 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Alignment for Unified Multimodal Models via Semantically-Grounded Supervision
Mar 20, 2026Unified Multimodal Models (UMMs) have emerged as a promising paradigm that integrates multimodal understanding and generation within a unified modeling framework. However, current generative training paradigms suffer from inherent limitations. We present Semantically-Grounded Supervision (SeGroS), a fine-tuning framework designed to resolve the granularity mismatch and supervisory redundancy in UMMs. At its core, we propose a novel visual grounding map to construct two complementary supervision signals. First, we formulate semantic Visual Hints to compensate for the sparsity of text prompts. Second, we generate a semantically-grounded Corrupted Input to explicitly enhance the supervision of masking-based UMMs by restricting the reconstruction loss to core text-aligned regions. Extensive evaluations on GenEval, DPGBench, and CompBench demonstrate that SeGroS significantly improves generation fidelity and cross-modal alignment across various UMM architectures.
RobIA: Robust Instance-aware Continual Test-time Adaptation for Deep Stereo
Nov 13, 2025Stereo Depth Estimation in real-world environments poses significant challenges due to dynamic domain shifts, sparse or unreliable supervision, and the high cost of acquiring dense ground-truth labels. While recent Test-Time Adaptation (TTA) methods offer promising solutions, most rely on static target domain assumptions and input-invariant adaptation strategies, limiting their effectiveness under continual shifts. In this paper, we propose RobIA, a novel Robust, Instance-Aware framework for Continual Test-Time Adaptation (CTTA) in stereo depth estimation. RobIA integrates two key components: (1) Attend-and-Excite Mixture-of-Experts (AttEx-MoE), a parameter-efficient module that dynamically routes input to frozen experts via lightweight self-attention mechanism tailored to epipolar geometry, and (2) Robust AdaptBN Teacher, a PEFT-based teacher model that provides dense pseudo-supervision by complementing sparse handcrafted labels. This strategy enables input-specific flexibility, broad supervision coverage, improving generalization under domain shift. Extensive experiments demonstrate that RobIA achieves superior adaptation performance across dynamic target domains while maintaining computational efficiency.
TADFormer : Task-Adaptive Dynamic Transformer for Efficient Multi-Task Learning
Jan 08, 2025



Transfer learning paradigm has driven substantial advancements in various vision tasks. However, as state-of-the-art models continue to grow, classical full fine-tuning often becomes computationally impractical, particularly in multi-task learning (MTL) setup where training complexity increases proportional to the number of tasks. Consequently, recent studies have explored Parameter-Efficient Fine-Tuning (PEFT) for MTL architectures. Despite some progress, these approaches still exhibit limitations in capturing fine-grained, task-specific features that are crucial to MTL. In this paper, we introduce Task-Adaptive Dynamic transFormer, termed TADFormer, a novel PEFT framework that performs task-aware feature adaptation in the fine-grained manner by dynamically considering task-specific input contexts. TADFormer proposes the parameter-efficient prompting for task adaptation and the Dynamic Task Filter (DTF) to capture task information conditioned on input contexts. Experiments on the PASCAL-Context benchmark demonstrate that the proposed method achieves higher accuracy in dense scene understanding tasks, while reducing the number of trainable parameters by up to 8.4 times when compared to full fine-tuning of MTL models. TADFormer also demonstrates superior parameter efficiency and accuracy compared to recent PEFT methods.
