 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTETO: Tracking Events with Teacher Observation for Motion Estimation and Frame Interpolation
Mar 24, 2026Event cameras capture per-pixel brightness changes with microsecond resolution, offering continuous motion information lost between RGB frames. However, existing event-based motion estimators depend on large-scale synthetic data that often suffers from a significant sim-to-real gap. We propose TETO (Tracking Events with Teacher Observation), a teacher-student framework that learns event motion estimation from only $\sim$25 minutes of unannotated real-world recordings through knowledge distillation from a pretrained RGB tracker. Our motion-aware data curation and query sampling strategy maximizes learning from limited data by disentangling object motion from dominant ego-motion. The resulting estimator jointly predicts point trajectories and dense optical flow, which we leverage as explicit motion priors to condition a pretrained video diffusion transformer for frame interpolation. We achieve state-of-the-art point tracking on EVIMO2 and optical flow on DSEC using orders of magnitude less training data, and demonstrate that accurate motion estimation translates directly to superior frame interpolation quality on BS-ERGB and HQ-EVFI.
SpikeMatch: Semi-Supervised Learning with Temporal Dynamics of Spiking Neural Networks
Sep 26, 2025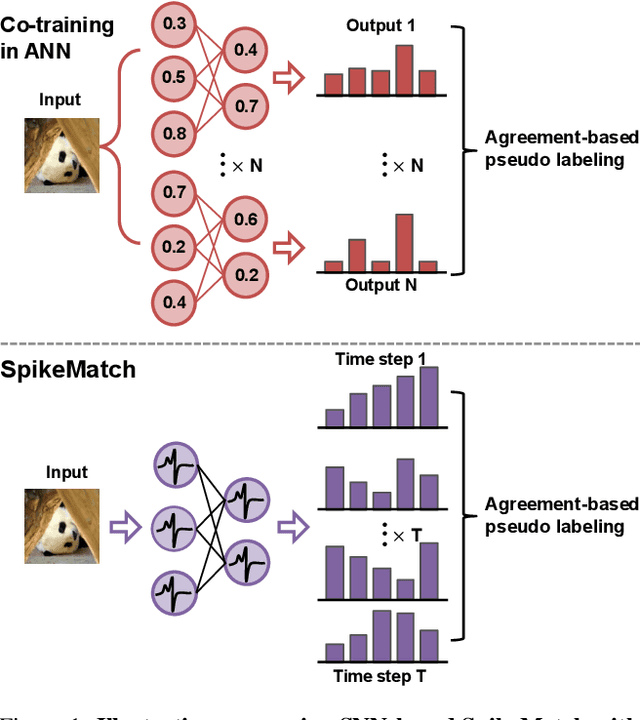
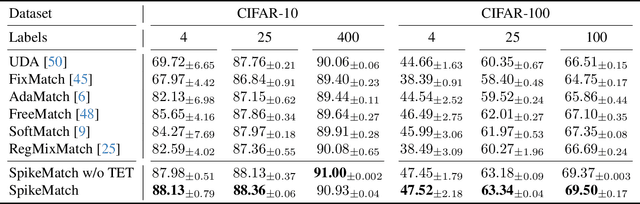
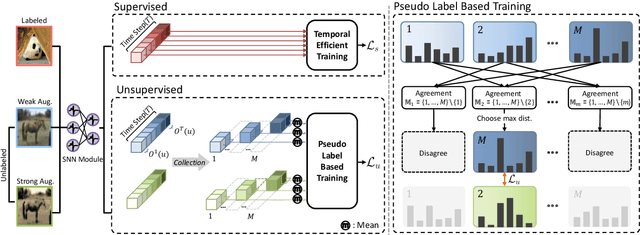
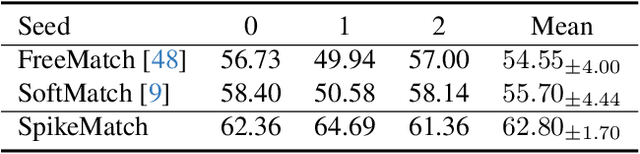
Spiking neural networks (SNNs) have recently been attracting significant attention for their biological plausibility and energy efficiency, but semi-supervised learning (SSL) methods for SNN-based models remain underexplored compared to those for artificial neural networks (ANNs). In this paper, we introduce SpikeMatch, the first SSL framework for SNNs that leverages the temporal dynamics through the leakage factor of SNNs for diverse pseudo-labeling within a co-training framework. By utilizing agreement among multiple predictions from a single SNN, SpikeMatch generates reliable pseudo-labels from weakly-augmented unlabeled samples to train on strongly-augmented ones, effectively mitigating confirmation bias by capturing discriminative features with limited labels. Experiments show that SpikeMatch outperforms existing SSL methods adapted to SNN backbones across various standard benchmarks.
