 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Splatter: Feed-Forward View Synthesis with Georeferenced Images
May 19, 2026We present Cross-View Splatter, a feed-forward method that predicts pixel-aligned Gaussian splats for outdoor scenes captured at ground level AND by satellite. Faithful reconstructions require good camera coverage, but ground imagery is time-consuming and hard to capture at scale for large outdoor scenes. Fortunately, satellite imagery can provide a global geometric prior that is easy to access via public APIs. Cross-View Splatter fuses orthorectified satellite views with GPS-tagged ground photos to predict Gaussian splats in a unified 3D coordinate frame. By aligning ground and bird's-eye feature representations, our model improves scene coverage and novel-view synthesis, compared to ground imagery alone. We train on curated georeferenced datasets and paired satellite-terrain data, mined from open mapping services. We evaluate our method on a new benchmark for novel-view synthesis with georeferenced imagery allowing comparison to prior state-of-the-art methods. Our code and data preparation will be available at https://nianticspatial.github.io/cross-view-splatter/.
PlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
May 08, 2025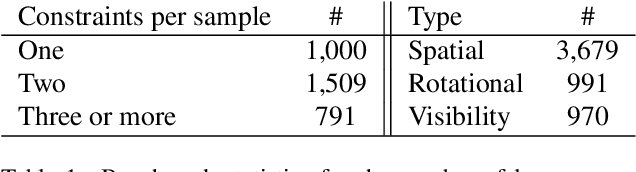
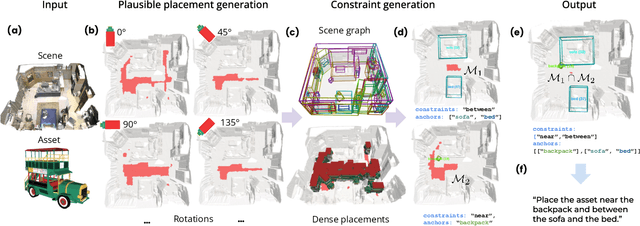
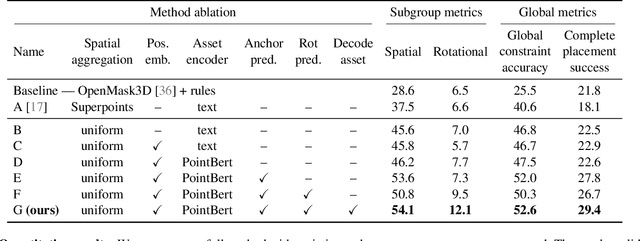
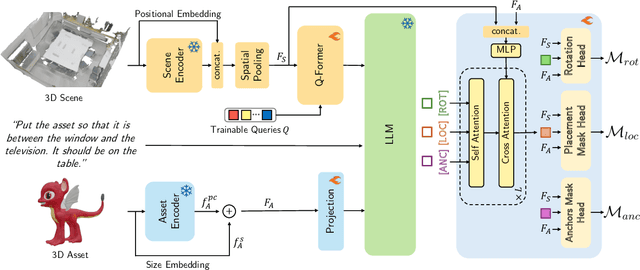
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.
