 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToF-Splatting: Dense SLAM using Sparse Time-of-Flight Depth and Multi-Frame Integration
Apr 23, 2025Time-of-Flight (ToF) sensors provide efficient active depth sensing at relatively low power budgets; among such designs, only very sparse measurements from low-resolution sensors are considered to meet the increasingly limited power constraints of mobile and AR/VR devices. However, such extreme sparsity levels limit the seamless usage of ToF depth in SLAM. In this work, we propose ToF-Splatting, the first 3D Gaussian Splatting-based SLAM pipeline tailored for using effectively very sparse ToF input data. Our approach improves upon the state of the art by introducing a multi-frame integration module, which produces dense depth maps by merging cues from extremely sparse ToF depth, monocular color, and multi-view geometry. Extensive experiments on both synthetic and real sparse ToF datasets demonstrate the viability of our approach, as it achieves state-of-the-art tracking and mapping performances on reference datasets.
Depth on Demand: Streaming Dense Depth from a Low Frame Rate Active Sensor
Sep 12, 2024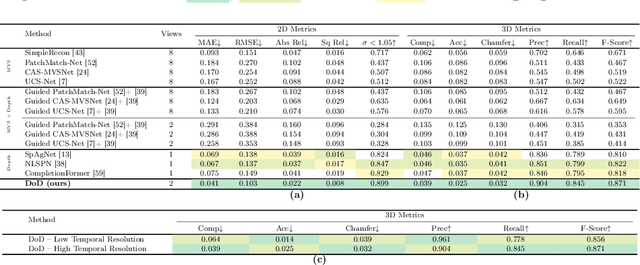