A Prototype Unit for Image De-raining using Time-Lapse Data
Dec 27, 2024
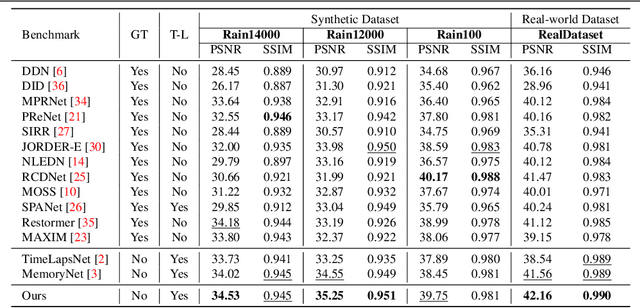
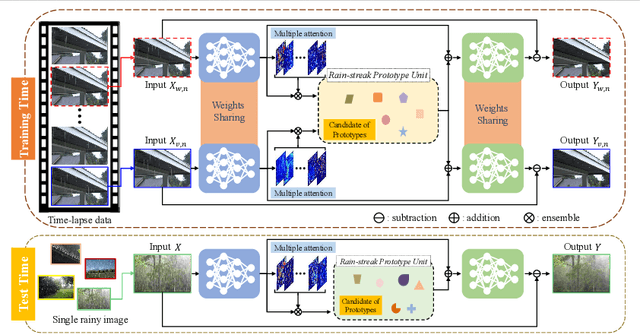

We address the challenge of single-image de-raining, a task that involves recovering rain-free background information from a single rain image. While recent advancements have utilized real-world time-lapse data for training, enabling the estimation of consistent backgrounds and realistic rain streaks, these methods often suffer from computational and memory consumption, limiting their applicability in real-world scenarios. In this paper, we introduce a novel solution: the Rain Streak Prototype Unit (RsPU). The RsPU efficiently encodes rain streak-relevant features as real-time prototypes derived from time-lapse data, eliminating the need for excessive memory resources. Our de-raining network combines encoder-decoder networks with the RsPU, allowing us to learn and encapsulate diverse rain streak-relevant features as concise prototypes, employing an attention-based approach. To ensure the effectiveness of our approach, we propose a feature prototype loss encompassing cohesion and divergence components. This loss function captures both the compactness and diversity aspects of the prototypical rain streak features within the RsPU. Our method evaluates various de-raining benchmarks, accompanied by comprehensive ablation studies. We show that it can achieve competitive results in various rain images compared to state-of-the-art methods.
Context-Preserving Instance-Level Augmentation and Deformable Convolution Networks for SAR Ship Detection
Feb 14, 2022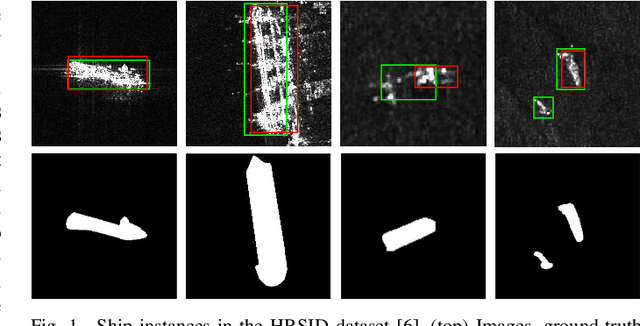

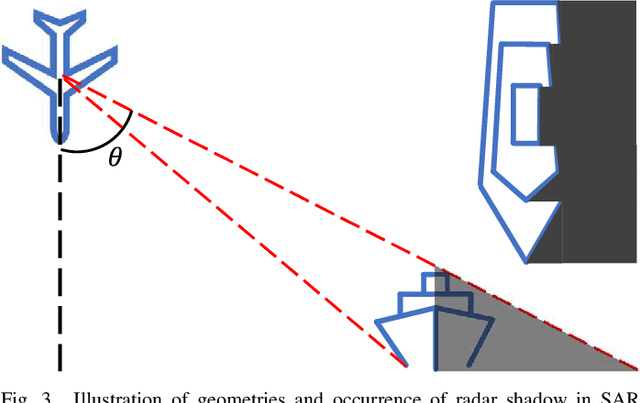

Shape deformation of targets in SAR image due to random orientation and partial information loss caused by occlusion of the radar signal, is an essential challenge in SAR ship detection. In this paper, we propose a data augmentation method to train a deep network that is robust to partial information loss within the targets. Taking advantage of ground-truth annotations for bounding box and instance segmentation mask, we present a simple and effective pipeline to simulate information loss on targets in instance-level, while preserving contextual information. Furthermore, we adopt deformable convolutional network to adaptively extract shape-invariant deep features from geometrically translated targets. By learning sampling offset to the grid of standard convolution, the network can robustly extract the features from targets with shape variations for SAR ship detection. Experiments on the HRSID dataset including comparisons with other deep networks and augmentation methods, as well as ablation study, demonstrate the effectiveness of our proposed method.