DoubleTake: Geometry Guided Depth Estimation
Jun 26, 2024
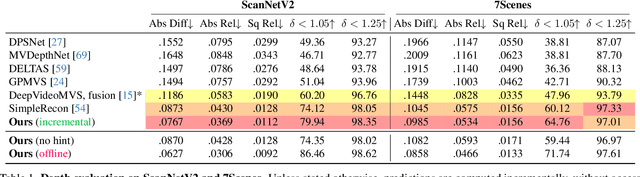
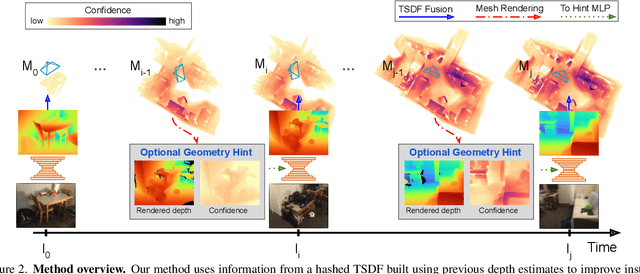
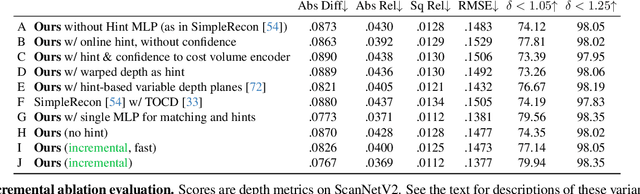
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
AirPlanes: Accurate Plane Estimation via 3D-Consistent Embeddings
Jun 13, 2024Extracting planes from a 3D scene is useful for downstream tasks in robotics and augmented reality. In this paper we tackle the problem of estimating the planar surfaces in a scene from posed images. Our first finding is that a surprisingly competitive baseline results from combining popular clustering algorithms with recent improvements in 3D geometry estimation. However, such purely geometric methods are understandably oblivious to plane semantics, which are crucial to discerning distinct planes. To overcome this limitation, we propose a method that predicts multi-view consistent plane embeddings that complement geometry when clustering points into planes. We show through extensive evaluation on the ScanNetV2 dataset that our new method outperforms existing approaches and our strong geometric baseline for the task of plane estimation.
Unsupervised confidence for LiDAR depth maps and applications
Oct 06, 2022
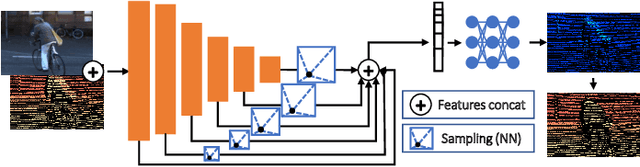

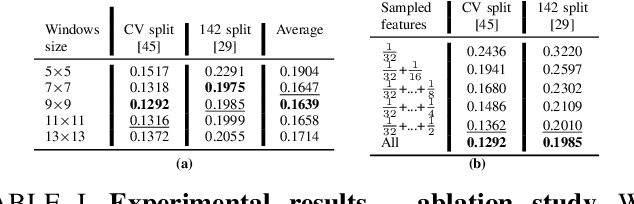
Depth perception is pivotal in many fields, such as robotics and autonomous driving, to name a few. Consequently, depth sensors such as LiDARs rapidly spread in many applications. The 3D point clouds generated by these sensors must often be coupled with an RGB camera to understand the framed scene semantically. Usually, the former is projected over the camera image plane, leading to a sparse depth map. Unfortunately, this process, coupled with the intrinsic issues affecting all the depth sensors, yields noise and gross outliers in the final output. Purposely, in this paper, we propose an effective unsupervised framework aimed at explicitly addressing this issue by learning to estimate the confidence of the LiDAR sparse depth map and thus allowing for filtering out the outliers. Experimental results on the KITTI dataset highlight that our framework excels for this purpose. Moreover, we demonstrate how this achievement can improve a wide range of tasks.
