 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
Aug 13, 2024
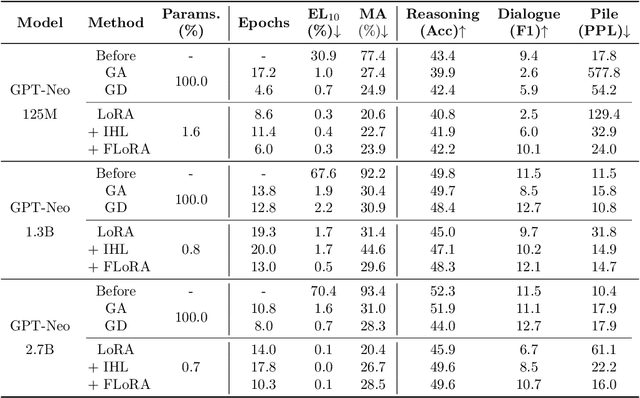
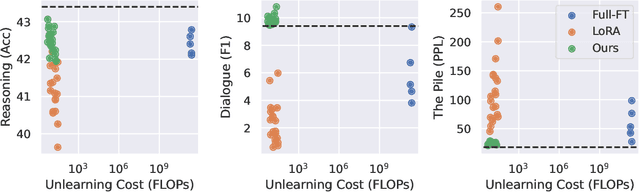
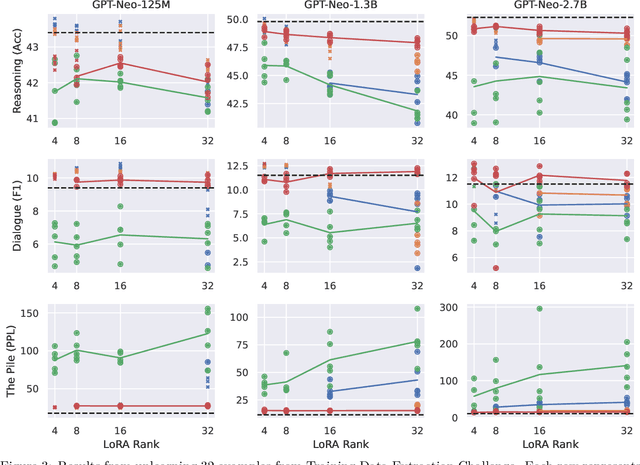
Large Language Models (LLMs) have demonstrated strong reasoning and memorization capabilities via pretraining on massive textual corpora. However, training LLMs on human-written text entails significant risk of privacy and copyright violations, which demands an efficient machine unlearning framework to remove knowledge of sensitive data without retraining the model from scratch. While Gradient Ascent (GA) is widely used for unlearning by reducing the likelihood of generating unwanted information, the unboundedness of increasing the cross-entropy loss causes not only unstable optimization, but also catastrophic forgetting of knowledge that needs to be retained. We also discover its joint application under low-rank adaptation results in significantly suboptimal computational cost vs. generative performance trade-offs. In light of this limitation, we propose two novel techniques for robust and cost-efficient unlearning on LLMs. We first design an Inverted Hinge loss that suppresses unwanted tokens by increasing the probability of the next most likely token, thereby retaining fluency and structure in language generation. We also propose to initialize low-rank adapter weights based on Fisher-weighted low-rank approximation, which induces faster unlearning and better knowledge retention by allowing model updates to be focused on parameters that are important in generating textual data we wish to remove.