Dual Prototypical Contrastive Learning for Few-shot Semantic Segmentation
Nov 09, 2021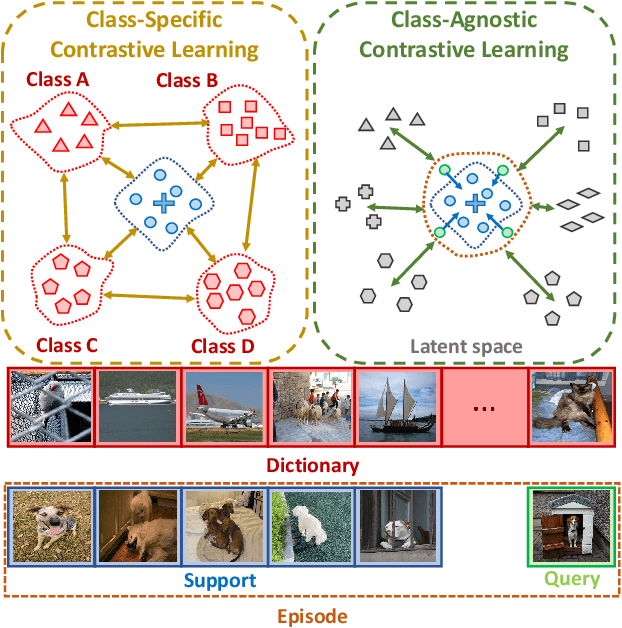
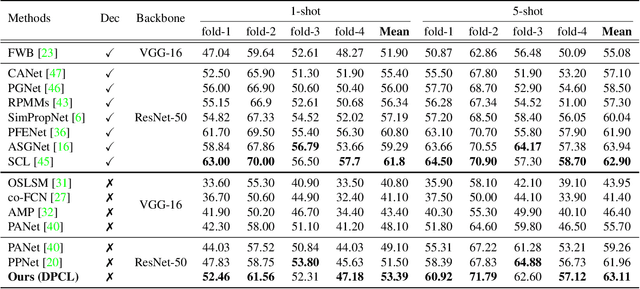
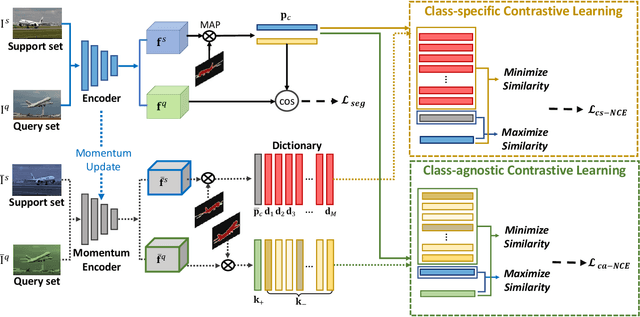

We address the problem of few-shot semantic segmentation (FSS), which aims to segment novel class objects in a target image with a few annotated samples. Though recent advances have been made by incorporating prototype-based metric learning, existing methods still show limited performance under extreme intra-class object variations and semantically similar inter-class objects due to their poor feature representation. To tackle this problem, we propose a dual prototypical contrastive learning approach tailored to the FSS task to capture the representative semanticfeatures effectively. The main idea is to encourage the prototypes more discriminative by increasing inter-class distance while reducing intra-class distance in prototype feature space. To this end, we first present a class-specific contrastive loss with a dynamic prototype dictionary that stores the class-aware prototypes during training, thus enabling the same class prototypes similar and the different class prototypes to be dissimilar. Furthermore, we introduce a class-agnostic contrastive loss to enhance the generalization ability to unseen classes by compressing the feature distribution of semantic class within each episode. We demonstrate that the proposed dual prototypical contrastive learning approach outperforms state-of-the-art FSS methods on PASCAL-5i and COCO-20i datasets. The code is available at:https://github.com/kwonjunn01/DPCL1.
