 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBT-SAM: A Parameter-Efficient Depth-Aware Model for Generalizable Brain tumour Segmentation on mp-MRI
Mar 07, 2025



Gliomas are brain tumours that stand out for their highly lethal and aggressive nature, which demands a precise approach in their diagnosis. Medical image segmentation plays a crucial role in the evaluation and follow-up of these tumours, allowing specialists to analyse their morphology. However, existing methods for automatic glioma segmentation often lack generalization capability across other brain tumour domains, require extensive computational resources, or fail to fully utilize the multi-parametric MRI (mp-MRI) data used to delineate them. In this work, we introduce GBT-SAM, a novel Generalizable Brain Tumour (GBT) framework that extends the Segment Anything Model (SAM) to brain tumour segmentation tasks. Our method employs a two-step training protocol: first, fine-tuning the patch embedding layer to process the entire mp-MRI modalities, and second, incorporating parameter-efficient LoRA blocks and a Depth-Condition block into the Vision Transformer (ViT) to capture inter-slice correlations. GBT-SAM achieves state-of-the-art performance on the Adult Glioma dataset (Dice Score of $93.54$) while demonstrating robust generalization across Meningioma, Pediatric Glioma, and Sub-Saharan Glioma datasets. Furthermore, GBT-SAM uses less than 6.5M trainable parameters, thus offering an efficient solution for brain tumour segmentation. \\ Our code and models are available at https://github.com/vpulab/med-sam-brain .
SynthmanticLiDAR: A Synthetic Dataset for Semantic Segmentation on LiDAR Imaging
Jan 31, 2025



Semantic segmentation on LiDAR imaging is increasingly gaining attention, as it can provide useful knowledge for perception systems and potential for autonomous driving. However, collecting and labeling real LiDAR data is an expensive and time-consuming task. While datasets such as SemanticKITTI have been manually collected and labeled, the introduction of simulation tools such as CARLA, has enabled the creation of synthetic datasets on demand. In this work, we present a modified CARLA simulator designed with LiDAR semantic segmentation in mind, with new classes, more consistent object labeling with their counterparts from real datasets such as SemanticKITTI, and the possibility to adjust the object class distribution. Using this tool, we have generated SynthmanticLiDAR, a synthetic dataset for semantic segmentation on LiDAR imaging, designed to be similar to SemanticKITTI, and we evaluate its contribution to the training process of different semantic segmentation algorithms by using a naive transfer learning approach. Our results show that incorporating SynthmanticLiDAR into the training process improves the overall performance of tested algorithms, proving the usefulness of our dataset, and therefore, our adapted CARLA simulator. The dataset and simulator are available in https://github.com/vpulab/SynthmanticLiDAR.
