 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Meet Extreme Multi-label Classification: Scaling and Multi-modal Framework
Nov 17, 2025Foundation models have revolutionized artificial intelligence across numerous domains, yet their transformative potential remains largely untapped in Extreme Multi-label Classification (XMC). Queries in XMC are associated with relevant labels from extremely large label spaces, where it is critical to strike a balance between efficiency and performance. Therefore, many recent approaches efficiently pose XMC as a maximum inner product search between embeddings learned from small encoder-only transformer architectures. In this paper, we address two important aspects in XMC: how to effectively harness larger decoder-only models, and how to exploit visual information while maintaining computational efficiency. We demonstrate that both play a critical role in XMC separately and can be combined for improved performance. We show that a few billion-size decoder can deliver substantial improvements while keeping computational overhead manageable. Furthermore, our Vision-enhanced eXtreme Multi-label Learning framework (ViXML) efficiently integrates foundation vision models by pooling a single embedding per image. This limits computational growth while unlocking multi-modal capabilities. Remarkably, ViXML with small encoders outperforms text-only decoder in most cases, showing that an image is worth billions of parameters. Finally, we present an extension of existing text-only datasets to exploit visual metadata and make them available for future benchmarking. Comprehensive experiments across four public text-only datasets and their corresponding image enhanced versions validate our proposals' effectiveness, surpassing previous state-of-the-art by up to +8.21\% in P@1 on the largest dataset. ViXML's code is available at https://github.com/DiegoOrtego/vixml.
Unsupervised Class Generation to Expand Semantic Segmentation Datasets
Jan 04, 2025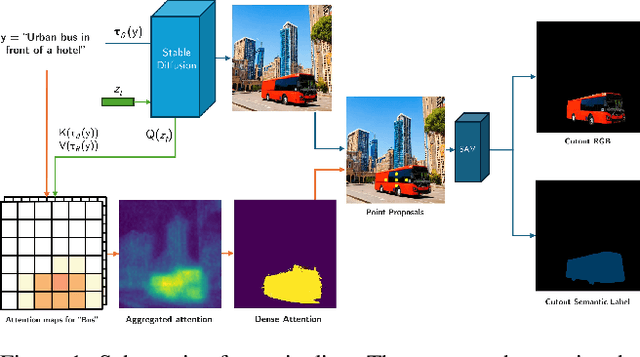
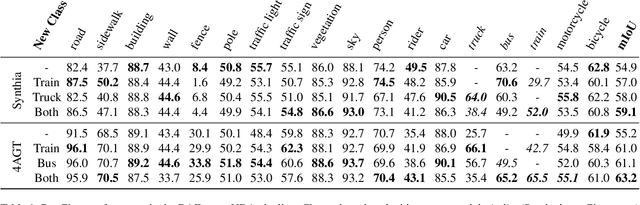

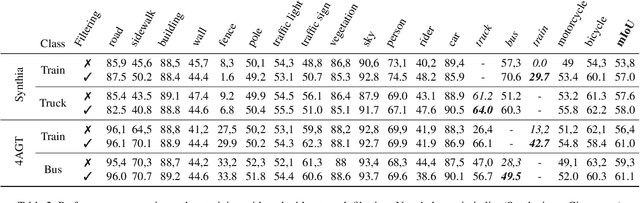
Semantic segmentation is a computer vision task where classification is performed at a pixel level. Due to this, the process of labeling images for semantic segmentation is time-consuming and expensive. To mitigate this cost there has been a surge in the use of synthetically generated data -- usually created using simulators or videogames -- which, in combination with domain adaptation methods, can effectively learn how to segment real data. Still, these datasets have a particular limitation: due to their closed-set nature, it is not possible to include novel classes without modifying the tool used to generate them, which is often not public. Concurrently, generative models have made remarkable progress, particularly with the introduction of diffusion models, enabling the creation of high-quality images from text prompts without additional supervision. In this work, we propose an unsupervised pipeline that leverages Stable Diffusion and Segment Anything Module to generate class examples with an associated segmentation mask, and a method to integrate generated cutouts for novel classes in semantic segmentation datasets, all with minimal user input. Our approach aims to improve the performance of unsupervised domain adaptation methods by introducing novel samples into the training data without modifications to the underlying algorithms. With our methods, we show how models can not only effectively learn how to segment novel classes, with an average performance of 51% IoU, but also reduce errors for other, already existing classes, reaching a higher performance level overall.
Leveraging Contrastive Learning for Semantic Segmentation with Consistent Labels Across Varying Appearances
Dec 21, 2024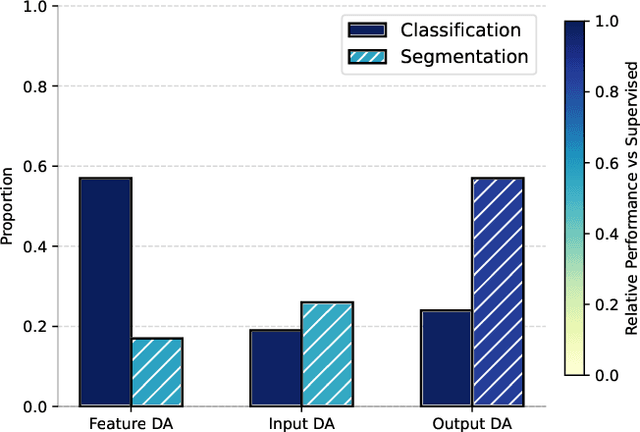


