 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathology-Aware Adaptive Watermarking for Text-Driven Medical Image Synthesis
Mar 11, 2025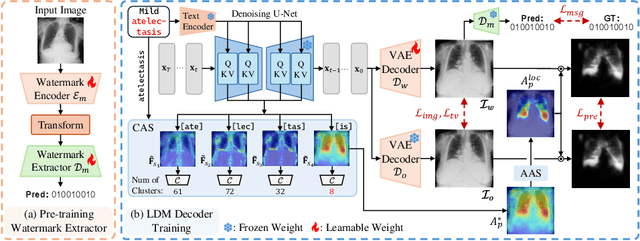
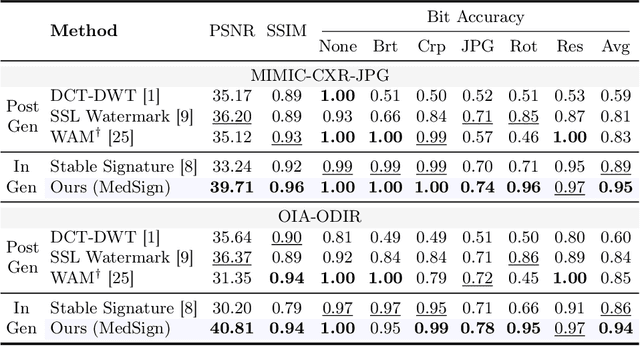
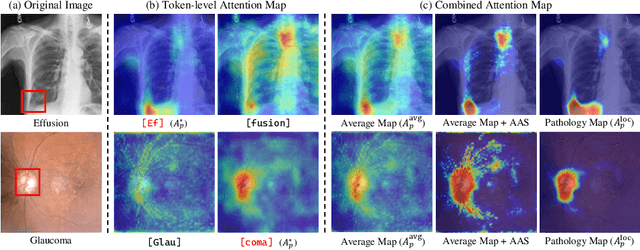
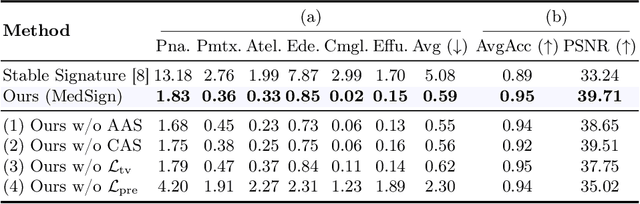
As recent text-conditioned diffusion models have enabled the generation of high-quality images, concerns over their potential misuse have also grown. This issue is critical in the medical domain, where text-conditioned generated medical images could enable insurance fraud or falsified records, highlighting the urgent need for reliable safeguards against unethical use. While watermarking techniques have emerged as a promising solution in general image domains, their direct application to medical imaging presents significant challenges. A key challenge is preserving fine-grained disease manifestations, as even minor distortions from a watermark may lead to clinical misinterpretation, which compromises diagnostic integrity. To overcome this gap, we present MedSign, a deep learning-based watermarking framework specifically designed for text-to-medical image synthesis, which preserves pathologically significant regions by adaptively adjusting watermark strength. Specifically, we generate a pathology localization map using cross-attention between medical text tokens and the diffusion denoising network, aggregating token-wise attention across layers, heads, and time steps. Leveraging this map, we optimize the LDM decoder to incorporate watermarking during image synthesis, ensuring cohesive integration while minimizing interference in diagnostically critical regions. Experimental results show that our MedSign preserves diagnostic integrity while ensuring watermark robustness, achieving state-of-the-art performance in image quality and detection accuracy on MIMIC-CXR and OIA-ODIR datasets.
GBT-SAM: A Parameter-Efficient Depth-Aware Model for Generalizable Brain tumour Segmentation on mp-MRI
Mar 07, 2025



