 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Cross Attention Based Multi-task Learning
Paper and Code
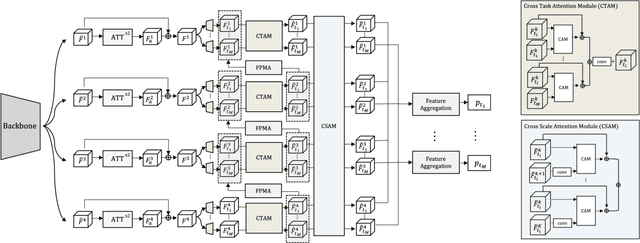
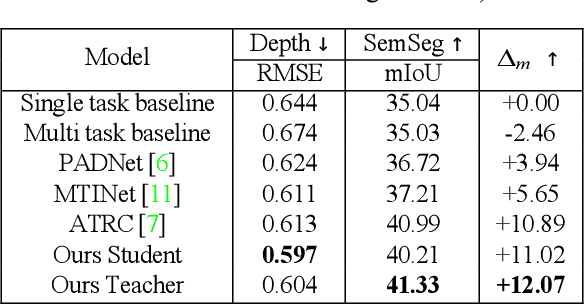
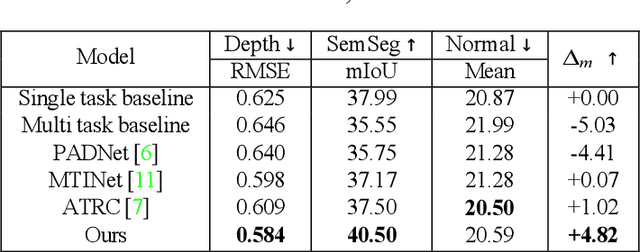
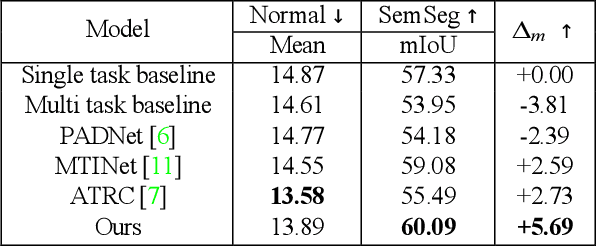
In multi-task learning (MTL) for visual scene understanding, it is crucial to transfer useful information between multiple tasks with minimal interferences. In this paper, we propose a novel architecture that effectively transfers informative features by applying the attention mechanism to the multi-scale features of the tasks. Since applying the attention module directly to all possible features in terms of scale and task requires a high complexity, we propose to apply the attention module sequentially for the task and scale. The cross-task attention module (CTAM) is first applied to facilitate the exchange of relevant information between the multiple task features of the same scale. The cross-scale attention module (CSAM) then aggregates useful information from feature maps at different resolutions in the same task. Also, we attempt to capture long range dependencies through the self-attention module in the feature extraction network. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the NYUD-v2 and PASCAL-Context dataset.