 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelaunay Canopy: Building Wireframe Reconstruction from Airborne LiDAR Point Clouds via Delaunay Graph
Apr 02, 2026Reconstructing building wireframe from airborne LiDAR point clouds yields a compact, topology-centric representation that enables structural understanding beyond dense meshes. Yet a key limitation persists: conventional methods have failed to achieve accurate wireframe reconstruction in regions afflicted by significant noise, sparsity, or internal corners. This failure stems from the inability to establish an adaptive search space to effectively leverage the rich 3D geometry of large, sparse building point clouds. In this work, we address this challenge with Delaunay Canopy, which utilizes the Delaunay graph as a geometric prior to define a geometrically adaptive search space. Central to our approach is Delaunay Graph Scoring, which not only reconstructs the underlying geometric manifold but also yields region-wise curvature signatures to robustly guide the reconstruction. Built on this foundation, our corner and wire selection modules leverage the Delaunay-induced prior to focus on highly probable elements, thereby shaping the search space and enabling accurate prediction even in previously intractable regions. Extensive experiments on the Building3D Tallinn city and entry-level datasets demonstrate state-of-the-art wireframe reconstruction, delivering accurate predictions across diverse and complex building geometries.
FEAST: Fully Connected Expressive Attention for Spatial Transcriptomics
Mar 26, 2026Spatial Transcriptomics (ST) provides spatially-resolved gene expression, offering crucial insights into tissue architecture and complex diseases. However, its prohibitive cost limits widespread adoption, leading to significant attention on inferring spatial gene expression from readily available whole slide images. While graph neural networks have been proposed to model interactions between tissue regions, their reliance on pre-defined sparse graphs prevents them from considering potentially interacting spot pairs, resulting in a structural limitation in capturing complex biological relationships. To address this, we propose FEAST (Fully connected Expressive Attention for Spatial Transcriptomics), an attention-based framework that models the tissue as a fully connected graph, enabling the consideration of all pairwise interactions. To better reflect biological interactions, we introduce negative-aware attention, which models both excitatory and inhibitory interactions, capturing essential negative relationships that standard attention often overlooks. Furthermore, to mitigate the information loss from truncated or ignored context in standard spot image extraction, we introduce an off-grid sampling strategy that gathers additional images from intermediate regions, allowing the model to capture a richer morphological context. Experiments on public ST datasets show that FEAST surpasses state-of-the-art methods in gene expression prediction while providing biologically plausible attention maps that clarify positive and negative interactions. Our code is available at https://github.com/starforTJ/ FEAST.
ViKey: Enhancing Temporal Understanding in Videos via Visual Prompting
Mar 24, 2026Recent advancements in Video Large Language Models (VideoLLMs) have enabled strong performance across diverse multimodal video tasks. To reduce the high computational cost of processing dense video frames, efficiency-oriented methods such as frame selection have been widely adopted. While effective at minimizing redundancy, these methods often cause notable performance drops on tasks requiring temporal reasoning. Unlike humans, who can infer event progression from sparse visual cues, VideoLLMs frequently misinterpret temporal relations when intermediate frames are omitted. To address this limitation, we explore visual prompting (VP) as a lightweight yet effective way to enhance temporal understanding in VideoLLMs. Our analysis reveals that simply annotating each frame with explicit ordinal information helps the model perceive temporal continuity. This visual cue also supports frame-level referencing and mitigates positional ambiguity within a sparsely sampled sequence. Building on these insights, we introduce ViKey, a training-free framework that combines VP with a lightweight Keyword-Frame Mapping (KFM) module. KFM leverages frame indices as dictionary-like keys to link textual cues to the most relevant frames, providing explicit temporal anchors during inference. Despite its simplicity, our approach substantially improves temporal reasoning and, on some datasets, preserves dense-frame baseline performance with as few as 20% of frames.
Anchoring and Rescaling Attention for Semantically Coherent Inbetweening
Mar 18, 2026Generative inbetweening (GI) seeks to synthesize realistic intermediate frames between the first and last keyframes beyond mere interpolation. As sequences become sparser and motions larger, previous GI models struggle with inconsistent frames with unstable pacing and semantic misalignment. Since GI involves fixed endpoints and numerous plausible paths, this task requires additional guidance gained from the keyframes and text to specify the intended path. Thus, we give semantic and temporal guidance from the keyframes and text onto each intermediate frame through Keyframe-anchored Attention Bias. We also better enforce frame consistency with Rescaled Temporal RoPE, which allows self-attention to attend to keyframes more faithfully. TGI-Bench, the first benchmark specifically designed for text-conditioned GI evaluation, enables challenge-targeted evaluation to analyze GI models. Without additional training, our method achieves state-of-the-art frame consistency, semantic fidelity, and pace stability for both short and long sequences across diverse challenges.