Looking into Your Speech: Learning Cross-modal Affinity for Audio-visual Speech Separation
Mar 25, 2021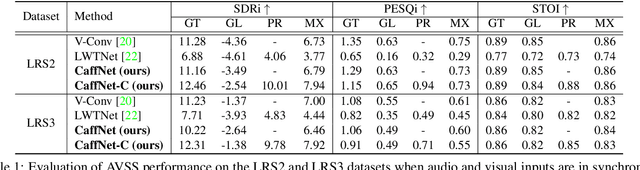
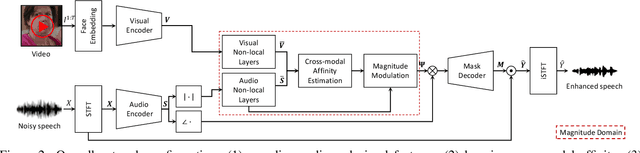
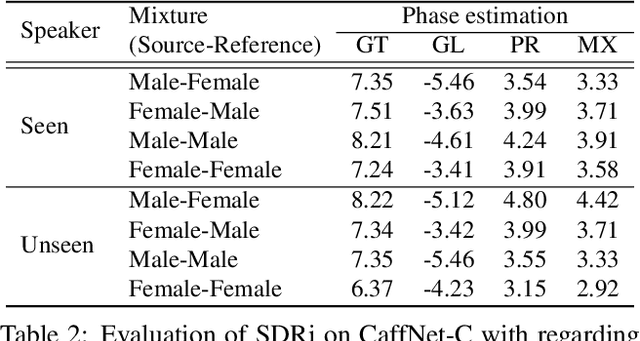
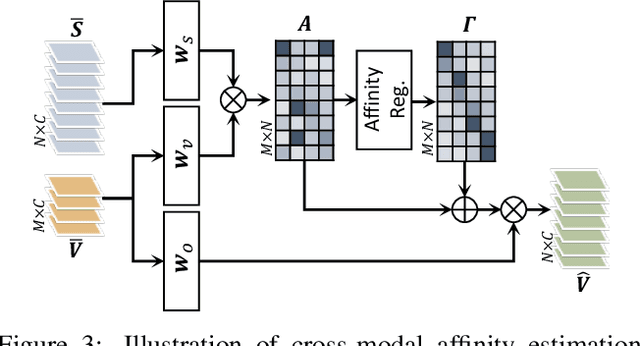
In this paper, we address the problem of separating individual speech signals from videos using audio-visual neural processing. Most conventional approaches utilize frame-wise matching criteria to extract shared information between co-occurring audio and video. Thus, their performance heavily depends on the accuracy of audio-visual synchronization and the effectiveness of their representations. To overcome the frame discontinuity problem between two modalities due to transmission delay mismatch or jitter, we propose a cross-modal affinity network (CaffNet) that learns global correspondence as well as locally-varying affinities between audio and visual streams. Given that the global term provides stability over a temporal sequence at the utterance-level, this resolves the label permutation problem characterized by inconsistent assignments. By extending the proposed cross-modal affinity on the complex network, we further improve the separation performance in the complex spectral domain. Experimental results verify that the proposed methods outperform conventional ones on various datasets, demonstrating their advantages in real-world scenarios.
