 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Formation for the Cooperative Transportation of Arbitrary Objects Using Multi-Agent Reinforcement Learning
Jun 08, 2026Cooperative object transportation is essential in numerous domains, including industrial to domestic services. A popular transportation strategy is to carry objects on top of multi-robot systems. The corresponding task is typically solved by decomposing it into three interconnected subproblems: formation control, cooperative navigation, and collision avoidance. A particular challenge posed by real-world objects is their potentially arbitrary shape and non-uniform mass distribution, necessitating robot formations that securely support the object. In this work, we address the challenge of pattern formation control for transporting such real-world objects by proposing a novel multi-agent reinforcement learning approach. Our approach enables a multi-robot system to autonomously position itself underneath an object to support its weight while avoiding obstacles during the formation process. Our evaluations with diverse environments and varying numbers of robots show that our approach leads to policies that reliably produce balanced formations and generalize to cluttered scenes and objects with complex geometry and non-uniform mass distribution.
Cross-View Splatter: Feed-Forward View Synthesis with Georeferenced Images
May 19, 2026We present Cross-View Splatter, a feed-forward method that predicts pixel-aligned Gaussian splats for outdoor scenes captured at ground level AND by satellite. Faithful reconstructions require good camera coverage, but ground imagery is time-consuming and hard to capture at scale for large outdoor scenes. Fortunately, satellite imagery can provide a global geometric prior that is easy to access via public APIs. Cross-View Splatter fuses orthorectified satellite views with GPS-tagged ground photos to predict Gaussian splats in a unified 3D coordinate frame. By aligning ground and bird's-eye feature representations, our model improves scene coverage and novel-view synthesis, compared to ground imagery alone. We train on curated georeferenced datasets and paired satellite-terrain data, mined from open mapping services. We evaluate our method on a new benchmark for novel-view synthesis with georeferenced imagery allowing comparison to prior state-of-the-art methods. Our code and data preparation will be available at https://nianticspatial.github.io/cross-view-splatter/.
Complete Gaussian Splats from a Single Image with Denoising Diffusion Models
Aug 29, 2025Gaussian splatting typically requires dense observations of the scene and can fail to reconstruct occluded and unobserved areas. We propose a latent diffusion model to reconstruct a complete 3D scene with Gaussian splats, including the occluded parts, from only a single image during inference. Completing the unobserved surfaces of a scene is challenging due to the ambiguity of the plausible surfaces. Conventional methods use a regression-based formulation to predict a single "mode" for occluded and out-of-frustum surfaces, leading to blurriness, implausibility, and failure to capture multiple possible explanations. Thus, they often address this problem partially, focusing either on objects isolated from the background, reconstructing only visible surfaces, or failing to extrapolate far from the input views. In contrast, we propose a generative formulation to learn a distribution of 3D representations of Gaussian splats conditioned on a single input image. To address the lack of ground-truth training data, we propose a Variational AutoReconstructor to learn a latent space only from 2D images in a self-supervised manner, over which a diffusion model is trained. Our method generates faithful reconstructions and diverse samples with the ability to complete the occluded surfaces for high-quality 360-degree renderings.
MVSAnywhere: Zero-Shot Multi-View Stereo
Mar 28, 2025Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.
Morpheus: Text-Driven 3D Gaussian Splat Shape and Color Stylization
Mar 03, 2025
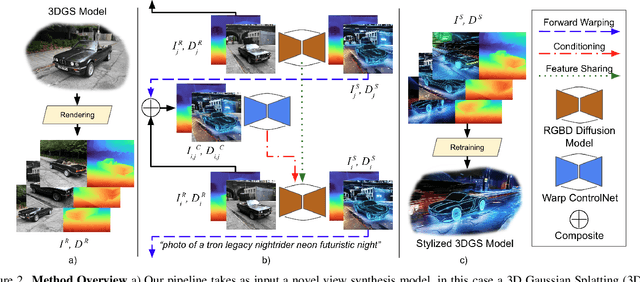
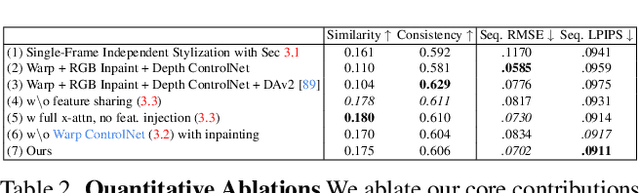
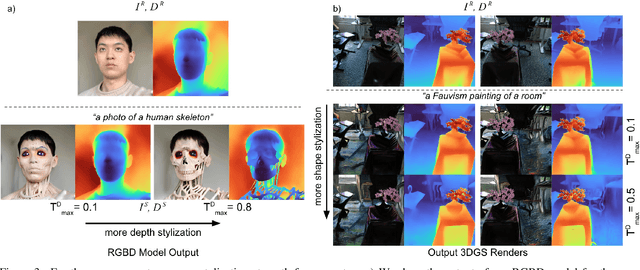
Exploring real-world spaces using novel-view synthesis is fun, and reimagining those worlds in a different style adds another layer of excitement. Stylized worlds can also be used for downstream tasks where there is limited training data and a need to expand a model's training distribution. Most current novel-view synthesis stylization techniques lack the ability to convincingly change geometry. This is because any geometry change requires increased style strength which is often capped for stylization stability and consistency. In this work, we propose a new autoregressive 3D Gaussian Splatting stylization method. As part of this method, we contribute a new RGBD diffusion model that allows for strength control over appearance and shape stylization. To ensure consistency across stylized frames, we use a combination of novel depth-guided cross attention, feature injection, and a Warp ControlNet conditioned on composite frames for guiding the stylization of new frames. We validate our method via extensive qualitative results, quantitative experiments, and a user study. Code will be released online.