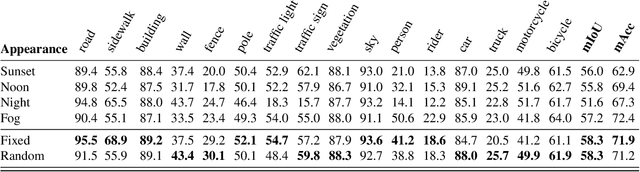
This paper introduces a novel synthetic dataset that captures urban scenes under a variety of weather conditions, providing pixel-perfect, ground-truth-aligned images to facilitate effective feature alignment across domains. Additionally, we propose a method for domain adaptation and generalization that takes advantage of the multiple versions of each scene, enforcing feature consistency across different weather scenarios. Our experimental results demonstrate the impact of our dataset in improving performance across several alignment metrics, addressing key challenges in domain adaptation and generalization for segmentation tasks. This research also explores critical aspects of synthetic data generation, such as optimizing the balance between the volume and variability of generated images to enhance segmentation performance. Ultimately, this work sets forth a new paradigm for synthetic data generation and domain adaptation.
VLMs meet UDA: Boosting Transferability of Open Vocabulary Segmentation with Unsupervised Domain Adaptation
Dec 12, 2024



Segmentation models are typically constrained by the categories defined during training. To address this, researchers have explored two independent approaches: adapting Vision-Language Models (VLMs) and leveraging synthetic data. However, VLMs often struggle with granularity, failing to disentangle fine-grained concepts, while synthetic data-based methods remain limited by the scope of available datasets. This paper proposes enhancing segmentation accuracy across diverse domains by integrating Vision-Language reasoning with key strategies for Unsupervised Domain Adaptation (UDA). First, we improve the fine-grained segmentation capabilities of VLMs through multi-scale contextual data, robust text embeddings with prompt augmentation, and layer-wise fine-tuning in our proposed Foundational-Retaining Open Vocabulary Semantic Segmentation (FROVSS) framework. Next, we incorporate these enhancements into a UDA framework by employing distillation to stabilize training and cross-domain mixed sampling to boost adaptability without compromising generalization. The resulting UDA-FROVSS framework is the first UDA approach to effectively adapt across domains without requiring shared categories.
Test-Time Adaptation for Keypoint-Based Spacecraft Pose Estimation Based on Predicted-View Synthesis
Oct 05, 2024Due to the difficulty of replicating the real conditions during training, supervised algorithms for spacecraft pose estimation experience a drop in performance when trained on synthetic data and applied to real operational data. To address this issue, we propose a test-time adaptation approach that leverages the temporal redundancy between images acquired during close proximity operations. Our approach involves extracting features from sequential spacecraft images, estimating their poses, and then using this information to synthesise a reconstructed view. We establish a self-supervised learning objective by comparing the synthesised view with the actual one. During training, we supervise both pose estimation and image synthesis, while at test-time, we optimise the self-supervised objective. Additionally, we introduce a regularisation loss to prevent solutions that are not consistent with the keypoint structure of the spacecraft. Our code is available at: https://github.com/JotaBravo/spacecraft-tta.
* Preprint
Layer-wise Model Merging for Unsupervised Domain Adaptation in Segmentation Tasks
Sep 24, 2024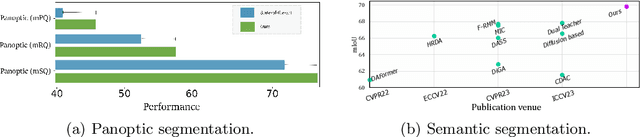
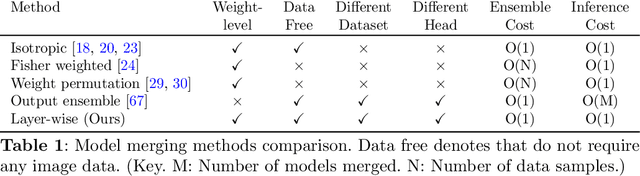
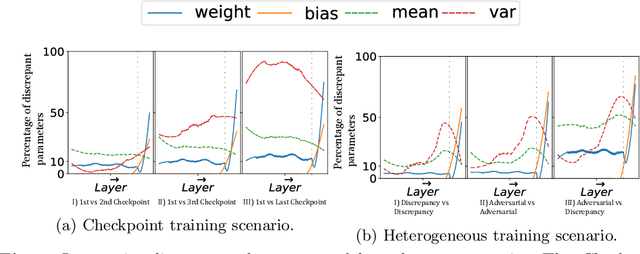
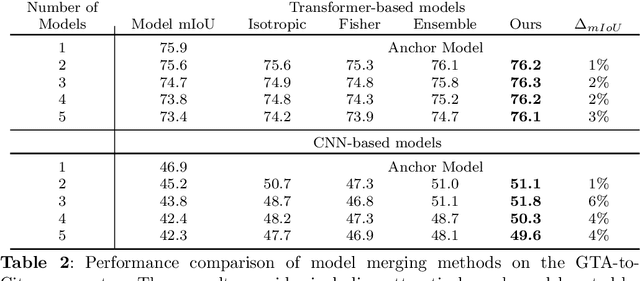
Merging parameters of multiple models has resurfaced as an effective strategy to enhance task performance and robustness, but prior work is limited by the high costs of ensemble creation and inference. In this paper, we leverage the abundance of freely accessible trained models to introduce a cost-free approach to model merging. It focuses on a layer-wise integration of merged models, aiming to maintain the distinctiveness of the task-specific final layers while unifying the initial layers, which are primarily associated with feature extraction. This approach ensures parameter consistency across all layers, essential for boosting performance. Moreover, it facilitates seamless integration of knowledge, enabling effective merging of models from different datasets and tasks. Specifically, we investigate its applicability in Unsupervised Domain Adaptation (UDA), an unexplored area for model merging, for Semantic and Panoptic Segmentation. Experimental results demonstrate substantial UDA improvements without additional costs for merging same-architecture models from distinct datasets ($\uparrow 2.6\%$ mIoU) and different-architecture models with a shared backbone ($\uparrow 6.8\%$ mIoU). Furthermore, merging Semantic and Panoptic Segmentation models increases mPQ by $\uparrow 7\%$. These findings are validated across a wide variety of UDA strategies, architectures, and datasets.
Gradient-based Class Weighting for Unsupervised Domain Adaptation in Dense Prediction Visual Tasks
Jul 01, 2024



