 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of a DCT-driven Loss in Attention-based Knowledge-Distillation for Scene Recognition
May 04, 2022

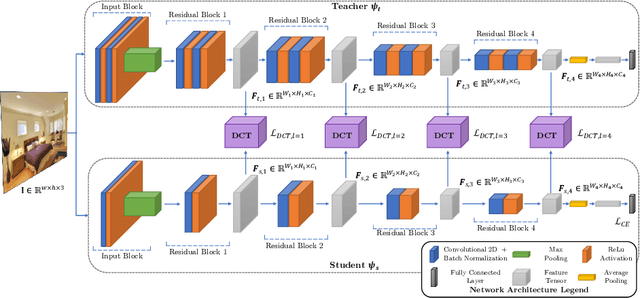
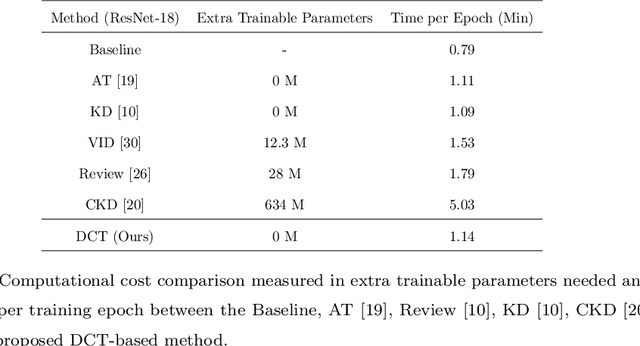
Knowledge Distillation (KD) is a strategy for the definition of a set of transferability gangways to improve the efficiency of Convolutional Neural Networks. Feature-based Knowledge Distillation is a subfield of KD that relies on intermediate network representations, either unaltered or depth-reduced via maximum activation maps, as the source knowledge. In this paper, we propose and analyse the use of a 2D frequency transform of the activation maps before transferring them. We pose that\textemdash by using global image cues rather than pixel estimates, this strategy enhances knowledge transferability in tasks such as scene recognition, defined by strong spatial and contextual relationships between multiple and varied concepts. To validate the proposed method, an extensive evaluation of the state-of-the-art in scene recognition is presented. Experimental results provide strong evidences that the proposed strategy enables the student network to better focus on the relevant image areas learnt by the teacher network, hence leading to better descriptive features and higher transferred performance than every other state-of-the-art alternative. We publicly release the training and evaluation framework used along this paper at http://www-vpu.eps.uam.es/publications/DCTBasedKDForSceneRecognition.
A Prospective Study on Sequence-Driven Temporal Sampling and Ego-Motion Compensation for Action Recognition in the EPIC-Kitchens Dataset
Aug 26, 2020


Action recognition is currently one of the top-challenging research fields in computer vision. Convolutional Neural Networks (CNNs) have significantly boosted its performance but rely on fixed-size spatio-temporal windows of analysis, reducing CNNs temporal receptive fields. Among action recognition datasets, egocentric recorded sequences have become of important relevance while entailing an additional challenge: ego-motion is unavoidably transferred to these sequences. The proposed method aims to cope with it by estimating this ego-motion or camera motion. The estimation is used to temporally partition video sequences into motion-compensated temporal \textit{chunks} showing the action under stable backgrounds and allowing for a content-driven temporal sampling. A CNN trained in an end-to-end fashion is used to extract temporal features from each \textit{chunk}, which are late fused. This process leads to the extraction of features from the whole temporal range of an action, increasing the temporal receptive field of the network.