Monitoring social distancing with single image depth estimation
Apr 04, 2022
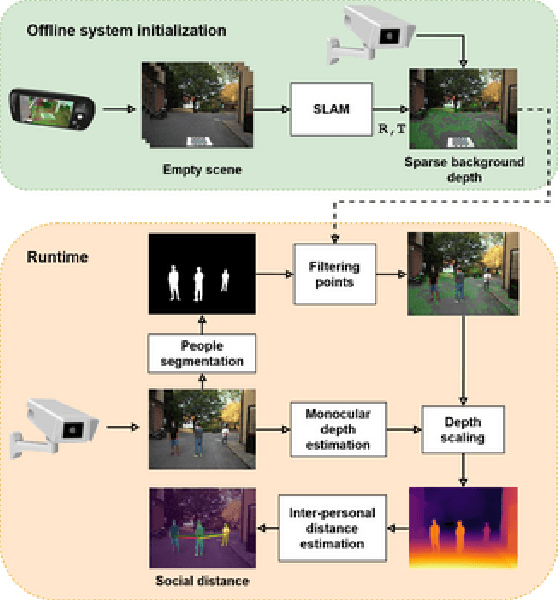
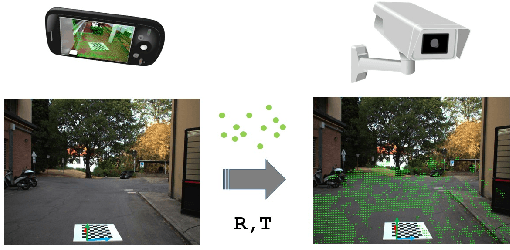

The recent pandemic emergency raised many challenges regarding the countermeasures aimed at containing the virus spread, and constraining the minimum distance between people resulted in one of the most effective strategies. Thus, the implementation of autonomous systems capable of monitoring the so-called social distance gained much interest. In this paper, we aim to address this task leveraging a single RGB frame without additional depth sensors. In contrast to existing single-image alternatives failing when ground localization is not available, we rely on single image depth estimation to perceive the 3D structure of the observed scene and estimate the distance between people. During the setup phase, a straightforward calibration procedure, leveraging a scale-aware SLAM algorithm available even on consumer smartphones, allows us to address the scale ambiguity affecting single image depth estimation. We validate our approach through indoor and outdoor images employing a calibrated LiDAR + RGB camera asset. Experimental results highlight that our proposal enables sufficiently reliable estimation of the inter-personal distance to monitor social distancing effectively. This fact confirms that despite its intrinsic ambiguity, if appropriately driven single image depth estimation can be a viable alternative to other depth perception techniques, more expensive and not always feasible in practical applications. Our evaluation also highlights that our framework can run reasonably fast and comparably to competitors, even on pure CPU systems. Moreover, its practical deployment on low-power systems is around the corner.
Neural Disparity Refinement for Arbitrary Resolution Stereo
Oct 28, 2021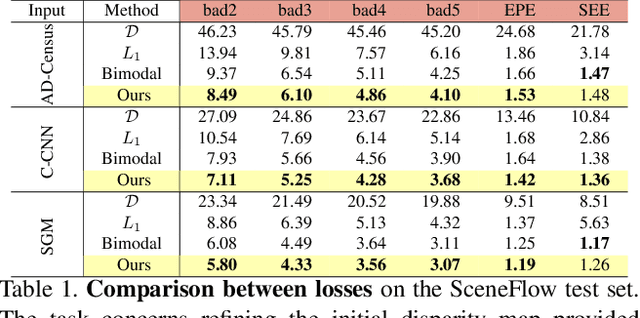

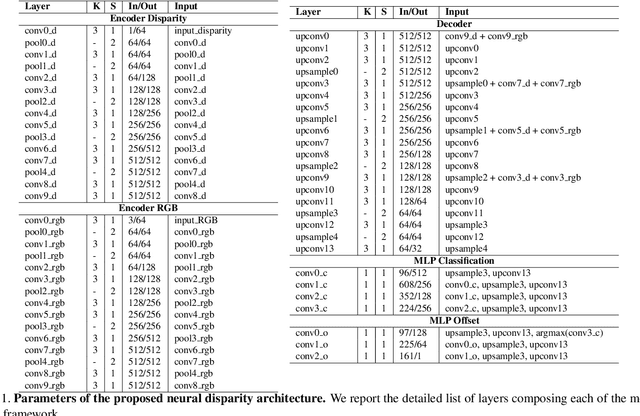
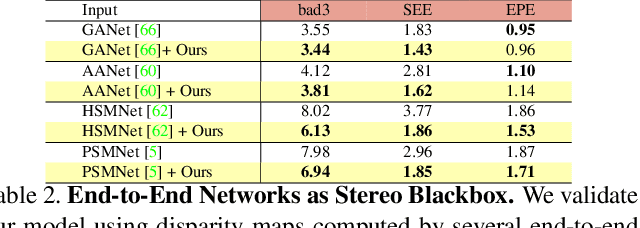
We introduce a novel architecture for neural disparity refinement aimed at facilitating deployment of 3D computer vision on cheap and widespread consumer devices, such as mobile phones. Our approach relies on a continuous formulation that enables to estimate a refined disparity map at any arbitrary output resolution. Thereby, it can handle effectively the unbalanced camera setup typical of nowadays mobile phones, which feature both high and low resolution RGB sensors within the same device. Moreover, our neural network can process seamlessly the output of a variety of stereo methods and, by refining the disparity maps computed by a traditional matching algorithm like SGM, it can achieve unpaired zero-shot generalization performance compared to state-of-the-art end-to-end stereo models.