* 2024 IEEE International Conference on Image Processing (ICIP)
Unsupervised Class Generation to Expand Semantic Segmentation Datasets
Jan 04, 2025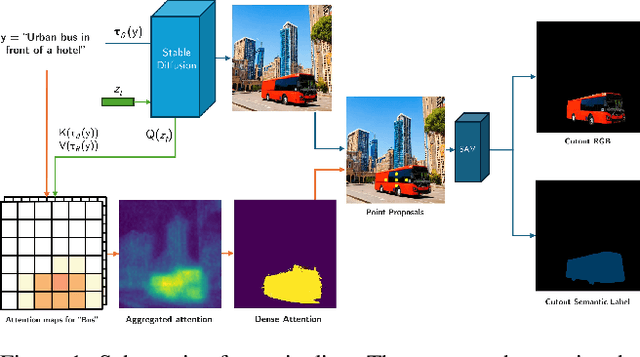
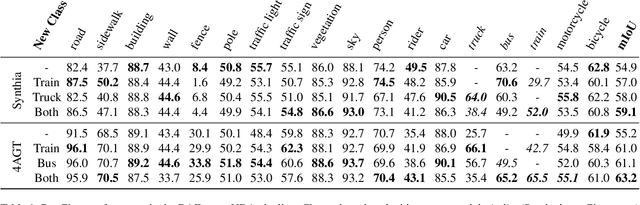

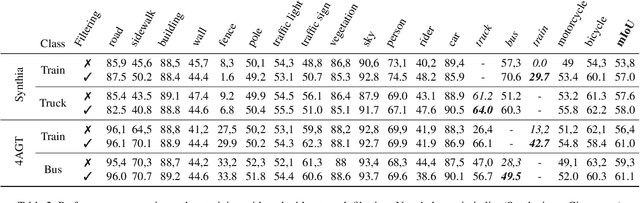
Semantic segmentation is a computer vision task where classification is performed at a pixel level. Due to this, the process of labeling images for semantic segmentation is time-consuming and expensive. To mitigate this cost there has been a surge in the use of synthetically generated data -- usually created using simulators or videogames -- which, in combination with domain adaptation methods, can effectively learn how to segment real data. Still, these datasets have a particular limitation: due to their closed-set nature, it is not possible to include novel classes without modifying the tool used to generate them, which is often not public. Concurrently, generative models have made remarkable progress, particularly with the introduction of diffusion models, enabling the creation of high-quality images from text prompts without additional supervision. In this work, we propose an unsupervised pipeline that leverages Stable Diffusion and Segment Anything Module to generate class examples with an associated segmentation mask, and a method to integrate generated cutouts for novel classes in semantic segmentation datasets, all with minimal user input. Our approach aims to improve the performance of unsupervised domain adaptation methods by introducing novel samples into the training data without modifications to the underlying algorithms. With our methods, we show how models can not only effectively learn how to segment novel classes, with an average performance of 51% IoU, but also reduce errors for other, already existing classes, reaching a higher performance level overall.
Leveraging Contrastive Learning for Semantic Segmentation with Consistent Labels Across Varying Appearances
Dec 21, 2024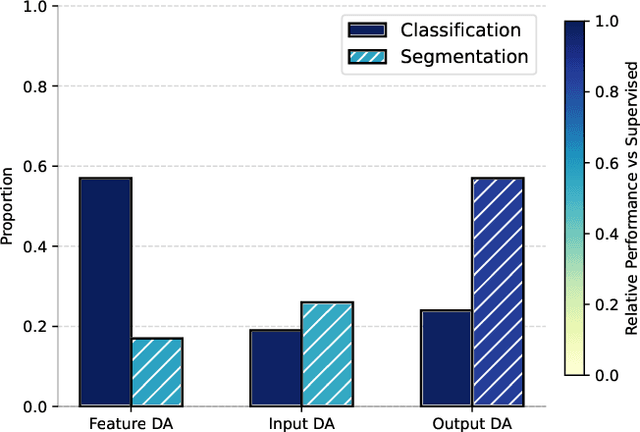


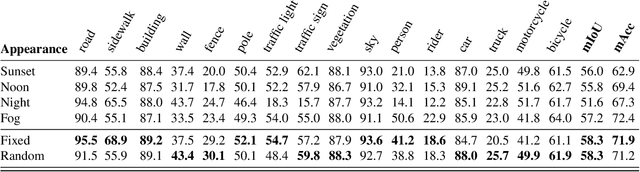
This paper introduces a novel synthetic dataset that captures urban scenes under a variety of weather conditions, providing pixel-perfect, ground-truth-aligned images to facilitate effective feature alignment across domains. Additionally, we propose a method for domain adaptation and generalization that takes advantage of the multiple versions of each scene, enforcing feature consistency across different weather scenarios. Our experimental results demonstrate the impact of our dataset in improving performance across several alignment metrics, addressing key challenges in domain adaptation and generalization for segmentation tasks. This research also explores critical aspects of synthetic data generation, such as optimizing the balance between the volume and variability of generated images to enhance segmentation performance. Ultimately, this work sets forth a new paradigm for synthetic data generation and domain adaptation.