Semantic-Aware Scene Recognition
Sep 06, 2019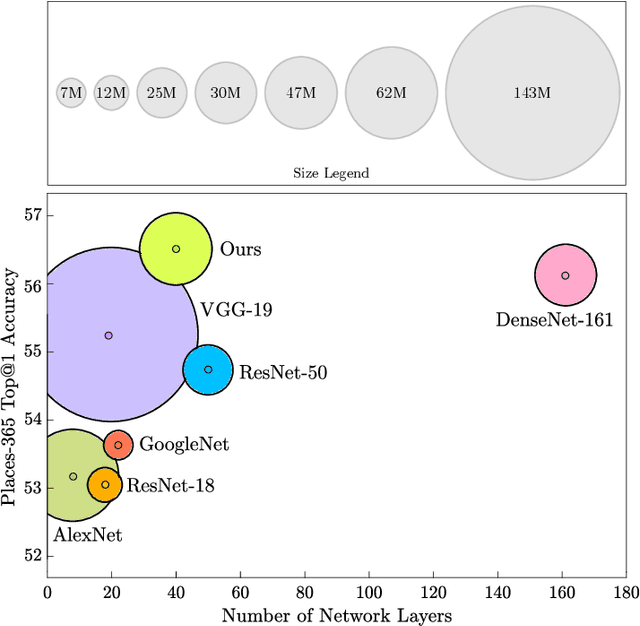
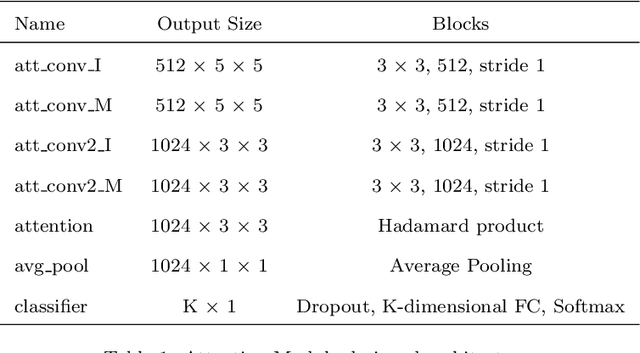

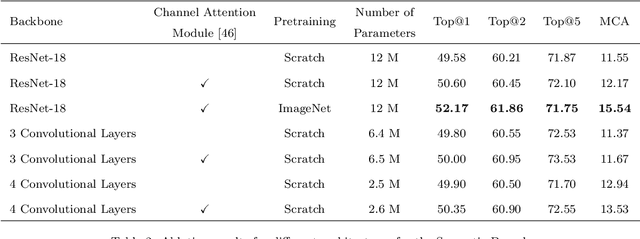
Scene recognition is currently one of the top-challenging research fields in computer vision. This may be due to the ambiguity between classes: images of several scene classes may share similar objects, which causes confusion among them. The problem is aggravated when images of a particular scene class are notably different. Convolutional Neural Networks (CNNs) have significantly boosted performance in scene recognition, albeit it is still far below from other recognition tasks (e.g., object or image recognition). In this paper, we describe a novel approach for scene recognition based on an end-to-end multi-modal CNN that combines image and context information by means of an attention module. Context information, in the shape of semantic segmentation, is used to gate features extracted from the RGB image by leveraging on information encoded in the semantic representation: the set of scene objects and stuff, and their relative locations. This gating process reinforces the learning of indicative scene content and enhances scene disambiguation by refocusing the receptive fields of the CNN towards them. Experimental results on four publicly available datasets show that the proposed approach outperforms every other state-of-the-art method while significantly reducing the number of network parameters. All the code and data used along this paper is available at https://github.com/vpulab/Semantic-Aware-Scene-Recognition