Interpretable Motion-Attentive Maps: Spatio-Temporally Localizing Concepts in Video Diffusion Transformers
Mar 03, 2026Video Diffusion Transformers (DiTs) have been synthesizing high-quality video with high fidelity from given text descriptions involving motion. However, understanding how Video DiTs convert motion words into video remains insufficient. Furthermore, while prior studies on interpretable saliency maps primarily target objects, motion-related behavior in Video DiTs remains largely unexplored. In this paper, we investigate concrete motion features that specify when and which object moves for a given motion concept. First, to spatially localize, we introduce GramCol, which adaptively produces per-frame saliency maps for any text concept, including both motion and non-motion. Second, we propose a motion-feature selection algorithm to obtain an Interpretable Motion-Attentive Map (IMAP) that localizes motion spatially and temporally. Our method discovers concept saliency maps without the need for any gradient calculation or parameter update. Experimentally, our method shows outstanding localization capability on the motion localization task and zero-shot video semantic segmentation, providing interpretable and clearer saliency maps for both motion and non-motion concepts.
Mono-Modalizing Extremely Heterogeneous Multi-Modal Medical Image Registration
Jun 18, 2025In clinical practice, imaging modalities with functional characteristics, such as positron emission tomography (PET) and fractional anisotropy (FA), are often aligned with a structural reference (e.g., MRI, CT) for accurate interpretation or group analysis, necessitating multi-modal deformable image registration (DIR). However, due to the extreme heterogeneity of these modalities compared to standard structural scans, conventional unsupervised DIR methods struggle to learn reliable spatial mappings and often distort images. We find that the similarity metrics guiding these models fail to capture alignment between highly disparate modalities. To address this, we propose M2M-Reg (Multi-to-Mono Registration), a novel framework that trains multi-modal DIR models using only mono-modal similarity while preserving the established architectural paradigm for seamless integration into existing models. We also introduce GradCyCon, a regularizer that leverages M2M-Reg's cyclic training scheme to promote diffeomorphism. Furthermore, our framework naturally extends to a semi-supervised setting, integrating pre-aligned and unaligned pairs only, without requiring ground-truth transformations or segmentation masks. Experiments on the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate that M2M-Reg achieves up to 2x higher DSC than prior methods for PET-MRI and FA-MRI registration, highlighting its effectiveness in handling highly heterogeneous multi-modal DIR. Our code is available at https://github.com/MICV-yonsei/M2M-Reg.
Backbone Augmented Training for Adaptations
Jun 04, 2025



Adaptations facilitate efficient training of large backbone models, including diffusion models for image generation and transformer-based language models. While various adaptation techniques enhance performance with minimal computational resources, limited adaptation data often leads to challenges in training. To address this, we focus on the enormous amount of backbone data used to pre-train the backbone models. We propose Backbone Augmented Training (BAT), a method that leverages backbone data to augment the adaptation dataset. First, we formulate and prove two mathematical key propositions: one establishes the validity of BAT, while the other identifies a condition under which BAT benefits adaptation. Furthermore, we introduce an advanced data selection scheme that satisfies these propositions and present ALBAT algorithm to implement this approach. ALBAT efficiently enhances adaptation training in both personalization and language generation tasks with scarce data.
PRETI: Patient-Aware Retinal Foundation Model via Metadata-Guided Representation Learning