Test-Time Adaptation for Keypoint-Based Spacecraft Pose Estimation Based on Predicted-View Synthesis
Oct 05, 2024Due to the difficulty of replicating the real conditions during training, supervised algorithms for spacecraft pose estimation experience a drop in performance when trained on synthetic data and applied to real operational data. To address this issue, we propose a test-time adaptation approach that leverages the temporal redundancy between images acquired during close proximity operations. Our approach involves extracting features from sequential spacecraft images, estimating their poses, and then using this information to synthesise a reconstructed view. We establish a self-supervised learning objective by comparing the synthesised view with the actual one. During training, we supervise both pose estimation and image synthesis, while at test-time, we optimise the self-supervised objective. Additionally, we introduce a regularisation loss to prevent solutions that are not consistent with the keypoint structure of the spacecraft. Our code is available at: https://github.com/JotaBravo/spacecraft-tta.
* Preprint
SPIN: Spacecraft Imagery for Navigation
Jun 12, 2024


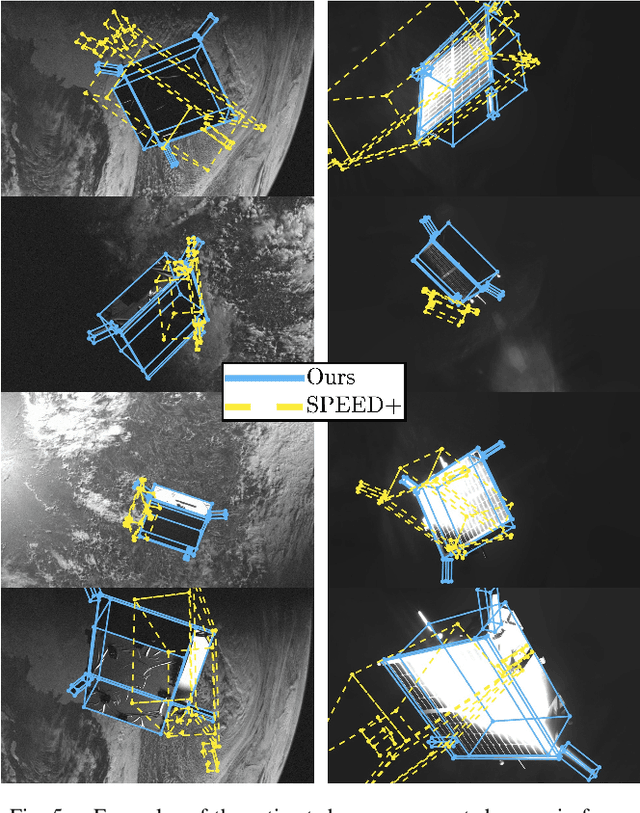
Data acquired in space operational conditions is scarce due to the costs and complexity of space operations. This poses a challenge to learning-based visual-based navigation algorithms employed in autonomous spacecraft navigation. Existing datasets, which largely depend on computer-simulated data, have partially filled this gap. However, the image generation tools they use are proprietary, which limits the evaluation of methods to unseen scenarios. Furthermore, these datasets provide limited ground-truth data, primarily focusing on the spacecraft's translation and rotation relative to the camera. To address these limitations, we present SPIN (SPacecraft Imagery for Navigation), an open-source realistic spacecraft image generation tool for relative navigation between two spacecrafts. SPIN provides a wide variety of ground-truth data and allows researchers to employ custom 3D models of satellites, define specific camera-relative poses, and adjust various settings such as camera parameters and environmental illumination conditions. For the task of spacecraft pose estimation, we compare the results of training with a SPIN-generated dataset against existing synthetic datasets. We show a %50 average error reduction in common testbed data (that simulates realistic space conditions). Both the SPIN tool (and source code) and our enhanced version of the synthetic datasets will be publicly released upon paper acceptance on GitHub https://github.com/vpulab/SPIN.
Spacecraft Pose Estimation Based on Unsupervised Domain Adaptation and on a 3D-Guided Loss Combination
Dec 27, 2022Spacecraft pose estimation is a key task to enable space missions in which two spacecrafts must navigate around each other. Current state-of-the-art algorithms for pose estimation employ data-driven techniques. However, there is an absence of real training data for spacecraft imaged in space conditions due to the costs and difficulties associated with the space environment. This has motivated the introduction of 3D data simulators, solving the issue of data availability but introducing a large gap between the training (source) and test (target) domains. We explore a method that incorporates 3D structure into the spacecraft pose estimation pipeline to provide robustness to intensity domain shift and we present an algorithm for unsupervised domain adaptation with robust pseudo-labelling. Our solution has ranked second in the two categories of the 2021 Pose Estimation Challenge organised by the European Space Agency and the Stanford University, achieving the lowest average error over the two categories.