Semantic Driven Multi-Camera Pedestrian Detection
Dec 27, 2018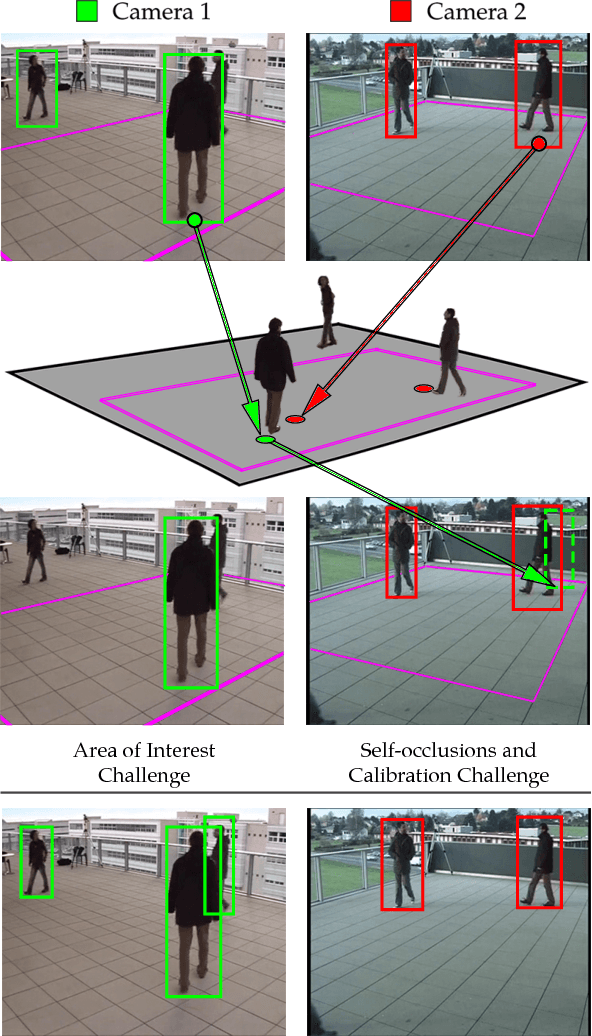
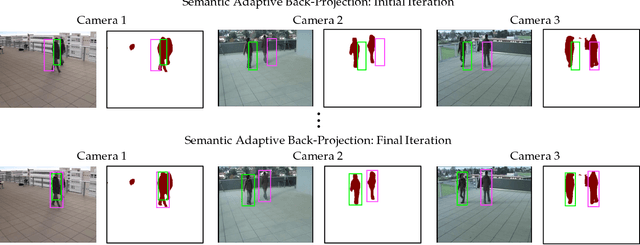

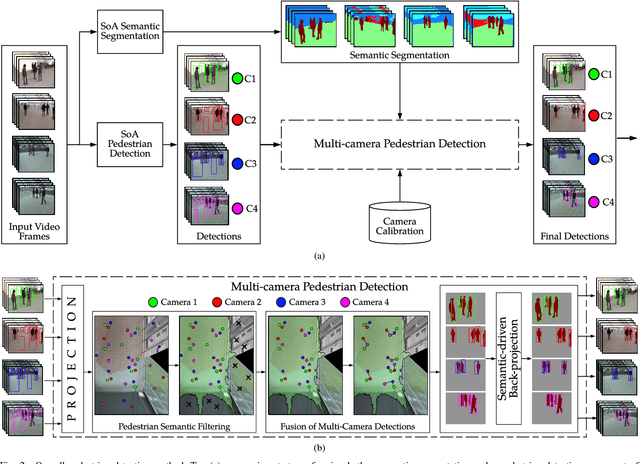
Nowadays, pedestrian detection is one of the pivotal fields in computer vision, especially when performed over video surveillance scenarios. People detection methods are highly sensitive to occlusions among pedestrians, which dramatically degrades performance in crowded scenarios. The cutback in camera prices has allowed generalizing multi-camera set-ups, which can better confront occlusions by using different points of view to disambiguate detections. In this paper we present an approach to improve the performance of these multi-camera systems and to make them independent of the considered scenario, via an automatic understanding of the scene content. This semantic information, obtained from a semantic segmentation, is used 1) to automatically generate a common Area of Interest for all cameras, instead of the usual manual definition of this area; and 2) to improve the 2D detections of each camera via an optimization technique which maximizes coherence of every detection both in all 2D views and in the 3D world, obtaining best-fitted bounding boxes and a consensus height for every pedestrian. Experimental results on five publicly available datasets show that the proposed approach, which does not require any training stage, outperforms state-of-the-art multi-camera pedestrian detectors non specifically trained for these datasets, which demonstrates the expected semantic-based robustness to different scenarios.