 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth AnyEvent: A Cross-Modal Distillation Paradigm for Event-Based Monocular Depth Estimation
Sep 18, 2025Event cameras capture sparse, high-temporal-resolution visual information, making them particularly suitable for challenging environments with high-speed motion and strongly varying lighting conditions. However, the lack of large datasets with dense ground-truth depth annotations hinders learning-based monocular depth estimation from event data. To address this limitation, we propose a cross-modal distillation paradigm to generate dense proxy labels leveraging a Vision Foundation Model (VFM). Our strategy requires an event stream spatially aligned with RGB frames, a simple setup even available off-the-shelf, and exploits the robustness of large-scale VFMs. Additionally, we propose to adapt VFMs, either a vanilla one like Depth Anything v2 (DAv2), or deriving from it a novel recurrent architecture to infer depth from monocular event cameras. We evaluate our approach with synthetic and real-world datasets, demonstrating that i) our cross-modal paradigm achieves competitive performance compared to fully supervised methods without requiring expensive depth annotations, and ii) our VFM-based models achieve state-of-the-art performance.
Stereo Anywhere: Robust Zero-Shot Deep Stereo Matching Even Where Either Stereo or Mono Fail
Dec 05, 2024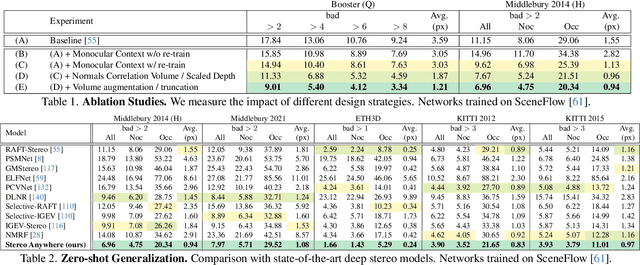
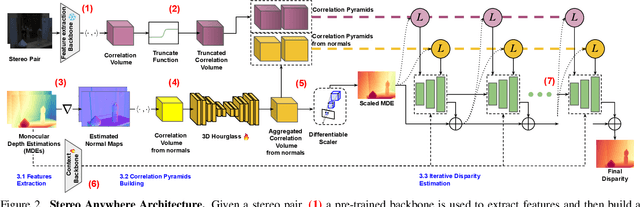

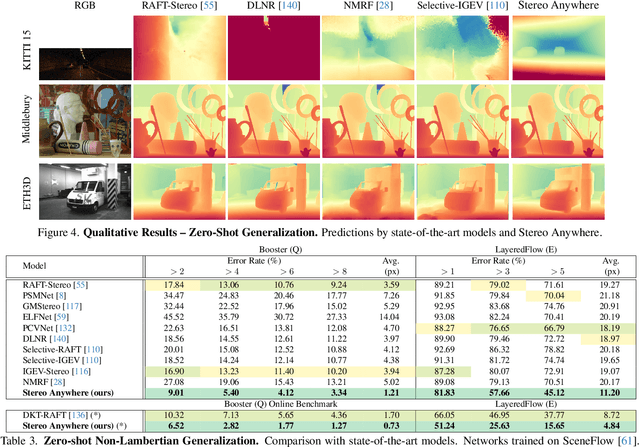
We introduce Stereo Anywhere, a novel stereo-matching framework that combines geometric constraints with robust priors from monocular depth Vision Foundation Models (VFMs). By elegantly coupling these complementary worlds through a dual-branch architecture, we seamlessly integrate stereo matching with learned contextual cues. Following this design, our framework introduces novel cost volume fusion mechanisms that effectively handle critical challenges such as textureless regions, occlusions, and non-Lambertian surfaces. Through our novel optical illusion dataset, MonoTrap, and extensive evaluation across multiple benchmarks, we demonstrate that our synthetic-only trained model achieves state-of-the-art results in zero-shot generalization, significantly outperforming existing solutions while showing remarkable robustness to challenging cases such as mirrors and transparencies.
LiDAR-Event Stereo Fusion with Hallucinations
Aug 08, 2024Event stereo matching is an emerging technique to estimate depth from neuromorphic cameras; however, events are unlikely to trigger in the absence of motion or the presence of large, untextured regions, making the correspondence problem extremely challenging. Purposely, we propose integrating a stereo event camera with a fixed-frequency active sensor -- e.g., a LiDAR -- collecting sparse depth measurements, overcoming the aforementioned limitations. Such depth hints are used by hallucinating -- i.e., inserting fictitious events -- the stacks or raw input streams, compensating for the lack of information in the absence of brightness changes. Our techniques are general, can be adapted to any structured representation to stack events and outperform state-of-the-art fusion methods applied to event-based stereo.