Semantic-Aware Scene Recognition
Sep 06, 2019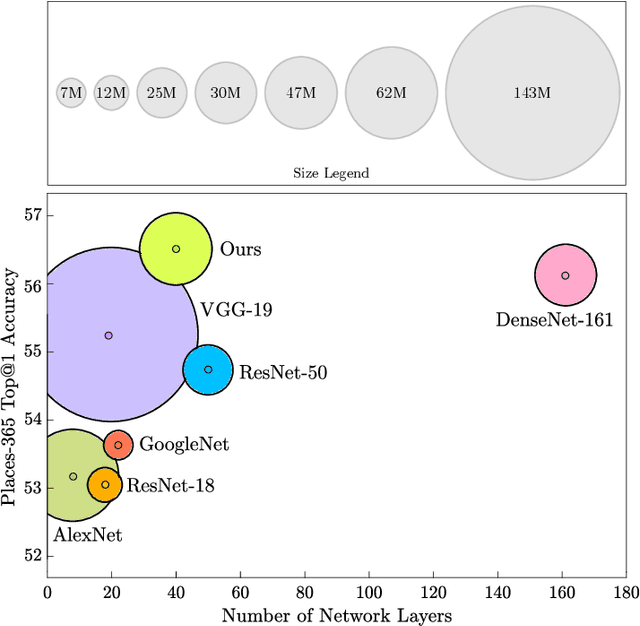
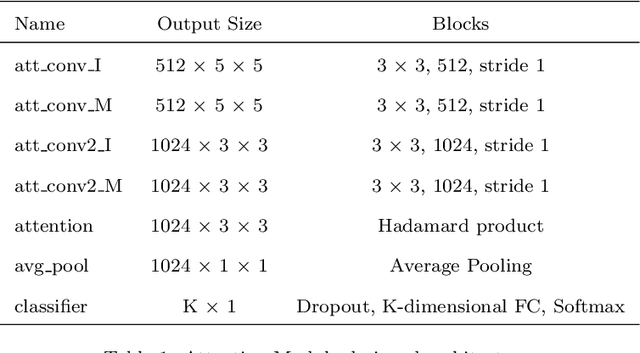

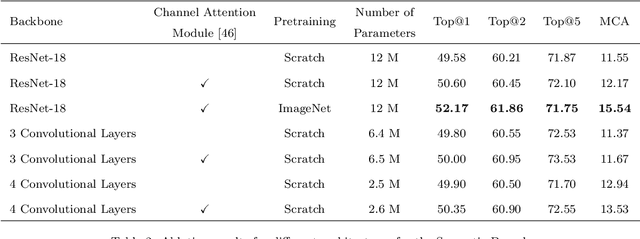
Scene recognition is currently one of the top-challenging research fields in computer vision. This may be due to the ambiguity between classes: images of several scene classes may share similar objects, which causes confusion among them. The problem is aggravated when images of a particular scene class are notably different. Convolutional Neural Networks (CNNs) have significantly boosted performance in scene recognition, albeit it is still far below from other recognition tasks (e.g., object or image recognition). In this paper, we describe a novel approach for scene recognition based on an end-to-end multi-modal CNN that combines image and context information by means of an attention module. Context information, in the shape of semantic segmentation, is used to gate features extracted from the RGB image by leveraging on information encoded in the semantic representation: the set of scene objects and stuff, and their relative locations. This gating process reinforces the learning of indicative scene content and enhances scene disambiguation by refocusing the receptive fields of the CNN towards them. Experimental results on four publicly available datasets show that the proposed approach outperforms every other state-of-the-art method while significantly reducing the number of network parameters. All the code and data used along this paper is available at https://github.com/vpulab/Semantic-Aware-Scene-Recognition