Reinforcement Learning from Reflective Feedback (RLRF): Aligning and Improving LLMs via Fine-Grained Self-Reflection
Mar 21, 2024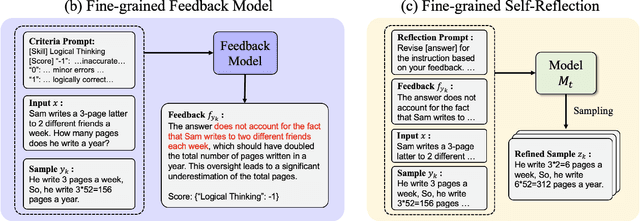
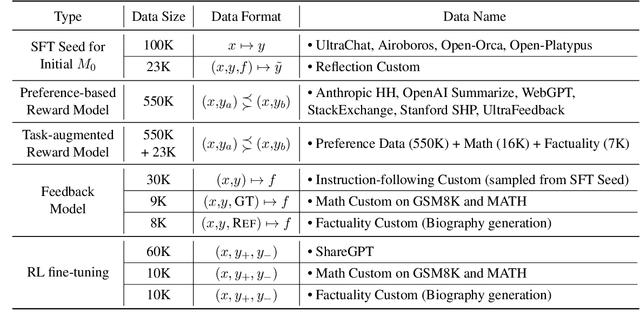
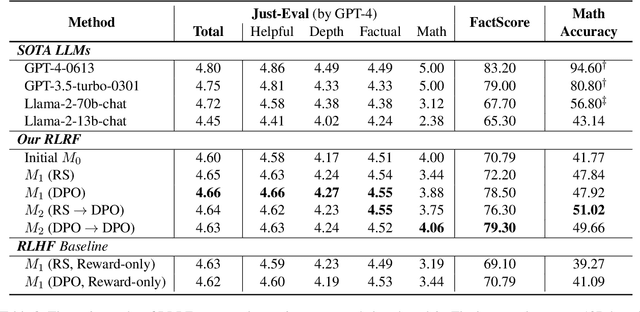

Despite the promise of RLHF in aligning LLMs with human preferences, it often leads to superficial alignment, prioritizing stylistic changes over improving downstream performance of LLMs. Underspecified preferences could obscure directions to align the models. Lacking exploration restricts identification of desirable outputs to improve the models. To overcome these challenges, we propose a novel framework: Reinforcement Learning from Reflective Feedback (RLRF), which leverages fine-grained feedback based on detailed criteria to improve the core capabilities of LLMs. RLRF employs a self-reflection mechanism to systematically explore and refine LLM responses, then fine-tuning the models via a RL algorithm along with promising responses. Our experiments across Just-Eval, Factuality, and Mathematical Reasoning demonstrate the efficacy and transformative potential of RLRF beyond superficial surface-level adjustment.
Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers
Jan 27, 2023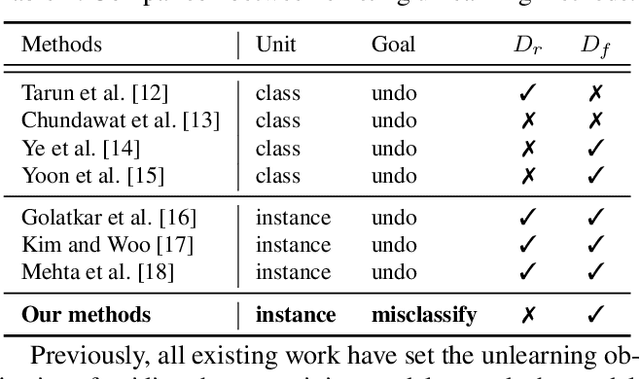
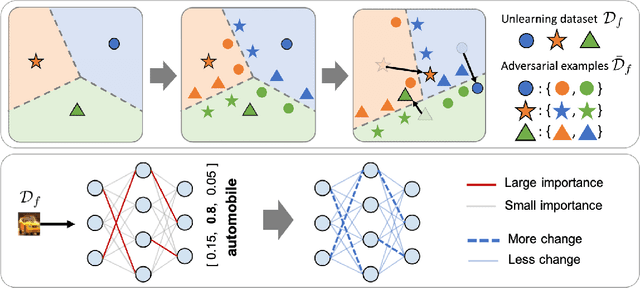
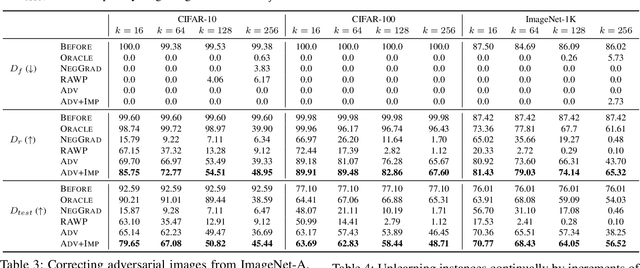
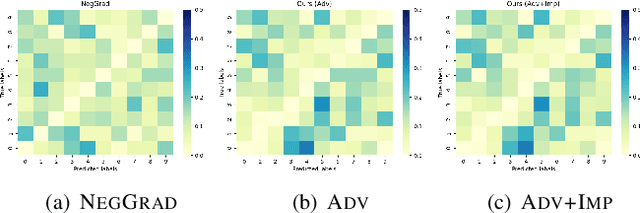
Since the recent advent of regulations for data protection (e.g., the General Data Protection Regulation), there has been increasing demand in deleting information learned from sensitive data in pre-trained models without retraining from scratch. The inherent vulnerability of neural networks towards adversarial attacks and unfairness also calls for a robust method to remove or correct information in an instance-wise fashion, while retaining the predictive performance across remaining data. To this end, we define instance-wise unlearning, of which the goal is to delete information on a set of instances from a pre-trained model, by either misclassifying each instance away from its original prediction or relabeling the instance to a different label. We also propose two methods that reduce forgetting on the remaining data: 1) utilizing adversarial examples to overcome forgetting at the representation-level and 2) leveraging weight importance metrics to pinpoint network parameters guilty of propagating unwanted information. Both methods only require the pre-trained model and data instances to forget, allowing painless application to real-life settings where the entire training set is unavailable. Through extensive experimentation on various image classification benchmarks, we show that our approach effectively preserves knowledge of remaining data while unlearning given instances in both single-task and continual unlearning scenarios.
