 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Cross Attention Based Multi-task Learning
Sep 06, 2022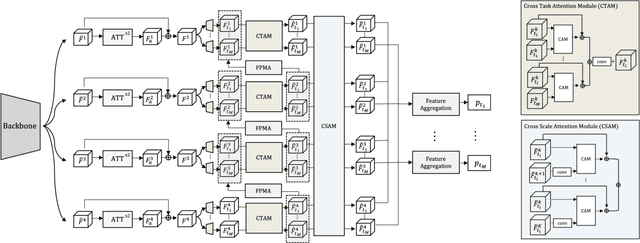
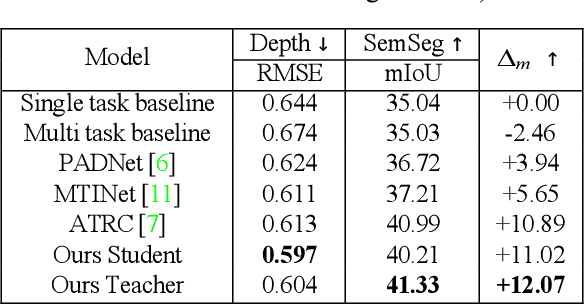
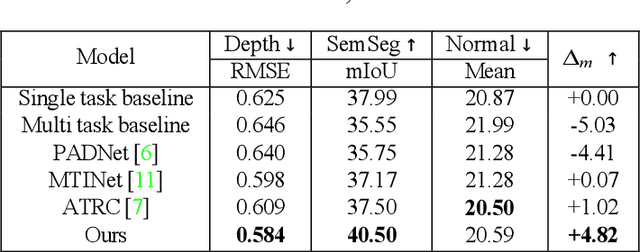
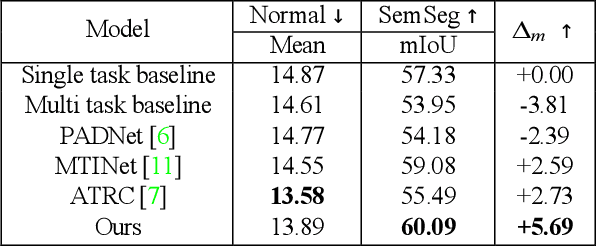
In multi-task learning (MTL) for visual scene understanding, it is crucial to transfer useful information between multiple tasks with minimal interferences. In this paper, we propose a novel architecture that effectively transfers informative features by applying the attention mechanism to the multi-scale features of the tasks. Since applying the attention module directly to all possible features in terms of scale and task requires a high complexity, we propose to apply the attention module sequentially for the task and scale. The cross-task attention module (CTAM) is first applied to facilitate the exchange of relevant information between the multiple task features of the same scale. The cross-scale attention module (CSAM) then aggregates useful information from feature maps at different resolutions in the same task. Also, we attempt to capture long range dependencies through the self-attention module in the feature extraction network. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the NYUD-v2 and PASCAL-Context dataset.
Adaptive confidence thresholding for semi-supervised monocular depth estimation
Sep 27, 2020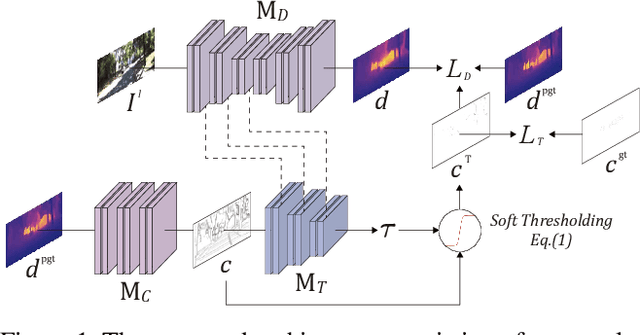
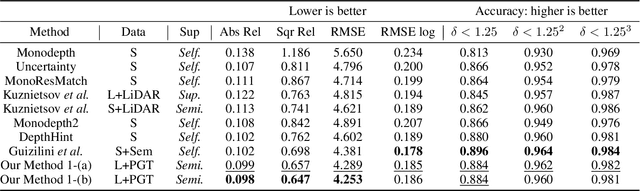
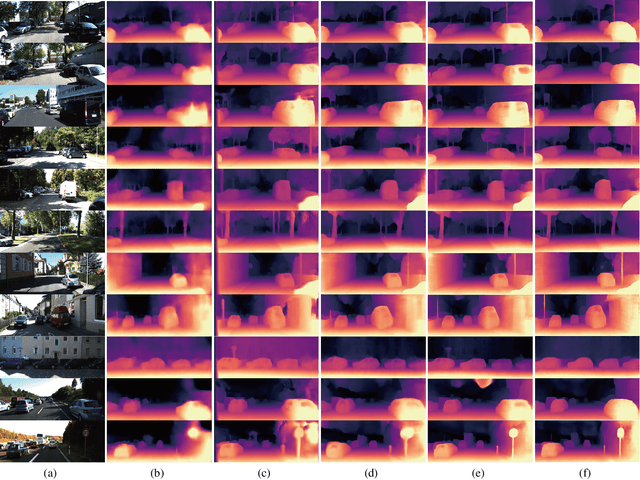
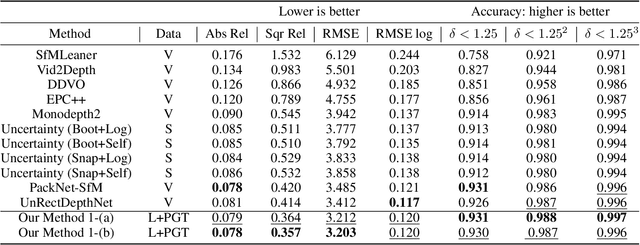
Self-supervised monocular depth estimation has become an appealing solution to the lack of ground truth labels, but its reconstruction loss often produces over-smoothed results across object boundaries and is incapable of handling occlusion explicitly. In this paper, we propose a new approach to leverage pseudo ground truth depth maps of stereo images generated from pretrained stereo matching methods. Our method is comprised of three subnetworks; monocular depth network, confidence network, and threshold network. The confidence map of the pseudo ground truth depth map is first estimated to mitigate performance degeneration by inaccurate pseudo depth maps. To cope with the prediction error of the confidence map itself, we also propose to leverage the threshold network that learns the threshold {\tau} in an adaptive manner. The confidence map is thresholded via a differentiable soft-thresholding operator using this truncation boundary {\tau}. The pseudo depth labels filtered out by the thresholded confidence map are finally used to supervise the monocular depth network. To apply the proposed method to various training dataset, we introduce the network-wise training strategy that transfers the knowledge learned from one dataset to another. Experimental results demonstrate superior performance to state-of-the-art monocular depth estimation methods. Lastly, we exhibit that the threshold network can also be used to improve the performance of existing confidence estimation approaches.