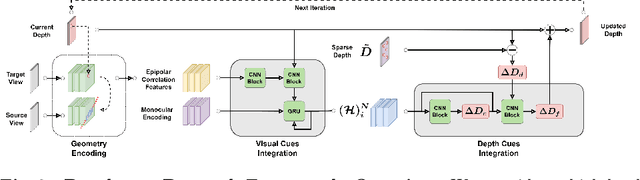

High frame rate and accurate depth estimation plays an important role in several tasks crucial to robotics and automotive perception. To date, this can be achieved through ToF and LiDAR devices for indoor and outdoor applications, respectively. However, their applicability is limited by low frame rate, energy consumption, and spatial sparsity. Depth on Demand (DoD) allows for accurate temporal and spatial depth densification achieved by exploiting a high frame rate RGB sensor coupled with a potentially lower frame rate and sparse active depth sensor. Our proposal jointly enables lower energy consumption and denser shape reconstruction, by significantly reducing the streaming requirements on the depth sensor thanks to its three core stages: i) multi-modal encoding, ii) iterative multi-modal integration, and iii) depth decoding. We present extended evidence assessing the effectiveness of DoD on indoor and outdoor video datasets, covering both environment scanning and automotive perception use cases.
Range-Agnostic Multi-View Depth Estimation With Keyframe Selection
Jan 25, 2024Methods for 3D reconstruction from posed frames require prior knowledge about the scene metric range, usually to recover matching cues along the epipolar lines and narrow the search range. However, such prior might not be directly available or estimated inaccurately in real scenarios -- e.g., outdoor 3D reconstruction from video sequences -- therefore heavily hampering performance. In this paper, we focus on multi-view depth estimation without requiring prior knowledge about the metric range of the scene by proposing RAMDepth, an efficient and purely 2D framework that reverses the depth estimation and matching steps order. Moreover, we demonstrate the capability of our framework to provide rich insights about the quality of the views used for prediction. Additional material can be found on our project page https://andreaconti.github.io/projects/range_agnostic_multi_view_depth.
A Low Memory Footprint Quantized Neural Network for Depth Completion of Very Sparse Time-of-Flight Depth Maps
May 25, 2022
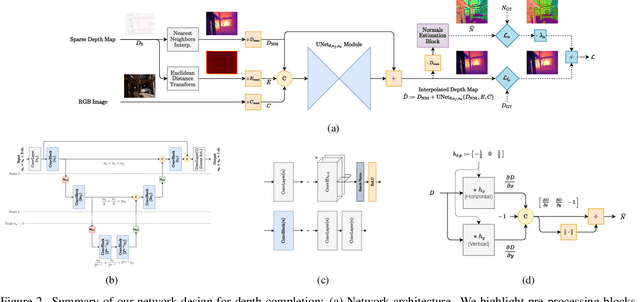
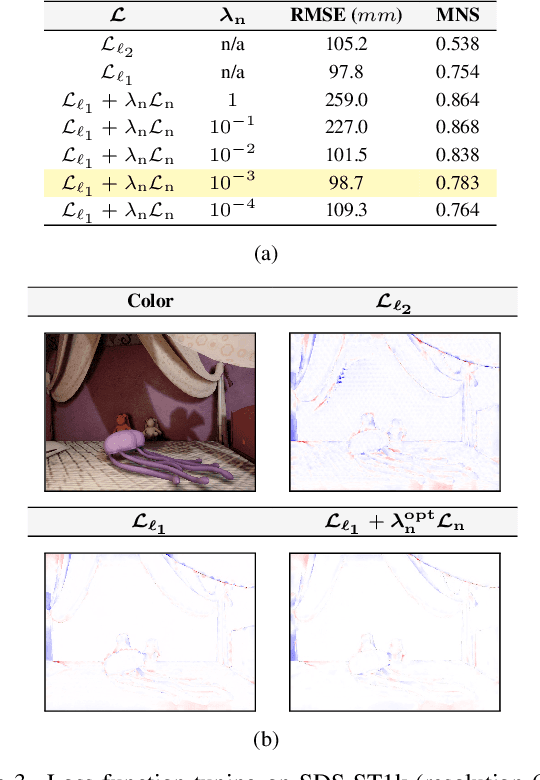
Sparse active illumination enables precise time-of-flight depth sensing as it maximizes signal-to-noise ratio for low power budgets. However, depth completion is required to produce dense depth maps for 3D perception. We address this task with realistic illumination and sensor resolution constraints by simulating ToF datasets for indoor 3D perception with challenging sparsity levels. We propose a quantized convolutional encoder-decoder network for this task. Our model achieves optimal depth map quality by means of input pre-processing and carefully tuned training with a geometry-preserving loss function. We also achieve low memory footprint for weights and activations by means of mixed precision quantization-at-training techniques. The resulting quantized models are comparable to the state of the art in terms of quality, but they require very low GPU times and achieve up to 14-fold memory size reduction for the weights w.r.t. their floating point counterpart with minimal impact on quality metrics.
Multispectral Compressive Imaging Strategies using Fabry-Pérot Filtered Sensors
Feb 06, 2018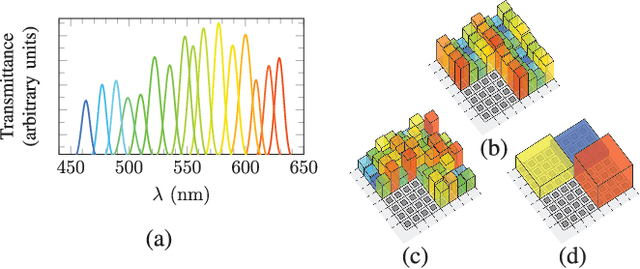
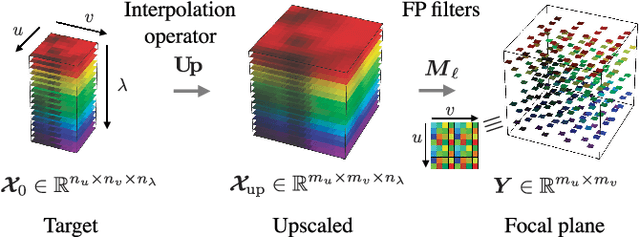
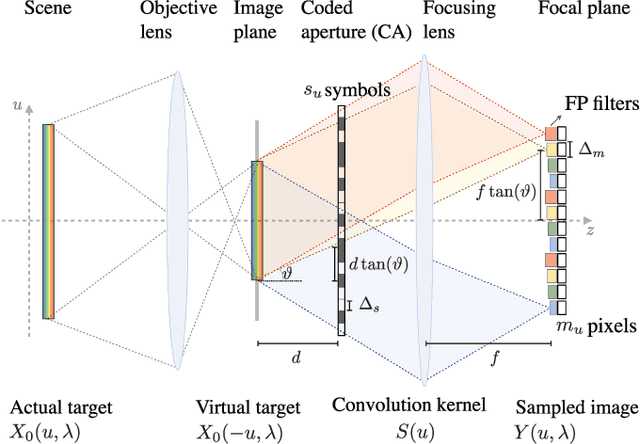

This paper introduces two acquisition device architectures for multispectral compressive imaging. Unlike most existing methods, the proposed computational imaging techniques do not include any dispersive element, as they use a dedicated sensor which integrates narrowband Fabry-P\'erot spectral filters at the pixel level. The first scheme leverages joint inpainting and super-resolution to fill in those voxels that are missing due to the device's limited pixel count. The second scheme, in link with compressed sensing, introduces spatial random convolutions, but is more complex and may be affected by diffraction. In both cases we solve the associated inverse problems by using the same signal prior. Specifically, we propose a redundant analysis signal prior in a convex formulation. Through numerical simulations, we explore different realistic setups. Our objective is also to highlight some practical guidelines and discuss their complexity trade-offs to integrate these schemes into actual computational imaging systems. Our conclusion is that the second technique performs best at high compression levels, in a properly sized and calibrated setup. Otherwise, the first, simpler technique should be favored.