 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
Paper and Code
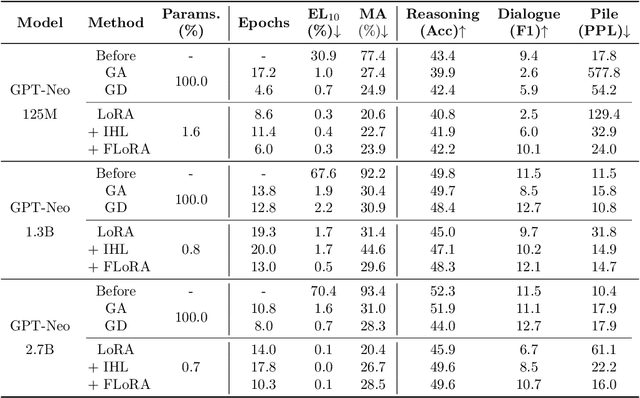
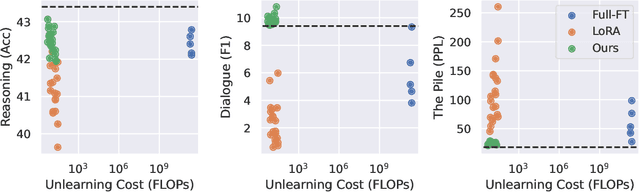
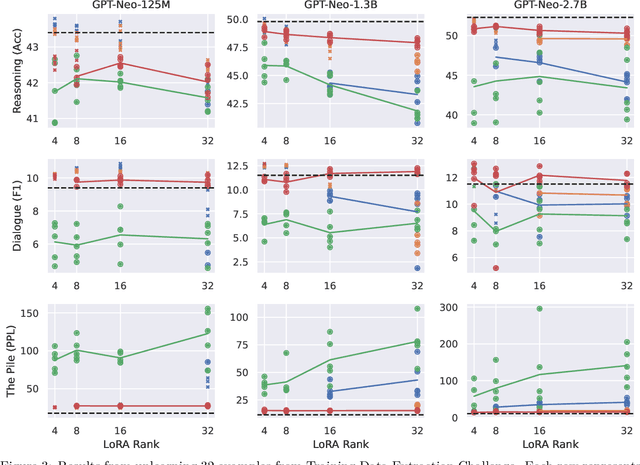
Large Language Models (LLMs) have demonstrated strong reasoning and memorization capabilities via pretraining on massive textual corpora. However, training LLMs on human-written text entails significant risk of privacy and copyright violations, which demands an efficient machine unlearning framework to remove knowledge of sensitive data without retraining the model from scratch. While Gradient Ascent (GA) is widely used for unlearning by reducing the likelihood of generating unwanted information, the unboundedness of increasing the cross-entropy loss causes not only unstable optimization, but also catastrophic forgetting of knowledge that needs to be retained. We also discover its joint application under low-rank adaptation results in significantly suboptimal computational cost vs. generative performance trade-offs. In light of this limitation, we propose two novel techniques for robust and cost-efficient unlearning on LLMs. We first design an Inverted Hinge loss that suppresses unwanted tokens by increasing the probability of the next most likely token, thereby retaining fluency and structure in language generation. We also propose to initialize low-rank adapter weights based on Fisher-weighted low-rank approximation, which induces faster unlearning and better knowledge retention by allowing model updates to be focused on parameters that are important in generating textual data we wish to remove.