Sensor-Guided Optical Flow
Sep 30, 2021
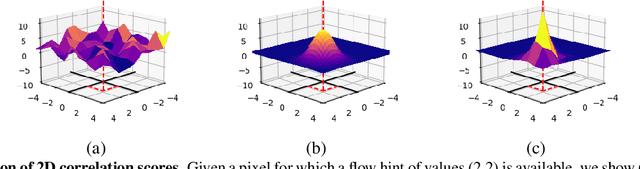
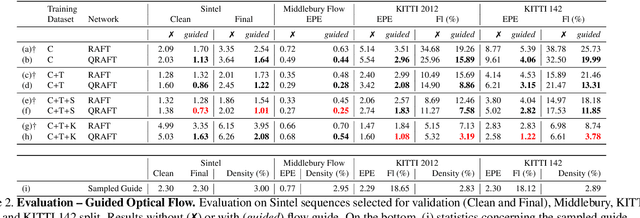
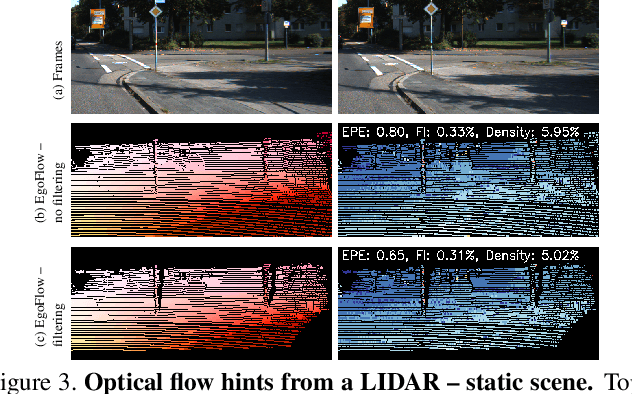
This paper proposes a framework to guide an optical flow network with external cues to achieve superior accuracy either on known or unseen domains. Given the availability of sparse yet accurate optical flow hints from an external source, these are injected to modulate the correlation scores computed by a state-of-the-art optical flow network and guide it towards more accurate predictions. Although no real sensor can provide sparse flow hints, we show how these can be obtained by combining depth measurements from active sensors with geometry and hand-crafted optical flow algorithms, leading to accurate enough hints for our purpose. Experimental results with a state-of-the-art flow network on standard benchmarks support the effectiveness of our framework, both in simulated and real conditions.
Learning optical flow from still images
Apr 08, 2021
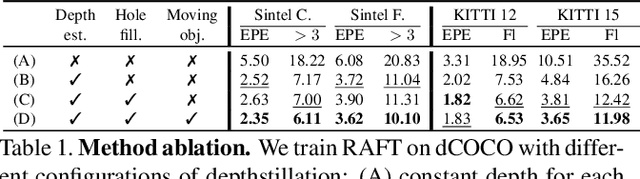
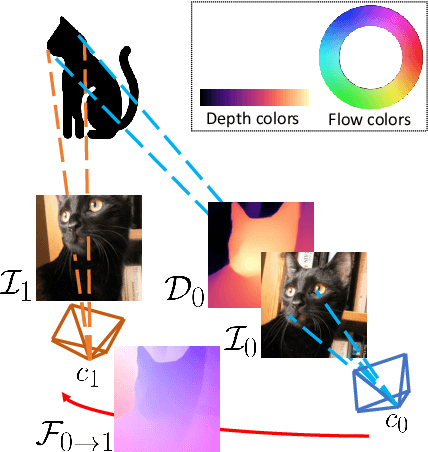
This paper deals with the scarcity of data for training optical flow networks, highlighting the limitations of existing sources such as labeled synthetic datasets or unlabeled real videos. Specifically, we introduce a framework to generate accurate ground-truth optical flow annotations quickly and in large amounts from any readily available single real picture. Given an image, we use an off-the-shelf monocular depth estimation network to build a plausible point cloud for the observed scene. Then, we virtually move the camera in the reconstructed environment with known motion vectors and rotation angles, allowing us to synthesize both a novel view and the corresponding optical flow field connecting each pixel in the input image to the one in the new frame. When trained with our data, state-of-the-art optical flow networks achieve superior generalization to unseen real data compared to the same models trained either on annotated synthetic datasets or unlabeled videos, and better specialization if combined with synthetic images.