GroundUp: Rapid Sketch-Based 3D City Massing
Jul 17, 2024



We propose GroundUp, the first sketch-based ideation tool for 3D city massing of urban areas. We focus on early-stage urban design, where sketching is a common tool and the design starts from balancing building volumes (masses) and open spaces. With Human-Centered AI in mind, we aim to help architects quickly revise their ideas by easily switching between 2D sketches and 3D models, allowing for smoother iteration and sharing of ideas. Inspired by feedback from architects and existing workflows, our system takes as a first input a user sketch of multiple buildings in a top-down view. The user then draws a perspective sketch of the envisioned site. Our method is designed to exploit the complementarity of information in the two sketches and allows users to quickly preview and adjust the inferred 3D shapes. Our model has two main components. First, we propose a novel sketch-to-depth prediction network for perspective sketches that exploits top-down sketch shapes. Second, we use depth cues derived from the perspective sketch as a condition to our diffusion model, which ultimately completes the geometry in a top-down view. Thus, our final 3D geometry is represented as a heightfield, allowing users to construct the city `from the ground up'.
DoubleTake: Geometry Guided Depth Estimation
Jun 26, 2024
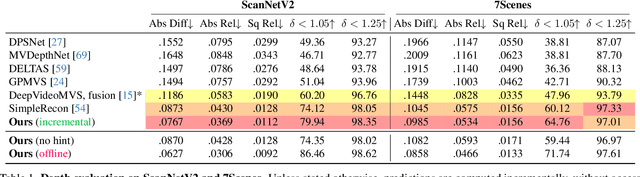
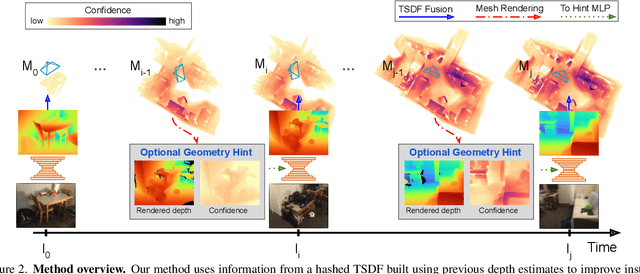
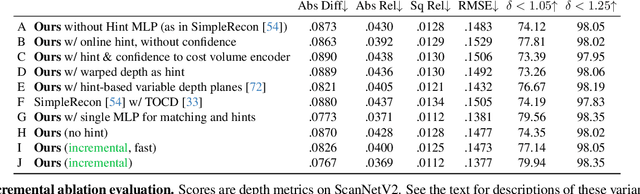
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
AirPlanes: Accurate Plane Estimation via 3D-Consistent Embeddings
Jun 13, 2024Extracting planes from a 3D scene is useful for downstream tasks in robotics and augmented reality. In this paper we tackle the problem of estimating the planar surfaces in a scene from posed images. Our first finding is that a surprisingly competitive baseline results from combining popular clustering algorithms with recent improvements in 3D geometry estimation. However, such purely geometric methods are understandably oblivious to plane semantics, which are crucial to discerning distinct planes. To overcome this limitation, we propose a method that predicts multi-view consistent plane embeddings that complement geometry when clustering points into planes. We show through extensive evaluation on the ScanNetV2 dataset that our new method outperforms existing approaches and our strong geometric baseline for the task of plane estimation.
MoveTouch: Robotic Motion Capturing System with Wearable Tactile Display to Achieve Safe HRI
May 08, 2024



The collaborative robot market is flourishing as there is a trend towards simplification, modularity, and increased flexibility on the production line. But when humans and robots are collaborating in a shared environment, the safety of humans should be a priority. We introduce a novel wearable robotic system to enhance safety during Human Robot Interaction (HRI). The proposed wearable robot is designed to hold a fiducial marker and maintain its visibility to the tracking system, which, in turn, localizes the user's hand with good accuracy and low latency and provides haptic feedback on the user's wrist. The haptic feedback guides the user's hand movement during collaborative tasks in order to increase safety and enhance collaboration efficiency. A user study was conducted to assess the recognition and discriminability of ten designed haptic patterns applied to the volar and dorsal parts of the user's wrist. As a result, four patterns with a high recognition rate were chosen to be incorporated into our system. A second experiment was carried out to evaluate the system integration into real-world collaborative tasks.
An Empirical Study of the Generalization Ability of Lidar 3D Object Detectors to Unseen Domains
Feb 27, 20243D Object Detectors (3D-OD) are crucial for understanding the environment in many robotic tasks, especially autonomous driving. Including 3D information via Lidar sensors improves accuracy greatly. However, such detectors perform poorly on domains they were not trained on, i.e. different locations, sensors, weather, etc., limiting their reliability in safety-critical applications. There exist methods to adapt 3D-ODs to these domains; however, these methods treat 3D-ODs as a black box, neglecting underlying architectural decisions and source-domain training strategies. Instead, we dive deep into the details of 3D-ODs, focusing our efforts on fundamental factors that influence robustness prior to domain adaptation. We systematically investigate four design choices (and the interplay between them) often overlooked in 3D-OD robustness and domain adaptation: architecture, voxel encoding, data augmentations, and anchor strategies. We assess their impact on the robustness of nine state-of-the-art 3D-ODs across six benchmarks encompassing three types of domain gaps - sensor type, weather, and location. Our main findings are: (1) transformer backbones with local point features are more robust than 3D CNNs, (2) test-time anchor size adjustment is crucial for adaptation across geographical locations, significantly boosting scores without retraining, (3) source-domain augmentations allow the model to generalize to low-resolution sensors, and (4) surprisingly, robustness to bad weather is improved when training directly on more clean weather data than on training with bad weather data. We outline our main conclusions and findings to provide practical guidance on developing more robust 3D-ODs.