Improving Generative Pre-Training: An In-depth Study of Masked Image Modeling and Denoising Models
Dec 26, 2024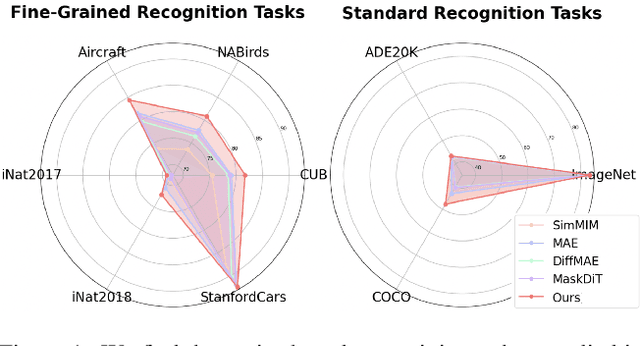
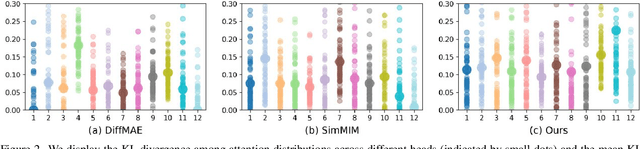

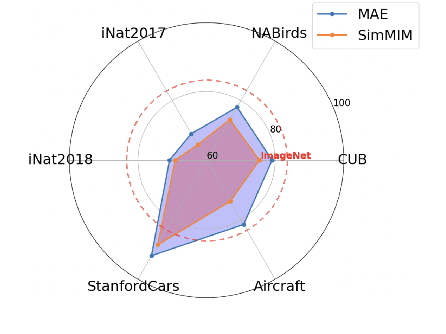
In this work, we dive deep into the impact of additive noise in pre-training deep networks. While various methods have attempted to use additive noise inspired by the success of latent denoising diffusion models, when used in combination with masked image modeling, their gains have been marginal when it comes to recognition tasks. We thus investigate why this would be the case, in an attempt to find effective ways to combine the two ideas. Specifically, we find three critical conditions: corruption and restoration must be applied within the encoder, noise must be introduced in the feature space, and an explicit disentanglement between noised and masked tokens is necessary. By implementing these findings, we demonstrate improved pre-training performance for a wide range of recognition tasks, including those that require fine-grained, high-frequency information to solve.
iConFormer: Dynamic Parameter-Efficient Tuning with Input-Conditioned Adaptation
Sep 04, 2024Transfer learning based on full fine-tuning (FFT) of the pre-trained encoder and task-specific decoder becomes increasingly complex as deep models grow exponentially. Parameter efficient fine-tuning (PEFT) approaches using adapters consisting of small learnable layers have emerged as an alternative to FFT, achieving comparable performance while maintaining high training efficiency. However, the inflexibility of the adapter with respect to input instances limits its capability of learning task-specific information in diverse downstream tasks. In this paper, we propose a novel PEFT approach, input-Conditioned transFormer, termed iConFormer, that leverages a dynamic adapter conditioned on the input instances. To secure flexible learning ability on input instances in various downstream tasks, we introduce an input-Conditioned Network (iCoN) in the dynamic adapter that enables instance-level feature transformation. To be specific, iCoN generates channel-wise convolutional kernels for each feature and transform it using adaptive convolution process to effectively capture task-specific and fine-grained details tailor to downstream tasks. Experimental results demonstrate that by tuning just 1.6% to 2.8% of the Transformer backbone parameters, iConFormer achieves performance comparable to FFT in monocular depth estimation and semantic segmentation, while outperforming it in image classification and instance segmentation. Also, the proposed method consistently outperforms recent PEFT methods for all the tasks mentioned above.
