 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-Preserving Concept Erasure via Unsafe-Safe Pairing and Directional Fisher-weighted Adaptation
Feb 05, 2026With the increasing versatility of text-to-image diffusion models, the ability to selectively erase undesirable concepts (e.g., harmful content) has become indispensable. However, existing concept erasure approaches primarily focus on removing unsafe concepts without providing guidance toward corresponding safe alternatives, which often leads to failure in preserving the structural and semantic consistency between the original and erased generations. In this paper, we propose a novel framework, PAIRed Erasing (PAIR), which reframes concept erasure from simple removal to consistency-preserving semantic realignment using unsafe-safe pairs. We first generate safe counterparts from unsafe inputs while preserving structural and semantic fidelity, forming paired unsafe-safe multimodal data. Leveraging these pairs, we introduce two key components: (1) Paired Semantic Realignment, a guided objective that uses unsafe-safe pairs to explicitly map target concepts to semantically aligned safe anchors; and (2) Fisher-weighted Initialization for DoRA, which initializes parameter-efficient low-rank adaptation matrices using unsafe-safe pairs, encouraging the generation of safe alternatives while selectively suppressing unsafe concepts. Together, these components enable fine-grained erasure that removes only the targeted concepts while maintaining overall semantic consistency. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving effective concept erasure while preserving structural integrity, semantic coherence, and generation quality.
Knowledge Vector Weakening: Efficient Training-free Unlearning for Large Vision-Language Models
Jan 29, 2026Large Vision-Language Models (LVLMs) are widely adopted for their strong multimodal capabilities, yet they raise serious concerns such as privacy leakage and harmful content generation. Machine unlearning has emerged as a promising solution for removing the influence of specific data from trained models. However, existing approaches largely rely on gradient-based optimization, incurring substantial computational costs for large-scale LVLMs. To address this limitation, we propose Knowledge Vector Weakening (KVW), a training-free unlearning method that directly intervenes in the full model without gradient computation. KVW identifies knowledge vectors that are activated during the model's output generation on the forget set and progressively weakens their contributions, thereby preventing the model from exploiting undesirable knowledge. Experiments on the MLLMU and CLEAR benchmarks demonstrate that KVW achieves a stable forget-retain trade-off while significantly improving computational efficiency over gradient-based and LoRA-based unlearning methods.
Why Knowledge Distillation Works in Generative Models: A Minimal Working Explanation
May 19, 2025Knowledge distillation (KD) is a core component in the training and deployment of modern generative models, particularly large language models (LLMs). While its empirical benefits are well documented--enabling smaller student models to emulate the performance of much larger teachers--the underlying mechanisms by which KD improves generative quality remain poorly understood. In this work, we present a minimal working explanation of KD in generative modeling. Using a controlled simulation with mixtures of Gaussians, we demonstrate that distillation induces a trade-off between precision and recall in the student model. As the teacher distribution becomes more selective, the student concentrates more probability mass on high-likelihood regions at the expense of coverage--a behavior modulated by a single entropy-controlling parameter. We then validate this effect in a large-scale language modeling setup using the SmolLM2 family of models. Empirical results reveal the same precision-recall dynamics observed in simulation, where precision corresponds to sample quality and recall to distributional coverage. This precision-recall trade-off proves especially beneficial in scenarios where sample quality outweighs diversity, such as instruction tuning or downstream generation. Our analysis provides a simple and general explanation for the effectiveness of KD in generative modeling.
Are We Truly Forgetting? A Critical Re-examination of Machine Unlearning Evaluation Protocols
Mar 10, 2025



Machine unlearning is a process to remove specific data points from a trained model while maintaining the performance on retain data, addressing privacy or legal requirements. Despite its importance, existing unlearning evaluations tend to focus on logit-based metrics (i.e., accuracy) under small-scale scenarios. We observe that this could lead to a false sense of security in unlearning approaches under real-world scenarios. In this paper, we conduct a new comprehensive evaluation that employs representation-based evaluations of the unlearned model under large-scale scenarios to verify whether the unlearning approaches genuinely eliminate the targeted forget data from the model's representation perspective. Our analysis reveals that current state-of-the-art unlearning approaches either completely degrade the representational quality of the unlearned model or merely modify the classifier (i.e., the last layer), thereby achieving superior logit-based evaluation metrics while maintaining significant representational similarity to the original model. Furthermore, we introduce a novel unlearning evaluation setup from a transfer learning perspective, in which the forget set classes exhibit semantic similarity to downstream task classes, necessitating that feature representations diverge significantly from those of the original model. Our comprehensive benchmark not only addresses a critical gap between theoretical machine unlearning and practical scenarios, but also establishes a foundation to inspire future research directions in developing genuinely effective unlearning methodologies.