Gliomas are brain tumours that stand out for their highly lethal and aggressive nature, which demands a precise approach in their diagnosis. Medical image segmentation plays a crucial role in the evaluation and follow-up of these tumours, allowing specialists to analyse their morphology. However, existing methods for automatic glioma segmentation often lack generalization capability across other brain tumour domains, require extensive computational resources, or fail to fully utilize the multi-parametric MRI (mp-MRI) data used to delineate them. In this work, we introduce GBT-SAM, a novel Generalizable Brain Tumour (GBT) framework that extends the Segment Anything Model (SAM) to brain tumour segmentation tasks. Our method employs a two-step training protocol: first, fine-tuning the patch embedding layer to process the entire mp-MRI modalities, and second, incorporating parameter-efficient LoRA blocks and a Depth-Condition block into the Vision Transformer (ViT) to capture inter-slice correlations. GBT-SAM achieves state-of-the-art performance on the Adult Glioma dataset (Dice Score of $93.54$) while demonstrating robust generalization across Meningioma, Pediatric Glioma, and Sub-Saharan Glioma datasets. Furthermore, GBT-SAM uses less than 6.5M trainable parameters, thus offering an efficient solution for brain tumour segmentation. \\ Our code and models are available at https://github.com/vpulab/med-sam-brain .
Leveraging Contrastive Learning for Semantic Segmentation with Consistent Labels Across Varying Appearances
Dec 21, 2024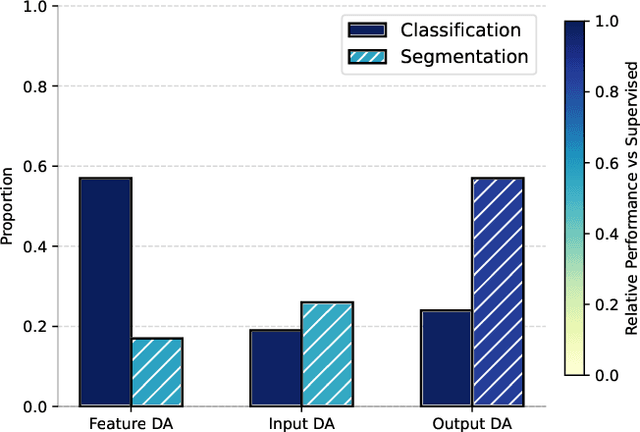


This paper introduces a novel synthetic dataset that captures urban scenes under a variety of weather conditions, providing pixel-perfect, ground-truth-aligned images to facilitate effective feature alignment across domains. Additionally, we propose a method for domain adaptation and generalization that takes advantage of the multiple versions of each scene, enforcing feature consistency across different weather scenarios. Our experimental results demonstrate the impact of our dataset in improving performance across several alignment metrics, addressing key challenges in domain adaptation and generalization for segmentation tasks. This research also explores critical aspects of synthetic data generation, such as optimizing the balance between the volume and variability of generated images to enhance segmentation performance. Ultimately, this work sets forth a new paradigm for synthetic data generation and domain adaptation.
VLMs meet UDA: Boosting Transferability of Open Vocabulary Segmentation with Unsupervised Domain Adaptation
Dec 12, 2024



Segmentation models are typically constrained by the categories defined during training. To address this, researchers have explored two independent approaches: adapting Vision-Language Models (VLMs) and leveraging synthetic data. However, VLMs often struggle with granularity, failing to disentangle fine-grained concepts, while synthetic data-based methods remain limited by the scope of available datasets. This paper proposes enhancing segmentation accuracy across diverse domains by integrating Vision-Language reasoning with key strategies for Unsupervised Domain Adaptation (UDA). First, we improve the fine-grained segmentation capabilities of VLMs through multi-scale contextual data, robust text embeddings with prompt augmentation, and layer-wise fine-tuning in our proposed Foundational-Retaining Open Vocabulary Semantic Segmentation (FROVSS) framework. Next, we incorporate these enhancements into a UDA framework by employing distillation to stabilize training and cross-domain mixed sampling to boost adaptability without compromising generalization. The resulting UDA-FROVSS framework is the first UDA approach to effectively adapt across domains without requiring shared categories.
Layer-wise Model Merging for Unsupervised Domain Adaptation in Segmentation Tasks
Sep 24, 2024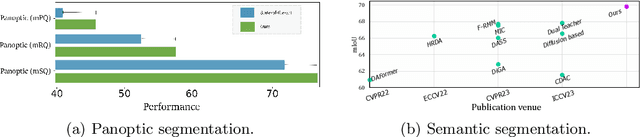
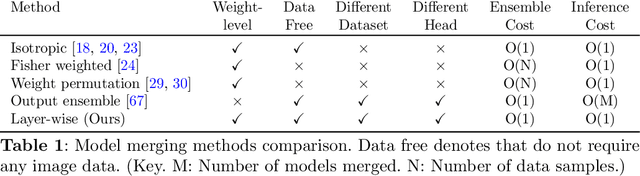
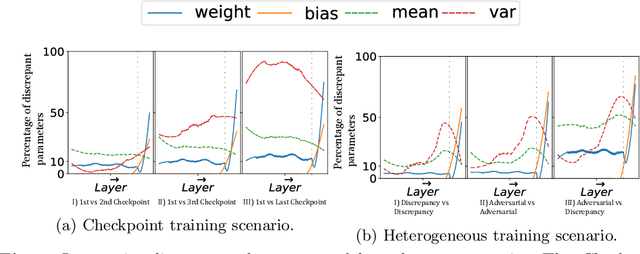
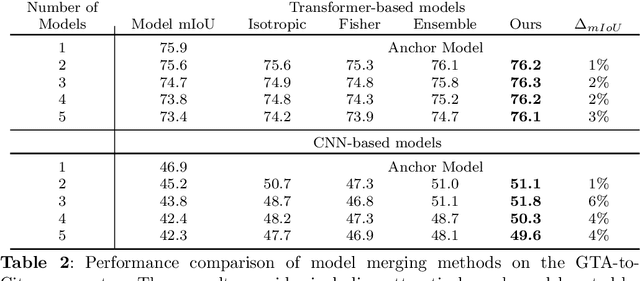
Merging parameters of multiple models has resurfaced as an effective strategy to enhance task performance and robustness, but prior work is limited by the high costs of ensemble creation and inference. In this paper, we leverage the abundance of freely accessible trained models to introduce a cost-free approach to model merging. It focuses on a layer-wise integration of merged models, aiming to maintain the distinctiveness of the task-specific final layers while unifying the initial layers, which are primarily associated with feature extraction. This approach ensures parameter consistency across all layers, essential for boosting performance. Moreover, it facilitates seamless integration of knowledge, enabling effective merging of models from different datasets and tasks. Specifically, we investigate its applicability in Unsupervised Domain Adaptation (UDA), an unexplored area for model merging, for Semantic and Panoptic Segmentation. Experimental results demonstrate substantial UDA improvements without additional costs for merging same-architecture models from distinct datasets ($\uparrow 2.6\%$ mIoU) and different-architecture models with a shared backbone ($\uparrow 6.8\%$ mIoU). Furthermore, merging Semantic and Panoptic Segmentation models increases mPQ by $\uparrow 7\%$. These findings are validated across a wide variety of UDA strategies, architectures, and datasets.
Gradient-based Class Weighting for Unsupervised Domain Adaptation in Dense Prediction Visual Tasks
Jul 01, 2024



