 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Product Search Relevance with EAR-MP: A Solution for the CIKM 2025 AnalytiCup
Oct 27, 2025Multilingual e-commerce search is challenging due to linguistic diversity and the noise inherent in user-generated queries. This paper documents the solution employed by our team (EAR-MP) for the CIKM 2025 AnalytiCup, which addresses two core tasks: Query-Category (QC) relevance and Query-Item (QI) relevance. Our approach first normalizes the multilingual dataset by translating all text into English, then mitigates noise through extensive data cleaning and normalization. For model training, we build on DeBERTa-v3-large and improve performance with label smoothing, self-distillation, and dropout. In addition, we introduce task-specific upgrades, including hierarchical token injection for QC and a hybrid scoring mechanism for QI. Under constrained compute, our method achieves competitive results, attaining an F1 score of 0.8796 on QC and 0.8744 on QI. These findings underscore the importance of systematic data preprocessing and tailored training strategies for building robust, resource-efficient multilingual relevance systems.
RICoTA: Red-teaming of In-the-wild Conversation with Test Attempts
Jan 29, 2025

User interactions with conversational agents (CAs) evolve in the era of heavily guardrailed large language models (LLMs). As users push beyond programmed boundaries to explore and build relationships with these systems, there is a growing concern regarding the potential for unauthorized access or manipulation, commonly referred to as "jailbreaking." Moreover, with CAs that possess highly human-like qualities, users show a tendency toward initiating intimate sexual interactions or attempting to tame their chatbots. To capture and reflect these in-the-wild interactions into chatbot designs, we propose RICoTA, a Korean red teaming dataset that consists of 609 prompts challenging LLMs with in-the-wild user-made dialogues capturing jailbreak attempts. We utilize user-chatbot conversations that were self-posted on a Korean Reddit-like community, containing specific testing and gaming intentions with a social chatbot. With these prompts, we aim to evaluate LLMs' ability to identify the type of conversation and users' testing purposes to derive chatbot design implications for mitigating jailbreaking risks. Our dataset will be made publicly available via GitHub.
UniTT-Stereo: Unified Training of Transformer for Enhanced Stereo Matching
Sep 04, 2024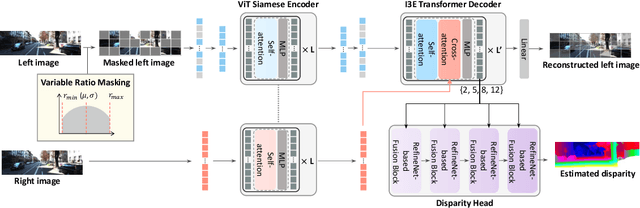
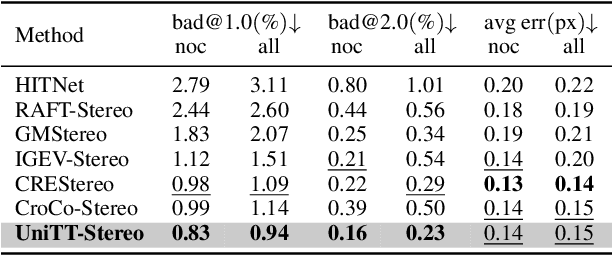
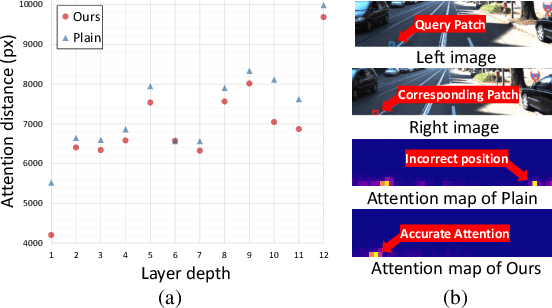
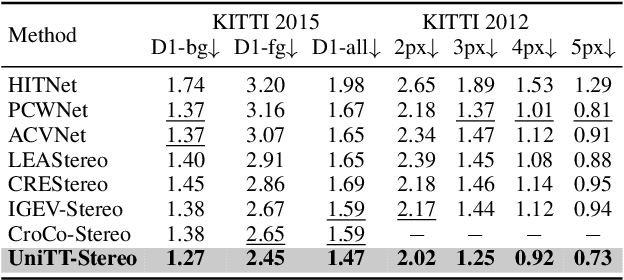
Unlike other vision tasks where Transformer-based approaches are becoming increasingly common, stereo depth estimation is still dominated by convolution-based approaches. This is mainly due to the limited availability of real-world ground truth for stereo matching, which is a limiting factor in improving the performance of Transformer-based stereo approaches. In this paper, we propose UniTT-Stereo, a method to maximize the potential of Transformer-based stereo architectures by unifying self-supervised learning used for pre-training with stereo matching framework based on supervised learning. To be specific, we explore the effectiveness of reconstructing features of masked portions in an input image and at the same time predicting corresponding points in another image from the perspective of locality inductive bias, which is crucial in training models with limited training data. Moreover, to address these challenging tasks of reconstruction-and-prediction, we present a new strategy to vary a masking ratio when training the stereo model with stereo-tailored losses. State-of-the-art performance of UniTT-Stereo is validated on various benchmarks such as ETH3D, KITTI 2012, and KITTI 2015 datasets. Lastly, to investigate the advantages of the proposed approach, we provide a frequency analysis of feature maps and the analysis of locality inductive bias based on attention maps.
MaDis-Stereo: Enhanced Stereo Matching via Distilled Masked Image Modeling
Sep 04, 2024



