 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToF-Splatting: Dense SLAM using Sparse Time-of-Flight Depth and Multi-Frame Integration
Apr 23, 2025Time-of-Flight (ToF) sensors provide efficient active depth sensing at relatively low power budgets; among such designs, only very sparse measurements from low-resolution sensors are considered to meet the increasingly limited power constraints of mobile and AR/VR devices. However, such extreme sparsity levels limit the seamless usage of ToF depth in SLAM. In this work, we propose ToF-Splatting, the first 3D Gaussian Splatting-based SLAM pipeline tailored for using effectively very sparse ToF input data. Our approach improves upon the state of the art by introducing a multi-frame integration module, which produces dense depth maps by merging cues from extremely sparse ToF depth, monocular color, and multi-view geometry. Extensive experiments on both synthetic and real sparse ToF datasets demonstrate the viability of our approach, as it achieves state-of-the-art tracking and mapping performances on reference datasets.
Depth on Demand: Streaming Dense Depth from a Low Frame Rate Active Sensor
Sep 12, 2024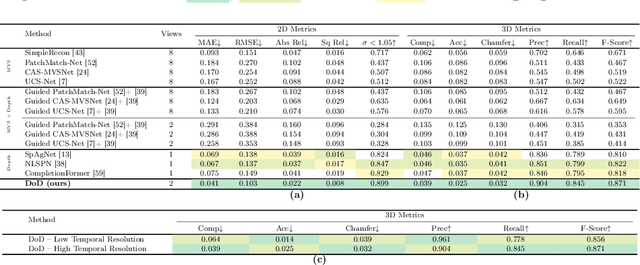

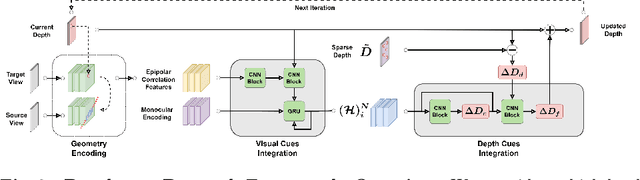

High frame rate and accurate depth estimation plays an important role in several tasks crucial to robotics and automotive perception. To date, this can be achieved through ToF and LiDAR devices for indoor and outdoor applications, respectively. However, their applicability is limited by low frame rate, energy consumption, and spatial sparsity. Depth on Demand (DoD) allows for accurate temporal and spatial depth densification achieved by exploiting a high frame rate RGB sensor coupled with a potentially lower frame rate and sparse active depth sensor. Our proposal jointly enables lower energy consumption and denser shape reconstruction, by significantly reducing the streaming requirements on the depth sensor thanks to its three core stages: i) multi-modal encoding, ii) iterative multi-modal integration, and iii) depth decoding. We present extended evidence assessing the effectiveness of DoD on indoor and outdoor video datasets, covering both environment scanning and automotive perception use cases.
LiDAR-Event Stereo Fusion with Hallucinations
Aug 08, 2024Event stereo matching is an emerging technique to estimate depth from neuromorphic cameras; however, events are unlikely to trigger in the absence of motion or the presence of large, untextured regions, making the correspondence problem extremely challenging. Purposely, we propose integrating a stereo event camera with a fixed-frequency active sensor -- e.g., a LiDAR -- collecting sparse depth measurements, overcoming the aforementioned limitations. Such depth hints are used by hallucinating -- i.e., inserting fictitious events -- the stacks or raw input streams, compensating for the lack of information in the absence of brightness changes. Our techniques are general, can be adapted to any structured representation to stack events and outperform state-of-the-art fusion methods applied to event-based stereo.
Stereo-Depth Fusion through Virtual Pattern Projection
Jun 06, 2024This paper presents a novel general-purpose stereo and depth data fusion paradigm that mimics the active stereo principle by replacing the unreliable physical pattern projector with a depth sensor. It works by projecting virtual patterns consistent with the scene geometry onto the left and right images acquired by a conventional stereo camera, using the sparse hints obtained from a depth sensor, to facilitate the visual correspondence. Purposely, any depth sensing device can be seamlessly plugged into our framework, enabling the deployment of a virtual active stereo setup in any possible environment and overcoming the severe limitations of physical pattern projection, such as the limited working range and environmental conditions. Exhaustive experiments on indoor and outdoor datasets featuring both long and close range, including those providing raw, unfiltered depth hints from off-the-shelf depth sensors, highlight the effectiveness of our approach in notably boosting the robustness and accuracy of algorithms and deep stereo without any code modification and even without re-training. Additionally, we assess the performance of our strategy on active stereo evaluation datasets with conventional pattern projection. Indeed, in all these scenarios, our virtual pattern projection paradigm achieves state-of-the-art performance. The source code is available at: https://github.com/bartn8/vppstereo.
Range-Agnostic Multi-View Depth Estimation With Keyframe Selection
Jan 25, 2024Methods for 3D reconstruction from posed frames require prior knowledge about the scene metric range, usually to recover matching cues along the epipolar lines and narrow the search range. However, such prior might not be directly available or estimated inaccurately in real scenarios -- e.g., outdoor 3D reconstruction from video sequences -- therefore heavily hampering performance. In this paper, we focus on multi-view depth estimation without requiring prior knowledge about the metric range of the scene by proposing RAMDepth, an efficient and purely 2D framework that reverses the depth estimation and matching steps order. Moreover, we demonstrate the capability of our framework to provide rich insights about the quality of the views used for prediction. Additional material can be found on our project page https://andreaconti.github.io/projects/range_agnostic_multi_view_depth.
Revisiting Depth Completion from a Stereo Matching Perspective for Cross-domain Generalization
Dec 14, 2023