Cost-Efficient Continual Learning with Sufficient Exemplar Memory
Feb 11, 2025Continual learning (CL) research typically assumes highly constrained exemplar memory resources. However, in many real-world scenarios-especially in the era of large foundation models-memory is abundant, while GPU computational costs are the primary bottleneck. In this work, we investigate CL in a novel setting where exemplar memory is ample (i.e., sufficient exemplar memory). Unlike prior methods designed for strict exemplar memory constraints, we propose a simple yet effective approach that directly operates in the model's weight space through a combination of weight resetting and averaging techniques. Our method achieves state-of-the-art performance while reducing the computational cost to a quarter or third of existing methods. These findings challenge conventional CL assumptions and provide a practical baseline for computationally efficient CL applications.
Improving Generative Pre-Training: An In-depth Study of Masked Image Modeling and Denoising Models
Dec 26, 2024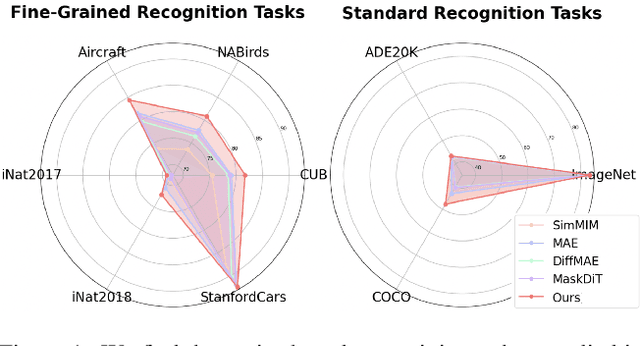
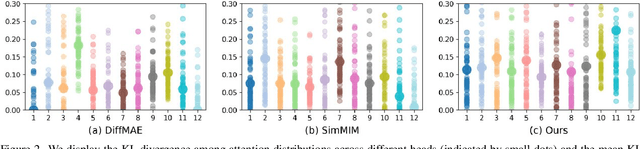

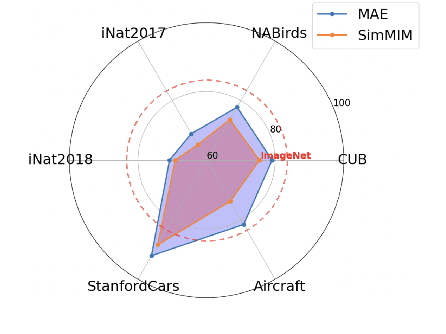
In this work, we dive deep into the impact of additive noise in pre-training deep networks. While various methods have attempted to use additive noise inspired by the success of latent denoising diffusion models, when used in combination with masked image modeling, their gains have been marginal when it comes to recognition tasks. We thus investigate why this would be the case, in an attempt to find effective ways to combine the two ideas. Specifically, we find three critical conditions: corruption and restoration must be applied within the encoder, noise must be introduced in the feature space, and an explicit disentanglement between noised and masked tokens is necessary. By implementing these findings, we demonstrate improved pre-training performance for a wide range of recognition tasks, including those that require fine-grained, high-frequency information to solve.
Towards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
Aug 13, 2024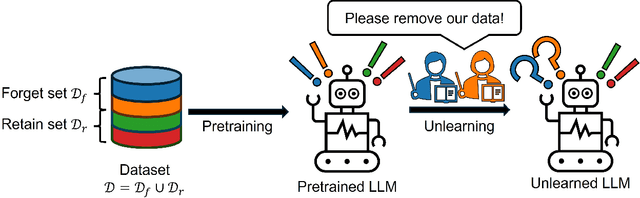
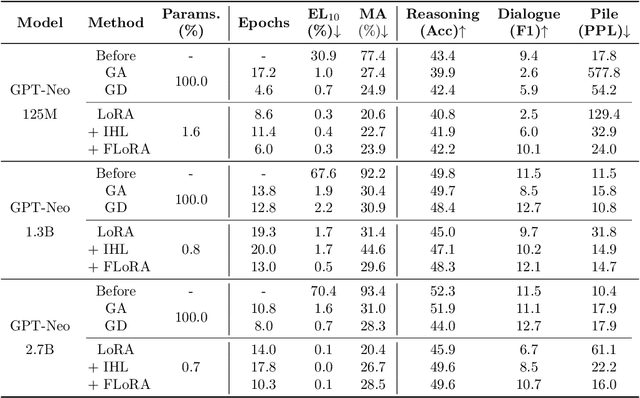
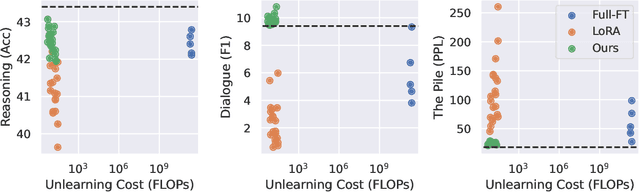
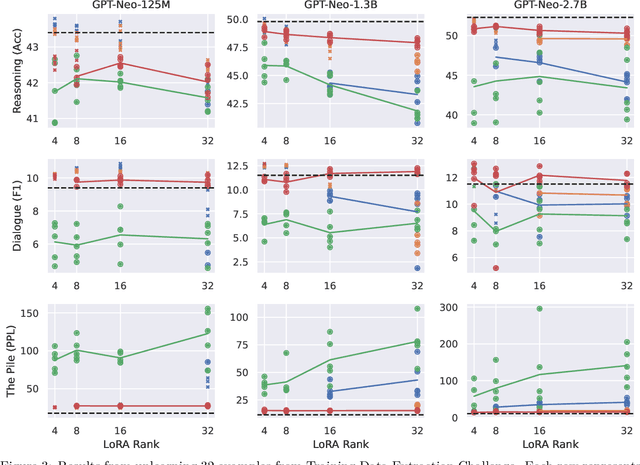
Large Language Models (LLMs) have demonstrated strong reasoning and memorization capabilities via pretraining on massive textual corpora. However, training LLMs on human-written text entails significant risk of privacy and copyright violations, which demands an efficient machine unlearning framework to remove knowledge of sensitive data without retraining the model from scratch. While Gradient Ascent (GA) is widely used for unlearning by reducing the likelihood of generating unwanted information, the unboundedness of increasing the cross-entropy loss causes not only unstable optimization, but also catastrophic forgetting of knowledge that needs to be retained. We also discover its joint application under low-rank adaptation results in significantly suboptimal computational cost vs. generative performance trade-offs. In light of this limitation, we propose two novel techniques for robust and cost-efficient unlearning on LLMs. We first design an Inverted Hinge loss that suppresses unwanted tokens by increasing the probability of the next most likely token, thereby retaining fluency and structure in language generation. We also propose to initialize low-rank adapter weights based on Fisher-weighted low-rank approximation, which induces faster unlearning and better knowledge retention by allowing model updates to be focused on parameters that are important in generating textual data we wish to remove.
Towards Realistic Incremental Scenario in Class Incremental Semantic Segmentation
May 16, 2024