Transferring Pre-trained Multimodal Representations with Cross-modal Similarity Matching
Jan 07, 2023



Despite surprising performance on zero-shot transfer, pre-training a large-scale multimodal model is often prohibitive as it requires a huge amount of data and computing resources. In this paper, we propose a method (BeamCLIP) that can effectively transfer the representations of a large pre-trained multimodal model (CLIP-ViT) into a small target model (e.g., ResNet-18). For unsupervised transfer, we introduce cross-modal similarity matching (CSM) that enables a student model to learn the representations of a teacher model by matching the relative similarity distribution across text prompt embeddings. To better encode the text prompts, we design context-based prompt augmentation (CPA) that can alleviate the lexical ambiguity of input text prompts. Our experiments show that unsupervised representation transfer of a pre-trained vision-language model enables a small ResNet-18 to achieve a better ImageNet-1K top-1 linear probe accuracy (66.2%) than vision-only self-supervised learning (SSL) methods (e.g., SimCLR: 51.8%, SwAV: 63.7%), while closing the gap with supervised learning (69.8%).
Point Cloud Augmentation with Weighted Local Transformations
Oct 11, 2021

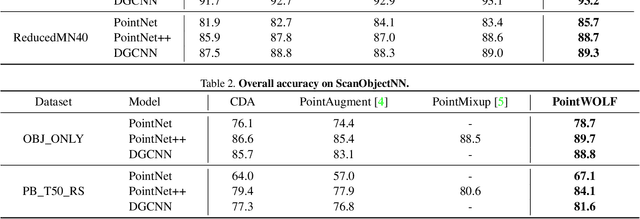
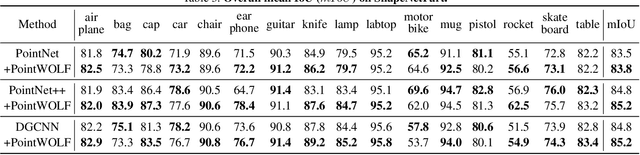
Despite the extensive usage of point clouds in 3D vision, relatively limited data are available for training deep neural networks. Although data augmentation is a standard approach to compensate for the scarcity of data, it has been less explored in the point cloud literature. In this paper, we propose a simple and effective augmentation method called PointWOLF for point cloud augmentation. The proposed method produces smoothly varying non-rigid deformations by locally weighted transformations centered at multiple anchor points. The smooth deformations allow diverse and realistic augmentations. Furthermore, in order to minimize the manual efforts to search the optimal hyperparameters for augmentation, we present AugTune, which generates augmented samples of desired difficulties producing targeted confidence scores. Our experiments show our framework consistently improves the performance for both shape classification and part segmentation tasks. Particularly, with PointNet++, PointWOLF achieves the state-of-the-art 89.7 accuracy on shape classification with the real-world ScanObjectNN dataset.