SG-MIM: Structured Knowledge Guided Efficient Pre-training for Dense Prediction
Sep 04, 2024Masked Image Modeling (MIM) techniques have redefined the landscape of computer vision, enabling pre-trained models to achieve exceptional performance across a broad spectrum of tasks. Despite their success, the full potential of MIM-based methods in dense prediction tasks, particularly in depth estimation, remains untapped. Existing MIM approaches primarily rely on single-image inputs, which makes it challenging to capture the crucial structured information, leading to suboptimal performance in tasks requiring fine-grained feature representation. To address these limitations, we propose SG-MIM, a novel Structured knowledge Guided Masked Image Modeling framework designed to enhance dense prediction tasks by utilizing structured knowledge alongside images. SG-MIM employs a lightweight relational guidance framework, allowing it to guide structured knowledge individually at the feature level rather than naively combining at the pixel level within the same architecture, as is common in traditional multi-modal pre-training methods. This approach enables the model to efficiently capture essential information while minimizing discrepancies between pre-training and downstream tasks. Furthermore, SG-MIM employs a selective masking strategy to incorporate structured knowledge, maximizing the synergy between general representation learning and structured knowledge-specific learning. Our method requires no additional annotations, making it a versatile and efficient solution for a wide range of applications. Our evaluations on the KITTI, NYU-v2, and ADE20k datasets demonstrate SG-MIM's superiority in monocular depth estimation and semantic segmentation.
MaDis-Stereo: Enhanced Stereo Matching via Distilled Masked Image Modeling
Sep 04, 2024



In stereo matching, CNNs have traditionally served as the predominant architectures. Although Transformer-based stereo models have been studied recently, their performance still lags behind CNN-based stereo models due to the inherent data scarcity issue in the stereo matching task. In this paper, we propose Masked Image Modeling Distilled Stereo matching model, termed MaDis-Stereo, that enhances locality inductive bias by leveraging Masked Image Modeling (MIM) in training Transformer-based stereo model. Given randomly masked stereo images as inputs, our method attempts to conduct both image reconstruction and depth prediction tasks. While this strategy is beneficial to resolving the data scarcity issue, the dual challenge of reconstructing masked tokens and subsequently performing stereo matching poses significant challenges, particularly in terms of training stability. To address this, we propose to use an auxiliary network (teacher), updated via Exponential Moving Average (EMA), along with the original stereo model (student), where teacher predictions serve as pseudo supervisory signals to effectively distill knowledge into the student model. State-of-the-arts performance is achieved with the proposed method on several stereo matching such as ETH3D and KITTI 2015. Additionally, to demonstrate that our model effectively leverages locality inductive bias, we provide the attention distance measurement.
UniTT-Stereo: Unified Training of Transformer for Enhanced Stereo Matching
Sep 04, 2024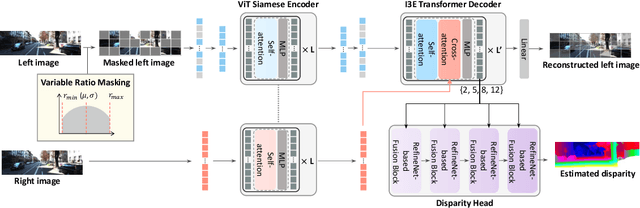
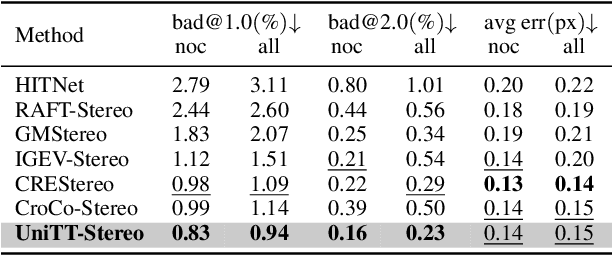
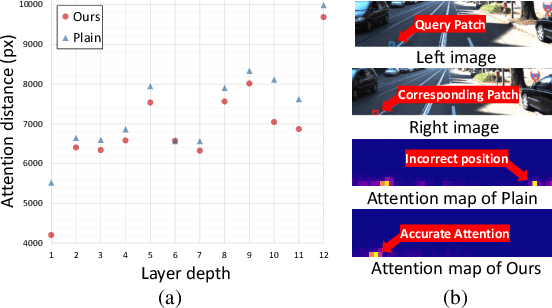
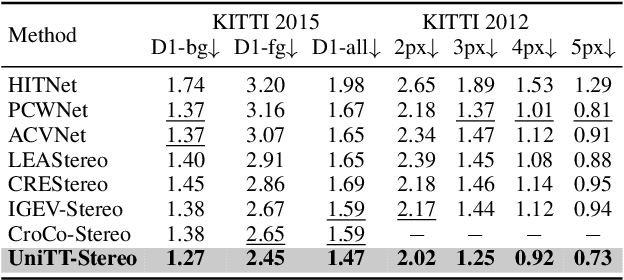