A Survey on Deep Stereo Matching in the Twenties
Jul 10, 2024



Stereo matching is close to hitting a half-century of history, yet witnessed a rapid evolution in the last decade thanks to deep learning. While previous surveys in the late 2010s covered the first stage of this revolution, the last five years of research brought further ground-breaking advancements to the field. This paper aims to fill this gap in a two-fold manner: first, we offer an in-depth examination of the latest developments in deep stereo matching, focusing on the pioneering architectural designs and groundbreaking paradigms that have redefined the field in the 2020s; second, we present a thorough analysis of the critical challenges that have emerged alongside these advances, providing a comprehensive taxonomy of these issues and exploring the state-of-the-art techniques proposed to address them. By reviewing both the architectural innovations and the key challenges, we offer a holistic view of deep stereo matching and highlight the specific areas that require further investigation. To accompany this survey, we maintain a regularly updated project page that catalogs papers on deep stereo matching in our Awesome-Deep-Stereo-Matching (https://github.com/fabiotosi92/Awesome-Deep-Stereo-Matching) repository.
Stereo-Depth Fusion through Virtual Pattern Projection
Jun 06, 2024This paper presents a novel general-purpose stereo and depth data fusion paradigm that mimics the active stereo principle by replacing the unreliable physical pattern projector with a depth sensor. It works by projecting virtual patterns consistent with the scene geometry onto the left and right images acquired by a conventional stereo camera, using the sparse hints obtained from a depth sensor, to facilitate the visual correspondence. Purposely, any depth sensing device can be seamlessly plugged into our framework, enabling the deployment of a virtual active stereo setup in any possible environment and overcoming the severe limitations of physical pattern projection, such as the limited working range and environmental conditions. Exhaustive experiments on indoor and outdoor datasets featuring both long and close range, including those providing raw, unfiltered depth hints from off-the-shelf depth sensors, highlight the effectiveness of our approach in notably boosting the robustness and accuracy of algorithms and deep stereo without any code modification and even without re-training. Additionally, we assess the performance of our strategy on active stereo evaluation datasets with conventional pattern projection. Indeed, in all these scenarios, our virtual pattern projection paradigm achieves state-of-the-art performance. The source code is available at: https://github.com/bartn8/vppstereo.
Revisiting Depth Completion from a Stereo Matching Perspective for Cross-domain Generalization
Dec 14, 2023This paper proposes a new framework for depth completion robust against domain-shifting issues. It exploits the generalization capability of modern stereo networks to face depth completion, by processing fictitious stereo pairs obtained through a virtual pattern projection paradigm. Any stereo network or traditional stereo matcher can be seamlessly plugged into our framework, allowing for the deployment of a virtual stereo setup that is future-proof against advancement in the stereo field. Exhaustive experiments on cross-domain generalization support our claims. Hence, we argue that our framework can help depth completion to reach new deployment scenarios.
Active Stereo Without Pattern Projector
Sep 21, 2023This paper proposes a novel framework integrating the principles of active stereo in standard passive camera systems without a physical pattern projector. We virtually project a pattern over the left and right images according to the sparse measurements obtained from a depth sensor. Any such devices can be seamlessly plugged into our framework, allowing for the deployment of a virtual active stereo setup in any possible environment, overcoming the limitation of pattern projectors, such as limited working range or environmental conditions. Experiments on indoor/outdoor datasets, featuring both long and close-range, support the seamless effectiveness of our approach, boosting the accuracy of both stereo algorithms and deep networks.
Towards Multi-robot Exploration: A Decentralized Strategy for UAV Forest Exploration
Jan 20, 2023Efficient exploration strategies are vital in tasks such as search-and-rescue missions and disaster surveying. Unmanned Aerial Vehicles (UAVs) have become particularly popular in such applications, promising to cover large areas at high speeds. Moreover, with the increasing maturity of onboard UAV perception, research focus has been shifting toward higher-level reasoning for single- and multi-robot missions. However, autonomous navigation and exploration of previously unknown large spaces still constitutes an open challenge, especially when the environment is cluttered and exhibits large and frequent occlusions due to high obstacle density, as is the case of forests. Moreover, the problem of long-distance wireless communication in such scenes can become a limiting factor, especially when automating the navigation of a UAV swarm. In this spirit, this work proposes an exploration strategy that enables UAVs, both individually and in small swarms, to quickly explore complex scenes in a decentralized fashion. By providing the decision-making capabilities to each UAV to switch between different execution modes, the proposed strategy strikes a great balance between cautious exploration of yet completely unknown regions and more aggressive exploration of smaller areas of unknown space. This results in full coverage of forest areas of variable density, consistently faster than the state of the art. Demonstrating successful deployment with a single UAV as well as a swarm of up to three UAVs, this work sets out the basic principles for multi-root exploration of cluttered scenes, with up to 65% speed up in the single UAV case and 40% increase in explored area for the same mission time in multi-UAV setups.
