 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaDis-Stereo: Enhanced Stereo Matching via Distilled Masked Image Modeling
Sep 04, 2024



In stereo matching, CNNs have traditionally served as the predominant architectures. Although Transformer-based stereo models have been studied recently, their performance still lags behind CNN-based stereo models due to the inherent data scarcity issue in the stereo matching task. In this paper, we propose Masked Image Modeling Distilled Stereo matching model, termed MaDis-Stereo, that enhances locality inductive bias by leveraging Masked Image Modeling (MIM) in training Transformer-based stereo model. Given randomly masked stereo images as inputs, our method attempts to conduct both image reconstruction and depth prediction tasks. While this strategy is beneficial to resolving the data scarcity issue, the dual challenge of reconstructing masked tokens and subsequently performing stereo matching poses significant challenges, particularly in terms of training stability. To address this, we propose to use an auxiliary network (teacher), updated via Exponential Moving Average (EMA), along with the original stereo model (student), where teacher predictions serve as pseudo supervisory signals to effectively distill knowledge into the student model. State-of-the-arts performance is achieved with the proposed method on several stereo matching such as ETH3D and KITTI 2015. Additionally, to demonstrate that our model effectively leverages locality inductive bias, we provide the attention distance measurement.
UniTT-Stereo: Unified Training of Transformer for Enhanced Stereo Matching
Sep 04, 2024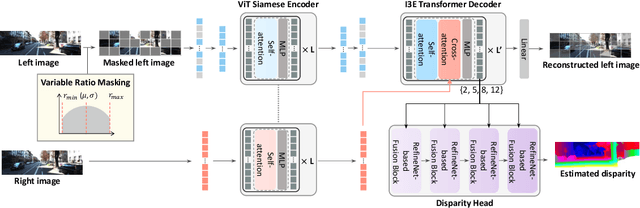
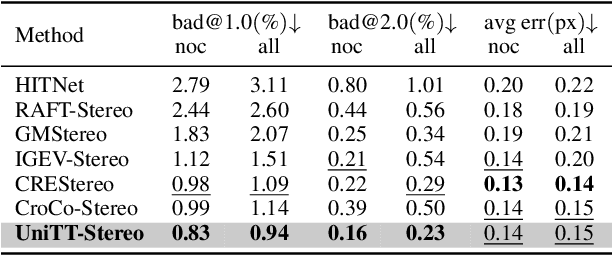
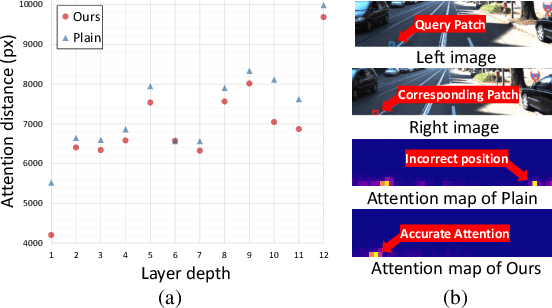
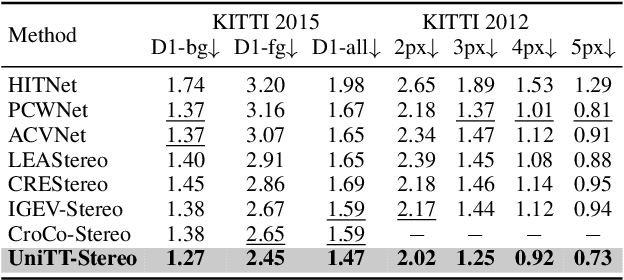
Unlike other vision tasks where Transformer-based approaches are becoming increasingly common, stereo depth estimation is still dominated by convolution-based approaches. This is mainly due to the limited availability of real-world ground truth for stereo matching, which is a limiting factor in improving the performance of Transformer-based stereo approaches. In this paper, we propose UniTT-Stereo, a method to maximize the potential of Transformer-based stereo architectures by unifying self-supervised learning used for pre-training with stereo matching framework based on supervised learning. To be specific, we explore the effectiveness of reconstructing features of masked portions in an input image and at the same time predicting corresponding points in another image from the perspective of locality inductive bias, which is crucial in training models with limited training data. Moreover, to address these challenging tasks of reconstruction-and-prediction, we present a new strategy to vary a masking ratio when training the stereo model with stereo-tailored losses. State-of-the-art performance of UniTT-Stereo is validated on various benchmarks such as ETH3D, KITTI 2012, and KITTI 2015 datasets. Lastly, to investigate the advantages of the proposed approach, we provide a frequency analysis of feature maps and the analysis of locality inductive bias based on attention maps.