This paper proposes a new framework for depth completion robust against domain-shifting issues. It exploits the generalization capability of modern stereo networks to face depth completion, by processing fictitious stereo pairs obtained through a virtual pattern projection paradigm. Any stereo network or traditional stereo matcher can be seamlessly plugged into our framework, allowing for the deployment of a virtual stereo setup that is future-proof against advancement in the stereo field. Exhaustive experiments on cross-domain generalization support our claims. Hence, we argue that our framework can help depth completion to reach new deployment scenarios.
Active Stereo Without Pattern Projector
Sep 21, 2023



This paper proposes a novel framework integrating the principles of active stereo in standard passive camera systems without a physical pattern projector. We virtually project a pattern over the left and right images according to the sparse measurements obtained from a depth sensor. Any such devices can be seamlessly plugged into our framework, allowing for the deployment of a virtual active stereo setup in any possible environment, overcoming the limitation of pattern projectors, such as limited working range or environmental conditions. Experiments on indoor/outdoor datasets, featuring both long and close-range, support the seamless effectiveness of our approach, boosting the accuracy of both stereo algorithms and deep networks.
Sparsity Agnostic Depth Completion
Dec 01, 2022



We present a novel depth completion approach agnostic to the sparsity of depth points, that is very likely to vary in many practical applications. State-of-the-art approaches yield accurate results only when processing a specific density and distribution of input points, i.e. the one observed during training, narrowing their deployment in real use cases. On the contrary, our solution is robust to uneven distributions and extremely low densities never witnessed during training. Experimental results on standard indoor and outdoor benchmarks highlight the robustness of our framework, achieving accuracy comparable to state-of-the-art methods when tested with density and distribution equal to the training one while being much more accurate in the other cases. Our pretrained models and further material are available in our project page.
Multi-View Guided Multi-View Stereo
Oct 20, 2022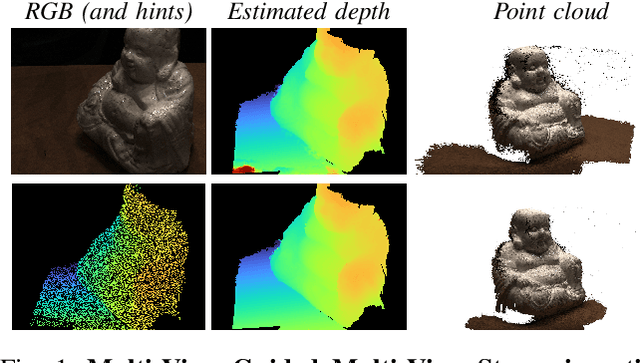
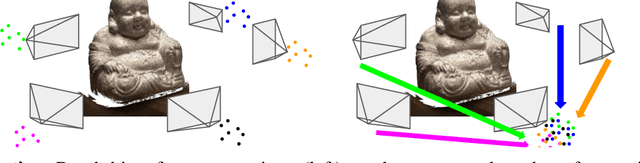


This paper introduces a novel deep framework for dense 3D reconstruction from multiple image frames, leveraging a sparse set of depth measurements gathered jointly with image acquisition. Given a deep multi-view stereo network, our framework uses sparse depth hints to guide the neural network by modulating the plane-sweep cost volume built during the forward step, enabling us to infer constantly much more accurate depth maps. Moreover, since multiple viewpoints can provide additional depth measurements, we propose a multi-view guidance strategy that increases the density of the sparse points used to guide the network, thus leading to even more accurate results. We evaluate our Multi-View Guided framework within a variety of state-of-the-art deep multi-view stereo networks, demonstrating its effectiveness at improving the results achieved by each of them on BlendedMVG and DTU datasets.
Unsupervised confidence for LiDAR depth maps and applications
Oct 06, 2022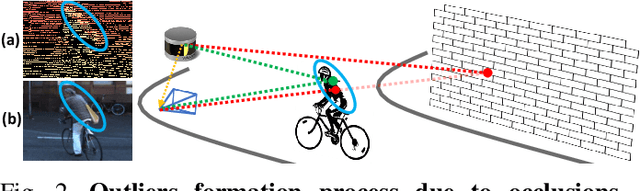
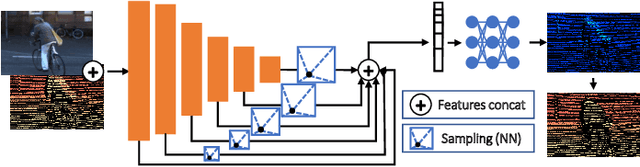

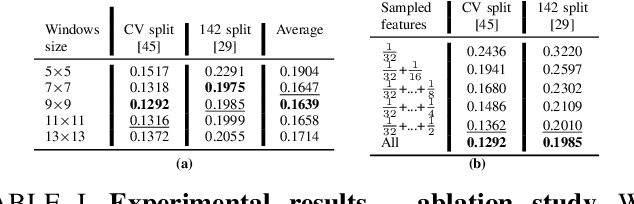
Depth perception is pivotal in many fields, such as robotics and autonomous driving, to name a few. Consequently, depth sensors such as LiDARs rapidly spread in many applications. The 3D point clouds generated by these sensors must often be coupled with an RGB camera to understand the framed scene semantically. Usually, the former is projected over the camera image plane, leading to a sparse depth map. Unfortunately, this process, coupled with the intrinsic issues affecting all the depth sensors, yields noise and gross outliers in the final output. Purposely, in this paper, we propose an effective unsupervised framework aimed at explicitly addressing this issue by learning to estimate the confidence of the LiDAR sparse depth map and thus allowing for filtering out the outliers. Experimental results on the KITTI dataset highlight that our framework excels for this purpose. Moreover, we demonstrate how this achievement can improve a wide range of tasks.