Real-time single image depth perception in the wild with handheld devices
Jun 10, 2020
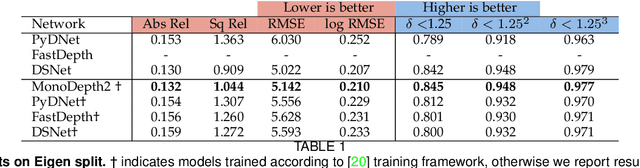

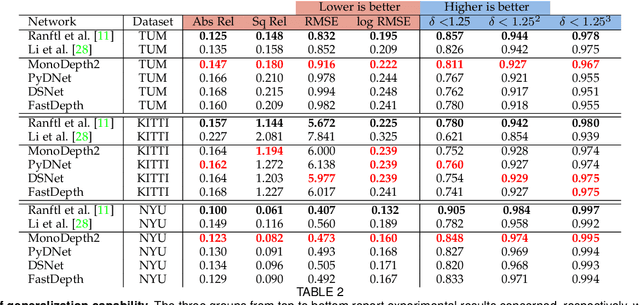
Depth perception is paramount to tackle real-world problems, ranging from autonomous driving to consumer applications. For the latter, depth estimation from a single image represents the most versatile solution, since a standard camera is available on almost any handheld device. Nonetheless, two main issues limit its practical deployment: i) the low reliability when deployed in-the-wild and ii) the demanding resource requirements to achieve real-time performance, often not compatible with such devices. Therefore, in this paper, we deeply investigate these issues showing how they are both addressable adopting appropriate network design and training strategies -- also outlining how to map the resulting networks on handheld devices to achieve real-time performance. Our thorough evaluation highlights the ability of such fast networks to generalize well to new environments, a crucial feature required to tackle the extremely varied contexts faced in real applications. Indeed, to further support this evidence, we report experimental results concerning real-time depth-aware augmented reality and image blurring with smartphones in-the-wild.
A Fully-Integrated Sensing and Control System for High-Accuracy Mobile Robotic Building Construction
Dec 04, 2019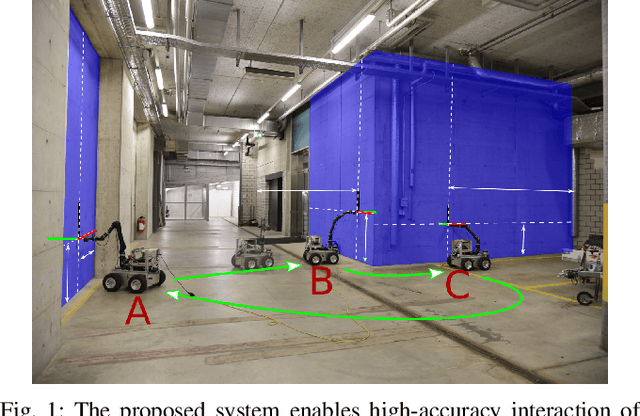
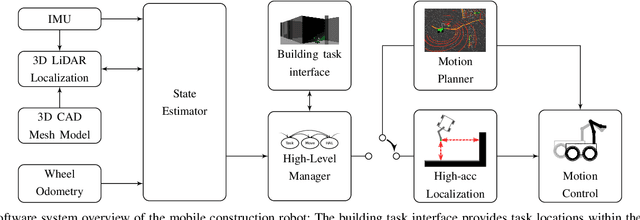

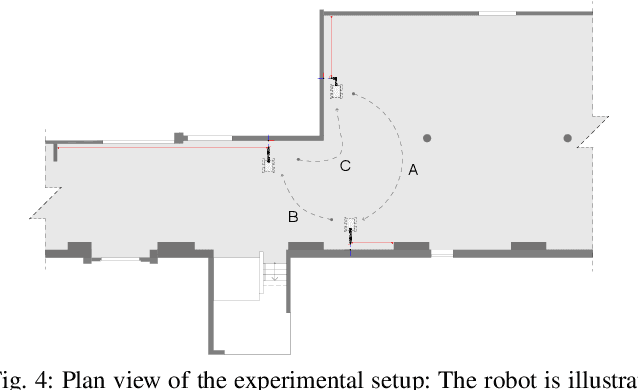
We present a fully-integrated sensing and control system which enables mobile manipulator robots to execute building tasks with millimeter-scale accuracy on building construction sites. The approach leverages multi-modal sensing capabilities for state estimation, tight integration with digital building models, and integrated trajectory planning and whole-body motion control. A novel method for high-accuracy localization updates relative to the known building structure is proposed. The approach is implemented on a real platform and tested under realistic construction conditions. We show that the system can achieve sub-cm end-effector positioning accuracy during fully autonomous operation using solely on-board sensing.