianticlabs/wavelet-monodepth
Learning to Predict Repeatability of Interest Points
May 08, 2021
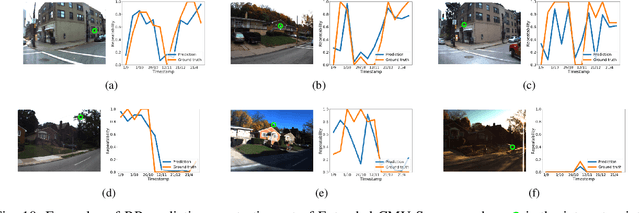
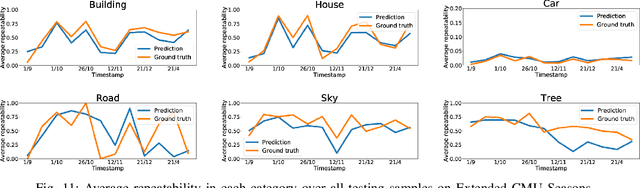
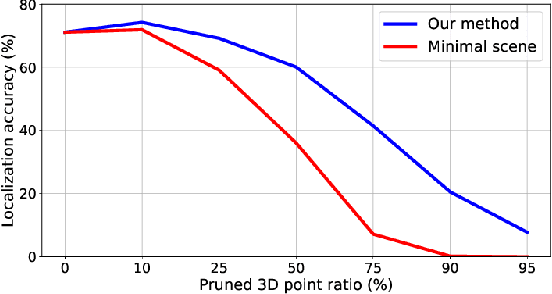
Many robotics applications require interest points that are highly repeatable under varying viewpoints and lighting conditions. However, this requirement is very challenging as the environment changes continuously and indefinitely, leading to appearance changes of interest points with respect to time. This paper proposes to predict the repeatability of an interest point as a function of time, which can tell us the lifespan of the interest point considering daily or seasonal variation. The repeatability predictor (RP) is formulated as a regressor trained on repeated interest points from multiple viewpoints over a long period of time. Through comprehensive experiments, we demonstrate that our RP can estimate when a new interest point is repeated, and also highlight an insightful analysis about this problem. For further comparison, we apply our RP to the map summarization under visual localization framework, which builds a compact representation of the full context map given the query time. The experimental result shows a careful selection of potentially repeatable interest points predicted by our RP can significantly mitigate the degeneration of localization accuracy from map summarization.
Single-Image Depth Prediction Makes Feature Matching Easier
Aug 21, 2020


Good local features improve the robustness of many 3D re-localization and multi-view reconstruction pipelines. The problem is that viewing angle and distance severely impact the recognizability of a local feature. Attempts to improve appearance invariance by choosing better local feature points or by leveraging outside information, have come with pre-requisites that made some of them impractical. In this paper, we propose a surprisingly effective enhancement to local feature extraction, which improves matching. We show that CNN-based depths inferred from single RGB images are quite helpful, despite their flaws. They allow us to pre-warp images and rectify perspective distortions, to significantly enhance SIFT and BRISK features, enabling more good matches, even when cameras are looking at the same scene but in opposite directions.
Learning Stereo from Single Images
Aug 20, 2020
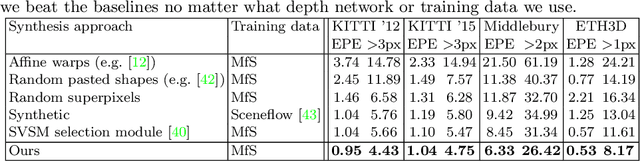
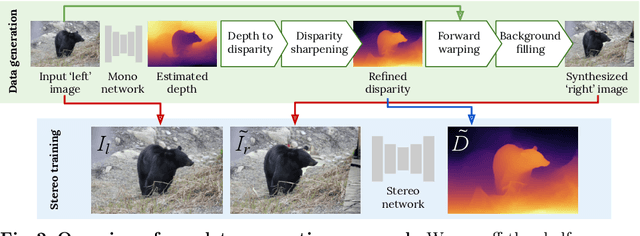

Supervised deep networks are among the best methods for finding correspondences in stereo image pairs. Like all supervised approaches, these networks require ground truth data during training. However, collecting large quantities of accurate dense correspondence data is very challenging. We propose that it is unnecessary to have such a high reliance on ground truth depths or even corresponding stereo pairs. Inspired by recent progress in monocular depth estimation, we generate plausible disparity maps from single images. In turn, we use those flawed disparity maps in a carefully designed pipeline to generate stereo training pairs. Training in this manner makes it possible to convert any collection of single RGB images into stereo training data. This results in a significant reduction in human effort, with no need to collect real depths or to hand-design synthetic data. We can consequently train a stereo matching network from scratch on datasets like COCO, which were previously hard to exploit for stereo. Through extensive experiments we show that our approach outperforms stereo networks trained with standard synthetic datasets, when evaluated on KITTI, ETH3D, and Middlebury.