On the confidence of stereo matching in a deep-learning era: a quantitative evaluation
Jan 02, 2021
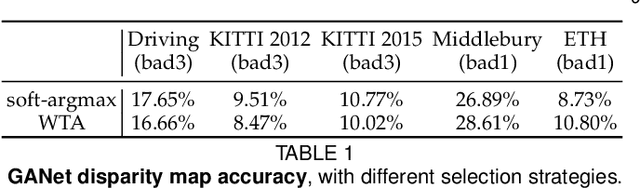
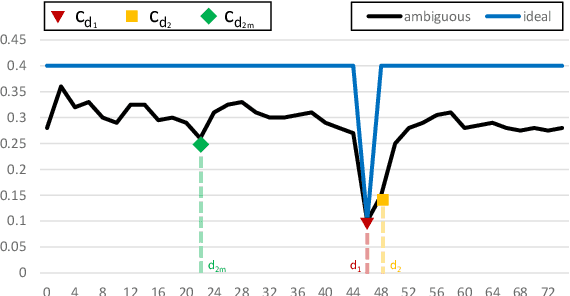
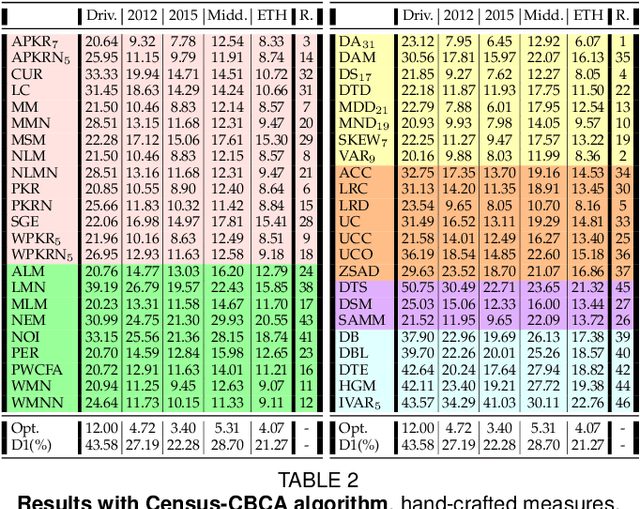
Stereo matching is one of the most popular techniques to estimate dense depth maps by finding the disparity between matching pixels on two, synchronized and rectified images. Alongside with the development of more accurate algorithms, the research community focused on finding good strategies to estimate the reliability, i.e. the confidence, of estimated disparity maps. This information proves to be a powerful cue to naively find wrong matches as well as to improve the overall effectiveness of a variety of stereo algorithms according to different strategies. In this paper, we review more than ten years of developments in the field of confidence estimation for stereo matching. We extensively discuss and evaluate existing confidence measures and their variants, from hand-crafted ones to the most recent, state-of-the-art learning based methods. We study the different behaviors of each measure when applied to a pool of different stereo algorithms and, for the first time in literature, when paired with a state-of-the-art deep stereo network. Our experiments, carried out on five different standard datasets, provide a comprehensive overview of the field, highlighting in particular both strengths and limitations of learning-based strategies.
Adaptive confidence thresholding for semi-supervised monocular depth estimation
Sep 27, 2020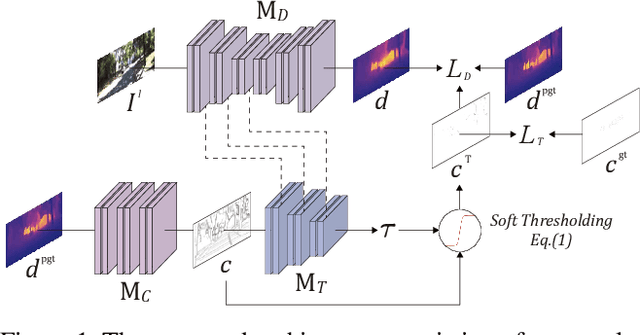
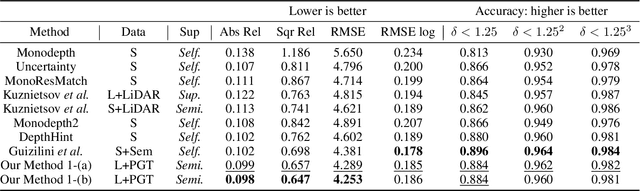
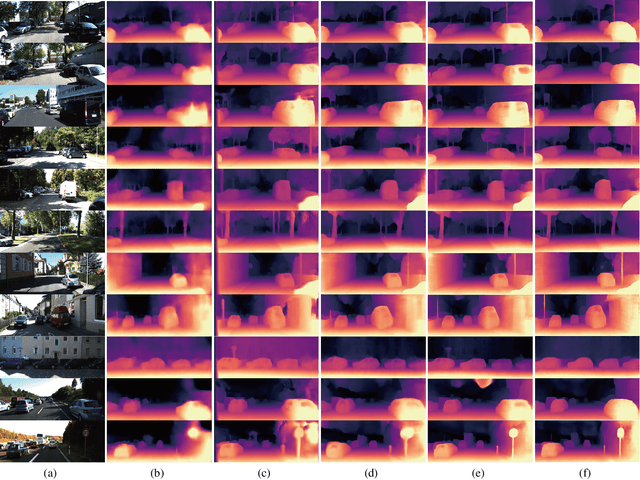
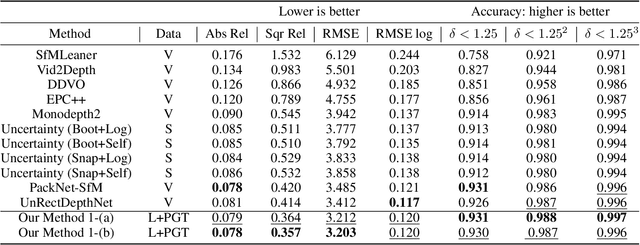
Self-supervised monocular depth estimation has become an appealing solution to the lack of ground truth labels, but its reconstruction loss often produces over-smoothed results across object boundaries and is incapable of handling occlusion explicitly. In this paper, we propose a new approach to leverage pseudo ground truth depth maps of stereo images generated from pretrained stereo matching methods. Our method is comprised of three subnetworks; monocular depth network, confidence network, and