Unlike other vision tasks where Transformer-based approaches are becoming increasingly common, stereo depth estimation is still dominated by convolution-based approaches. This is mainly due to the limited availability of real-world ground truth for stereo matching, which is a limiting factor in improving the performance of Transformer-based stereo approaches. In this paper, we propose UniTT-Stereo, a method to maximize the potential of Transformer-based stereo architectures by unifying self-supervised learning used for pre-training with stereo matching framework based on supervised learning. To be specific, we explore the effectiveness of reconstructing features of masked portions in an input image and at the same time predicting corresponding points in another image from the perspective of locality inductive bias, which is crucial in training models with limited training data. Moreover, to address these challenging tasks of reconstruction-and-prediction, we present a new strategy to vary a masking ratio when training the stereo model with stereo-tailored losses. State-of-the-art performance of UniTT-Stereo is validated on various benchmarks such as ETH3D, KITTI 2012, and KITTI 2015 datasets. Lastly, to investigate the advantages of the proposed approach, we provide a frequency analysis of feature maps and the analysis of locality inductive bias based on attention maps.
CLDA: Collaborative Learning for Enhanced Unsupervised Domain Adaptation
Sep 04, 2024



Unsupervised Domain Adaptation (UDA) endeavors to bridge the gap between a model trained on a labeled source domain and its deployment in an unlabeled target domain. However, current high-performance models demand significant resources, resulting in prohibitive deployment costs and highlighting the need for small yet effective models. For UDA of lightweight models, Knowledge Distillation (KD) in a Teacher-Student framework can be a common approach, but we find that domain shift in UDA leads to a significant increase in non-salient parameters in the teacher model, degrading model's generalization ability and transferring misleading information to the student model. Interestingly, we observed that this phenomenon occurs considerably less in the student model. Driven by this insight, we introduce Collaborative Learning, a method that updates the teacher's non-salient parameters using the student model and at the same time enhance the student's performance using the updated teacher model. Experiments across various tasks and datasets show consistent performance improvements for both student and teacher models. For example, in semantic segmentation, CLDA achieves an improvement of +0.7% mIoU for teacher and +1.4% mIoU for student compared to the baseline model in the GTA to Cityscapes. In the Synthia to Cityscapes, it achieves an improvement of +0.8% mIoU for teacher and +2.0% mIoU for student.
Emerging Property of Masked Token for Effective Pre-training
Apr 12, 2024



Driven by the success of Masked Language Modeling (MLM), the realm of self-supervised learning for computer vision has been invigorated by the central role of Masked Image Modeling (MIM) in driving recent breakthroughs. Notwithstanding the achievements of MIM across various downstream tasks, its overall efficiency is occasionally hampered by the lengthy duration of the pre-training phase. This paper presents a perspective that the optimization of masked tokens as a means of addressing the prevailing issue. Initially, we delve into an exploration of the inherent properties that a masked token ought to possess. Within the properties, we principally dedicated to articulating and emphasizing the `data singularity' attribute inherent in masked tokens. Through a comprehensive analysis of the heterogeneity between masked tokens and visible tokens within pre-trained models, we propose a novel approach termed masked token optimization (MTO), specifically designed to improve model efficiency through weight recalibration and the enhancement of the key property of masked tokens. The proposed method serves as an adaptable solution that seamlessly integrates into any MIM approach that leverages masked tokens. As a result, MTO achieves a considerable improvement in pre-training efficiency, resulting in an approximately 50% reduction in pre-training epochs required to attain converged performance of the recent approaches.