In unsupervised domain adaptation (UDA), where models are trained on source data (e.g., synthetic) and adapted to target data (e.g., real-world) without target annotations, addressing the challenge of significant class imbalance remains an open issue. Despite considerable progress in bridging the domain gap, existing methods often experience performance degradation when confronted with highly imbalanced dense prediction visual tasks like semantic and panoptic segmentation. This discrepancy becomes especially pronounced due to the lack of equivalent priors between the source and target domains, turning class imbalanced techniques used for other areas (e.g., image classification) ineffective in UDA scenarios. This paper proposes a class-imbalance mitigation strategy that incorporates class-weights into the UDA learning losses, but with the novelty of estimating these weights dynamically through the loss gradient, defining a Gradient-based class weighting (GBW) learning. GBW naturally increases the contribution of classes whose learning is hindered by large-represented classes, and has the advantage of being able to automatically and quickly adapt to the iteration training outcomes, avoiding explicitly curricular learning patterns common in loss-weighing strategies. Extensive experimentation validates the effectiveness of GBW across architectures (convolutional and transformer), UDA strategies (adversarial, self-training and entropy minimization), tasks (semantic and panoptic segmentation), and datasets (GTA and Synthia). Analysing the source of advantage, GBW consistently increases the recall of low represented classes.
Open-Vocabulary Attention Maps with Token Optimization for Semantic Segmentation in Diffusion Models
Mar 21, 2024



Diffusion models represent a new paradigm in text-to-image generation. Beyond generating high-quality images from text prompts, models such as Stable Diffusion have been successfully extended to the joint generation of semantic segmentation pseudo-masks. However, current extensions primarily rely on extracting attentions linked to prompt words used for image synthesis. This approach limits the generation of segmentation masks derived from word tokens not contained in the text prompt. In this work, we introduce Open-Vocabulary Attention Maps (OVAM)-a training-free method for text-to-image diffusion models that enables the generation of attention maps for any word. In addition, we propose a lightweight optimization process based on OVAM for finding tokens that generate accurate attention maps for an object class with a single annotation. We evaluate these tokens within existing state-of-the-art Stable Diffusion extensions. The best-performing model improves its mIoU from 52.1 to 86.6 for the synthetic images' pseudo-masks, demonstrating that our optimized tokens are an efficient way to improve the performance of existing methods without architectural changes or retraining.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Soft labelling for semantic segmentation: Bringing coherence to label down-sampling
Mar 08, 2023



In semantic segmentation, training data down-sampling is commonly performed due to limited resources, the need to adapt image size to the model input, or improve data augmentation. This down-sampling typically employs different strategies for the image data and the annotated labels. Such discrepancy leads to mismatches between the down-sampled color and label images. Hence, the training performance significantly decreases as the down-sampling factor increases. In this paper, we bring together the down-sampling strategies for the image data and the training labels. To that aim, we propose a novel framework for label down-sampling via soft-labeling that better conserves label information after down-sampling. Therefore, fully aligning soft-labels with image data to keep the distribution of the sampled pixels. This proposal also produces reliable annotations for under-represented semantic classes. Altogether, it allows training competitive models at lower resolutions. Experiments show that the proposal outperforms other down-sampling strategies. Moreover, state-of-the-art performance is achieved for reference benchmarks, but employing significantly less computational resources than foremost approaches. This proposal enables competitive research for semantic segmentation under resource constraints.