threshold network. The confidence map of the pseudo ground truth depth map is first estimated to mitigate performance degeneration by inaccurate pseudo depth maps. To cope with the prediction error of the confidence map itself, we also propose to leverage the threshold network that learns the threshold {\tau} in an adaptive manner. The confidence map is thresholded via a differentiable soft-thresholding operator using this truncation boundary {\tau}. The pseudo depth labels filtered out by the thresholded confidence map are finally used to supervise the monocular depth network. To apply the proposed method to various training dataset, we introduce the network-wise training strategy that transfers the knowledge learned from one dataset to another. Experimental results demonstrate superior performance to state-of-the-art monocular depth estimation methods. Lastly, we exhibit that the threshold network can also be used to improve the performance of existing confidence estimation approaches.
Context-Aware Emotion Recognition Networks
Aug 16, 2019
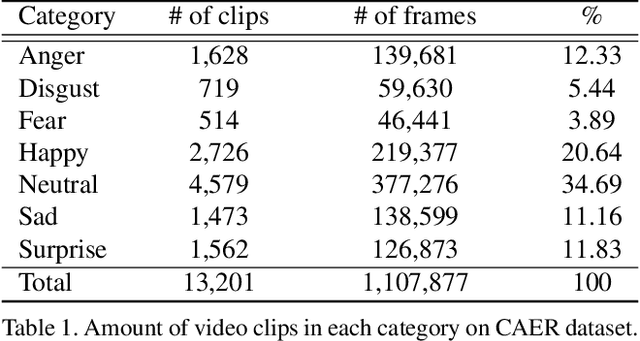
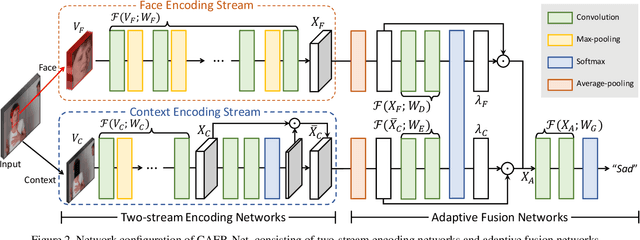
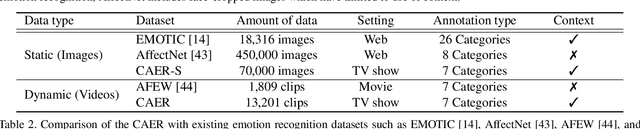
Traditional techniques for emotion recognition have focused on the facial expression analysis only, thus providing limited ability to encode context that comprehensively represents the emotional responses. We present deep networks for context-aware emotion recognition, called CAER-Net, that exploit not only human facial expression but also context information in a joint and boosting manner. The key idea is to hide human faces in a visual scene and seek other contexts based on an attention mechanism. Our networks consist of two sub-networks, including two-stream encoding networks to seperately extract the features of face and context regions, and adaptive fusion networks to fuse such features in an adaptive fashion. We also introduce a novel benchmark for context-aware emotion recognition, called CAER, that is more appropriate than existing benchmarks both qualitatively and quantitatively. On several benchmarks, CAER-Net proves the effect of context for emotion recognition. Our dataset is available at http://caer-dataset.github.io.