In stereo matching, CNNs have traditionally served as the predominant architectures. Although Transformer-based stereo models have been studied recently, their performance still lags behind CNN-based stereo models due to the inherent data scarcity issue in the stereo matching task. In this paper, we propose Masked Image Modeling Distilled Stereo matching model, termed MaDis-Stereo, that enhances locality inductive bias by leveraging Masked Image Modeling (MIM) in training Transformer-based stereo model. Given randomly masked stereo images as inputs, our method attempts to conduct both image reconstruction and depth prediction tasks. While this strategy is beneficial to resolving the data scarcity issue, the dual challenge of reconstructing masked tokens and subsequently performing stereo matching poses significant challenges, particularly in terms of training stability. To address this, we propose to use an auxiliary network (teacher), updated via Exponential Moving Average (EMA), along with the original stereo model (student), where teacher predictions serve as pseudo supervisory signals to effectively distill knowledge into the student model. State-of-the-arts performance is achieved with the proposed method on several stereo matching such as ETH3D and KITTI 2015. Additionally, to demonstrate that our model effectively leverages locality inductive bias, we provide the attention distance measurement.
Exploring the Effects of AI-assisted Emotional Support Processes in Online Mental Health Community
Feb 21, 2022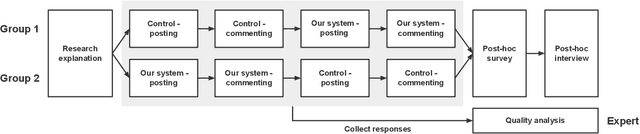
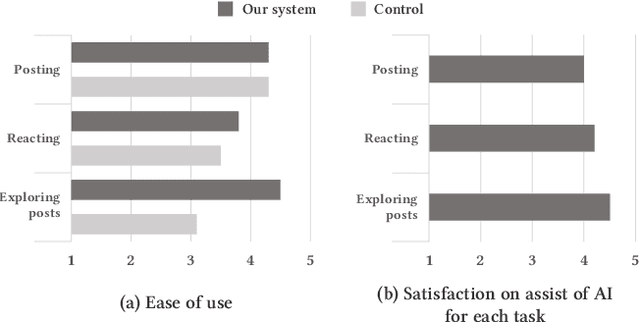
Social support in online mental health communities (OMHCs) is an effective and accessible way of managing mental wellbeing. In this process, sharing emotional supports is considered crucial to the thriving social supports in OMHCs, yet often difficult for both seekers and providers. To support empathetic interactions, we design an AI-infused workflow that allows users to write emotional supporting messages to other users' posts based on the elicitation of the seeker's emotion and contextual keywords from writing. Based on a preliminary user study (N = 10), we identified that the system helped seekers to clarify emotion and describe text concretely while writing a post. Providers could also learn how to react empathetically to the post. Based on these results, we suggest design implications for our proposed system.
Single Image Reflection Removal with Physically-based Rendering
Apr 26, 2019

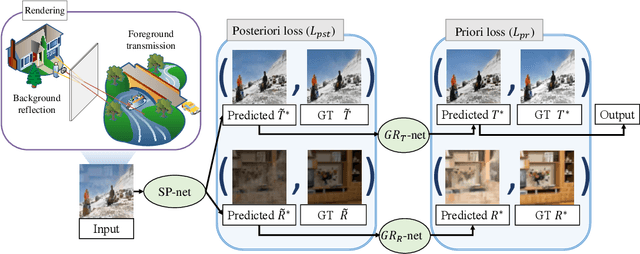
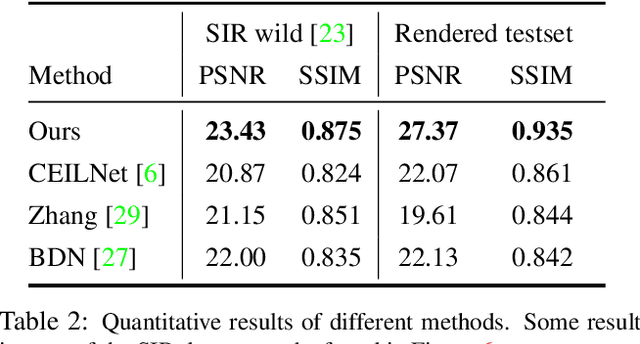
Recently, deep learning based single image reflection separation methods have been exploited widely. To benefit the learning approach, a large number of training image pairs (i.e., with and without reflections) were synthesized in various ways, yet they are away from a physically-based direction. In this paper, physically based rendering is used for faithfully synthesizing the required training images, and corresponding network structure is proposed. We utilize existing image data to estimate mesh, then physically simulate the depth-dependent light transportation between mesh, glass, and lens with path tracing. For guiding the separation better, we additionally consider a module of removing complicated ghosting and blurring glass-effects, which allows obtaining priori information before having the glass distortion. This module is easily accommodated within our approach, since that prior information can be physically generated by our rendering process. The proposed method considering the priori information as well as the existing posterior information is validated with various real reflection images, and is demonstrated to show visually pleasant and numerically better results compared to the state-of-theart techniques.