May 18, 2025Retinal foundation models have significantly advanced retinal image analysis by leveraging self-supervised learning to reduce dependence on labeled data while achieving strong generalization. Many recent approaches enhance retinal image understanding using report supervision, but obtaining clinical reports is often costly and challenging. In contrast, metadata (e.g., age, gender) is widely available and serves as a valuable resource for analyzing disease progression. To effectively incorporate patient-specific information, we propose PRETI, a retinal foundation model that integrates metadata-aware learning with robust self-supervised representation learning. We introduce Learnable Metadata Embedding (LME), which dynamically refines metadata representations. Additionally, we construct patient-level data pairs, associating images from the same individual to improve robustness against non-clinical variations. To further optimize retinal image representation, we propose Retina-Aware Adaptive Masking (RAAM), a strategy that selectively applies masking within the retinal region and dynamically adjusts the masking ratio during training. PRETI captures both global structures and fine-grained pathological details, resulting in superior diagnostic performance. Extensive experiments demonstrate that PRETI achieves state-of-the-art results across diverse diseases and biomarker predictions using in-house and public data, indicating the importance of metadata-guided foundation models in retinal disease analysis. Our code and pretrained model are available at https://github.com/MICV-yonsei/PRETI
Spatial Transport Optimization by Repositioning Attention Map for Training-Free Text-to-Image Synthesis
Mar 28, 2025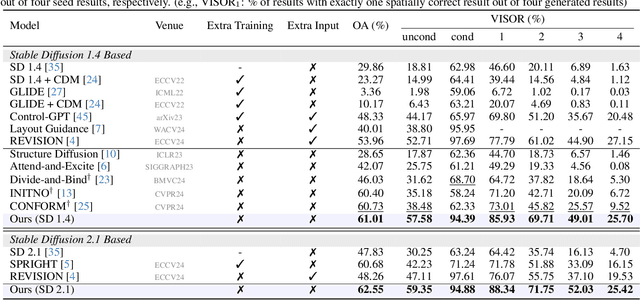

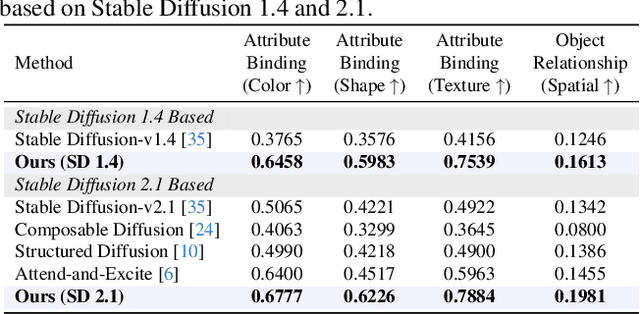
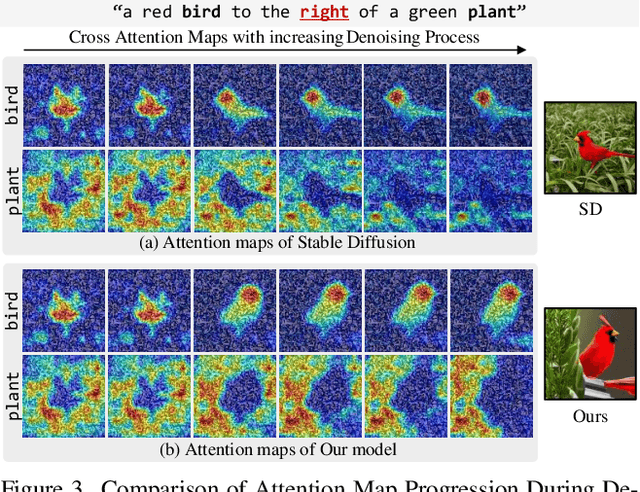
Diffusion-based text-to-image (T2I) models have recently excelled in high-quality image generation, particularly in a training-free manner, enabling cost-effective adaptability and generalization across diverse tasks. However, while the existing methods have been continuously focusing on several challenges, such as "missing objects" and "mismatched attributes," another critical issue of "mislocated objects" remains where generated spatial positions fail to align with text prompts. Surprisingly, ensuring such seemingly basic functionality remains challenging in popular T2I models due to the inherent difficulty of imposing explicit spatial guidance via text forms. To address this, we propose STORM (Spatial Transport Optimization by Repositioning Attention Map), a novel training-free approach for spatially coherent T2I synthesis. STORM employs Spatial Transport Optimization (STO), rooted in optimal transport theory, to dynamically adjust object attention maps for precise spatial adherence, supported by a Spatial Transport (ST) Cost function that enhances spatial understanding. Our analysis shows that integrating spatial awareness is most effective in the early denoising stages, while later phases refine details. Extensive experiments demonstrate that STORM surpasses existing methods, effectively mitigating mislocated objects while improving missing and mismatched attributes, setting a new benchmark for spatial alignment in T2I synthesis.
Rethinking Glaucoma Calibration: Voting-Based Binocular and Metadata Integration
Mar 24, 2025



Glaucoma is an incurable ophthalmic disease that damages the optic nerve, leads to vision loss, and ranks among the leading causes of blindness worldwide. Diagnosing glaucoma typically involves fundus photography, optical coherence tomography (OCT), and visual field testing. However, the high cost of OCT often leads to reliance on fundus photography and visual field testing, both of which exhibit inherent inter-observer variability. This stems from glaucoma being a multifaceted disease that influenced by various factors. As a result, glaucoma diagnosis is highly subjective, emphasizing the necessity of calibration, which aligns predicted probabilities with actual disease likelihood. Proper calibration is essential to prevent overdiagnosis or misdiagnosis, which are critical concerns for high-risk diseases. Although AI has significantly improved diagnostic accuracy, overconfidence in models have worsen calibration performance. Recent study has begun focusing on calibration for glaucoma. Nevertheless, previous study has not fully considered glaucoma's systemic nature and the high subjectivity in its diagnostic process. To overcome these limitations, we propose V-ViT (Voting-based ViT), a novel framework that enhances calibration by incorporating disease-specific characteristics. V-ViT integrates binocular data and metadata, reflecting the multi-faceted nature of glaucoma diagnosis. Additionally, we introduce a MC dropout-based Voting System to address high subjectivity. Our approach achieves state-of-the-art performance across all metrics, including accuracy, demonstrating that our proposed methods are effective in addressing calibration issues. We validate our method using a custom dataset including binocular data.