Semantic Attribute Matching Networks
Apr 05, 2019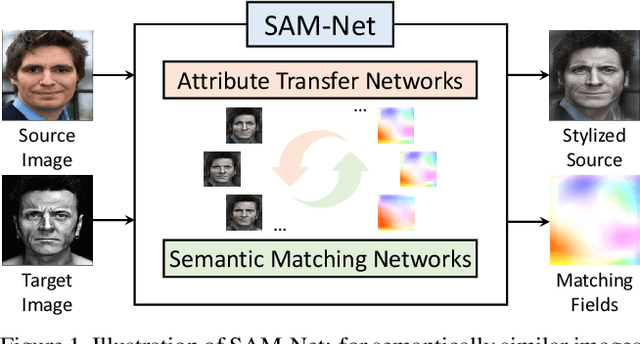
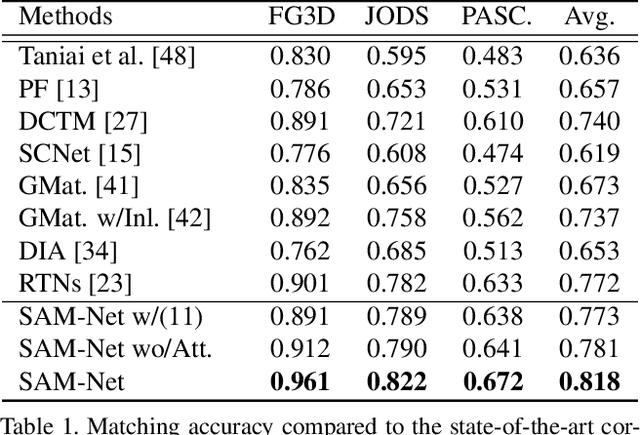
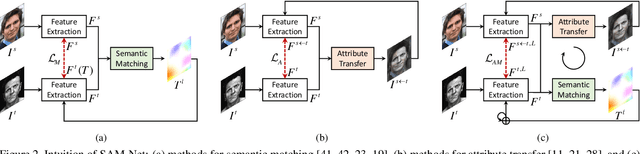
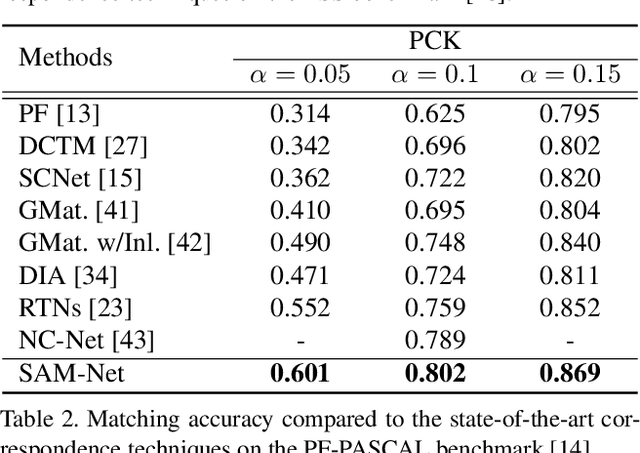
We present semantic attribute matching networks (SAM-Net) for jointly establishing correspondences and transferring attributes across semantically similar images, which intelligently weaves the advantages of the two tasks while overcoming their limitations. SAM-Net accomplishes this through an iterative process of establishing reliable correspondences by reducing the attribute discrepancy between the images and synthesizing attribute transferred images using the learned correspondences. To learn the networks using weak supervisions in the form of image pairs, we present a semantic attribute matching loss based on the matching similarity between an attribute transferred source feature and a warped target feature. With SAM-Net, the state-of-the-art performance is attained on several benchmarks for semantic matching and attribute transfer.