This paper addresses the unrealistic aspect of the commonly adopted Continuous Incremental Semantic Segmentation (CISS) scenario, termed overlapped. We point out that overlapped allows the same image to reappear in future tasks with different pixel labels, which is far from practical incremental learning scenarios. Moreover, we identified that this flawed scenario may lead to biased results for two commonly used techniques in CISS, pseudo-labeling and exemplar memory, resulting in unintended advantages or disadvantages for certain techniques. To mitigate this, a practical scenario called partitioned is proposed, in which the dataset is first divided into distinct subsets representing each class, and then the subsets are assigned to each corresponding task. This efficiently addresses the issue above while meeting the requirement of CISS scenario, such as capturing the background shifts. Furthermore, we identify and address the code implementation issues related to retrieving data from the exemplar memory, which was ignored in previous works. Lastly, we introduce a simple yet competitive memory-based baseline, MiB-AugM, that handles background shifts of current tasks in the exemplar memory. This baseline achieves state-of-the-art results across multiple tasks involving learning numerous new classes.
Salience-Based Adaptive Masking: Revisiting Token Dynamics for Enhanced Pre-training
Apr 12, 2024In this paper, we introduce Saliency-Based Adaptive Masking (SBAM), a novel and cost-effective approach that significantly enhances the pre-training performance of Masked Image Modeling (MIM) approaches by prioritizing token salience. Our method provides robustness against variations in masking ratios, effectively mitigating the performance instability issues common in existing methods. This relaxes the sensitivity of MIM-based pre-training to masking ratios, which in turn allows us to propose an adaptive strategy for `tailored' masking ratios for each data sample, which no existing method can provide. Toward this goal, we propose an Adaptive Masking Ratio (AMR) strategy that dynamically adjusts the proportion of masking for the unique content of each image based on token salience. We show that our method significantly improves over the state-of-the-art in mask-based pre-training on the ImageNet-1K dataset.
Hyperparameters in Continual Learning: a Reality Check
Mar 14, 2024Various algorithms for continual learning (CL) have been designed with the goal of effectively alleviating the trade-off between stability and plasticity during the CL process. To achieve this goal, tuning appropriate hyperparameters for each algorithm is essential. As an evaluation protocol, it has been common practice to train a CL algorithm using diverse hyperparameter values on a CL scenario constructed with a benchmark dataset. Subsequently, the best performance attained with the optimal hyperparameter value serves as the criterion for evaluating the CL algorithm. In this paper, we contend that this evaluation protocol is not only impractical but also incapable of effectively assessing the CL capability of a CL algorithm. Returning to the fundamental principles of model evaluation in machine learning, we propose an evaluation protocol that involves Hyperparameter Tuning and Evaluation phases. Those phases consist of different datasets but share the same CL scenario. In the Hyperparameter Tuning phase, each algorithm is iteratively trained with different hyperparameter values to find the optimal hyperparameter values. Subsequently, in the Evaluation phase, the optimal hyperparameter values is directly applied for training each algorithm, and their performance in the Evaluation phase serves as the criterion for evaluating them. Through experiments on CIFAR-100 and ImageNet-100 based on the proposed protocol in class-incremental learning, we not only observed that the existing evaluation method fail to properly assess the CL capability of each algorithm but also observe that some recently proposed state-of-the-art algorithms, which reported superior performance, actually exhibit inferior performance compared to the previous algorithm.