On the confidence of stereo matching in a deep-learning era: a quantitative evaluation
Jan 02, 2021
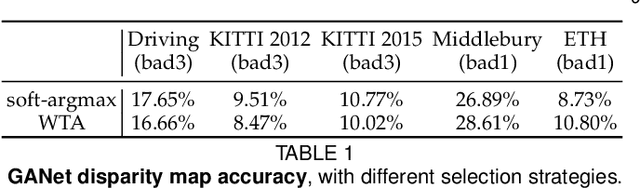
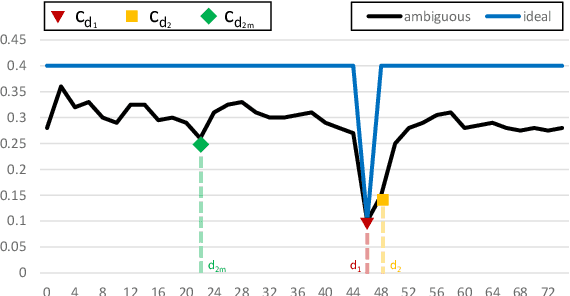
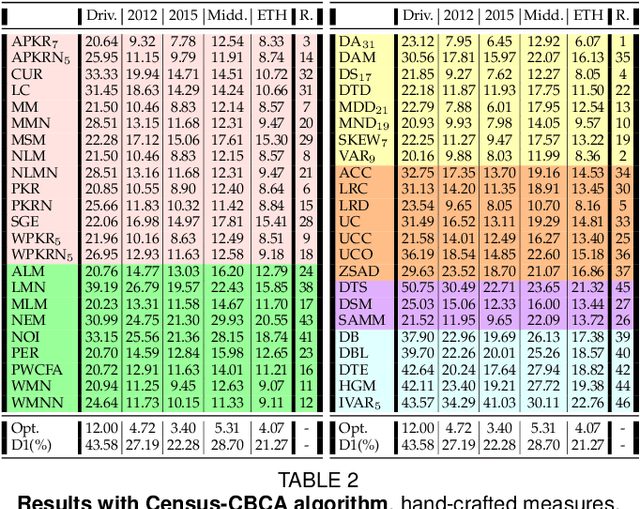
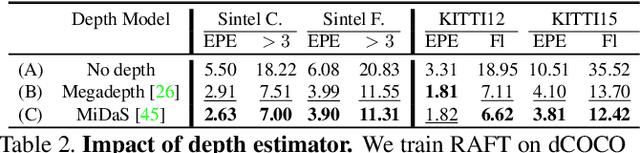
Stereo matching is one of the most popular techniques to estimate dense depth maps by finding the disparity between matching pixels on two, synchronized and rectified images. Alongside with the development of more accurate algorithms, the research community focused on finding good strategies to estimate the reliability, i.e. the confidence, of estimated disparity maps. This information proves to be a powerful cue to naively find wrong matches as well as to improve the overall effectiveness of a variety of stereo algorithms according to different strategies. In this paper, we review more than ten years of developments in the field of confidence estimation for stereo matching. We extensively discuss and evaluate existing confidence measures and their variants, from hand-crafted ones to the most recent, state-of-the-art learning based methods. We study the different behaviors of each measure when applied to a pool of different stereo algorithms and, for the first time in literature, when paired with a state-of-the-art deep stereo network. Our experiments, carried out on five different standard datasets, provide a comprehensive overview of the field, highlighting in particular both strengths and limitations of learning-based strategies.