Self-supervised Auxiliary Learning for Graph Neural Networks via Meta-Learning
Mar 01, 2021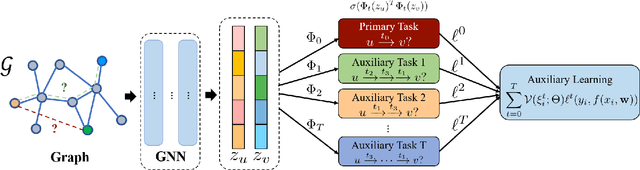
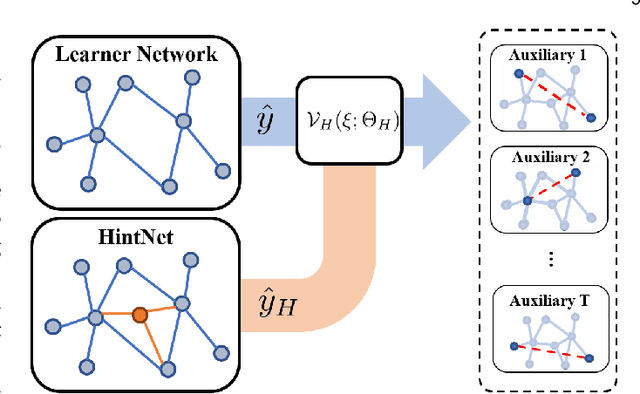

In recent years, graph neural networks (GNNs) have been widely adopted in representation learning of graph-structured data and provided state-of-the-art performance in various application such as link prediction and node classification. Simultaneously, self-supervised learning has been studied to some extent to leverage rich unlabeled data in representation learning on graphs. However, employing self-supervision tasks as auxiliary tasks to assist a primary task has been less explored in the literature on graphs. In this paper, we propose a novel self-supervised auxiliary learning framework to effectively learn graph neural networks. Moreover, we design first a meta-path prediction as a self-supervised auxiliary task for heterogeneous graphs. Our method is learning to learn a primary task with various auxiliary tasks to improve generalization performance. The proposed method identifies an effective combination of auxiliary tasks and automatically balances them to improve the primary task. Our methods can be applied to any graph neural networks in a plug-in manner without manual labeling or additional data. Also, it can be extended to any other auxiliary tasks. Our experiments demonstrate that the proposed method consistently improves the performance of link prediction and node classification on heterogeneous graphs.
Self-supervised Auxiliary Learning with Meta-paths for Heterogeneous Graphs
Aug 18, 2020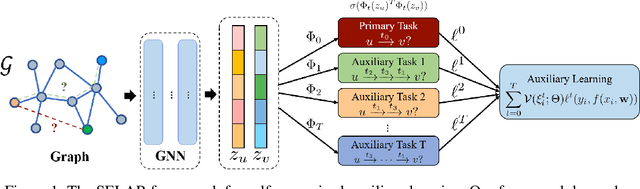

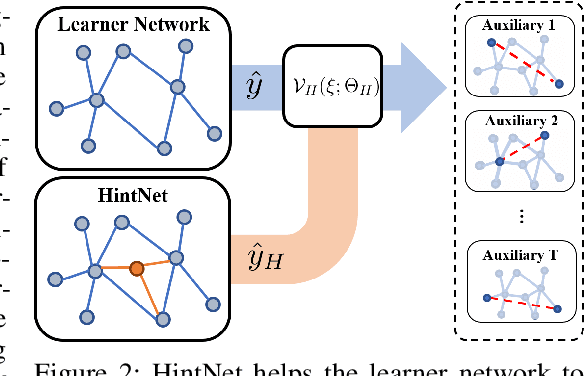
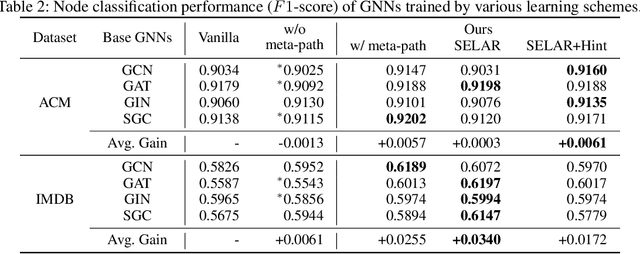
Graph neural networks have shown superior performance in a wide range of applications providing a powerful representation of graph-structured data. Recent works show that the representation can be further improved by auxiliary tasks. However, the auxiliary tasks for heterogeneous graphs, which contain rich semantic information with various types of nodes and edges, have less explored in the literature. In this paper, to learn graph neural networks on heterogeneous graphs we propose a novel self-supervised auxiliary learning method using meta-paths, which are composite relations of multiple edge types. Our proposed method is learning to learn a primary task by predicting meta-paths as auxiliary tasks. This can be viewed as a type of meta-learning. The proposed method can identify an effective combination of auxiliary tasks and automatically balance them to improve the primary task. Our methods can be applied to any graph neural networks in a plug-in manner without manual labeling or additional data. The experiments demonstrate that the proposed method consistently improves the performance of link prediction and node classification on heterogeneous graphs.