In unsupervised domain adaptation (UDA), where models are trained on source data (e.g., synthetic) and adapted to target data (e.g., real-world) without target annotations, addressing the challenge of significant class imbalance remains an open issue. Despite considerable progress in bridging the domain gap, existing methods often experience performance degradation when confronted with highly imbalanced dense prediction visual tasks like semantic and panoptic segmentation. This discrepancy becomes especially pronounced due to the lack of equivalent priors between the source and target domains, turning class imbalanced techniques used for other areas (e.g., image classification) ineffective in UDA scenarios. This paper proposes a class-imbalance mitigation strategy that incorporates class-weights into the UDA learning losses, but with the novelty of estimating these weights dynamically through the loss gradient, defining a Gradient-based class weighting (GBW) learning. GBW naturally increases the contribution of classes whose learning is hindered by large-represented classes, and has the advantage of being able to automatically and quickly adapt to the iteration training outcomes, avoiding explicitly curricular learning patterns common in loss-weighing strategies. Extensive experimentation validates the effectiveness of GBW across architectures (convolutional and transformer), UDA strategies (adversarial, self-training and entropy minimization), tasks (semantic and panoptic segmentation), and datasets (GTA and Synthia). Analysing the source of advantage, GBW consistently increases the recall of low represented classes.
Open-Vocabulary Attention Maps with Token Optimization for Semantic Segmentation in Diffusion Models
Mar 21, 2024



Diffusion models represent a new paradigm in text-to-image generation. Beyond generating high-quality images from text prompts, models such as Stable Diffusion have been successfully extended to the joint generation of semantic segmentation pseudo-masks. However, current extensions primarily rely on extracting attentions linked to prompt words used for image synthesis. This approach limits the generation of segmentation masks derived from word tokens not contained in the text prompt. In this work, we introduce Open-Vocabulary Attention Maps (OVAM)-a training-free method for text-to-image diffusion models that enables the generation of attention maps for any word. In addition, we propose a lightweight optimization process based on OVAM for finding tokens that generate accurate attention maps for an object class with a single annotation. We evaluate these tokens within existing state-of-the-art Stable Diffusion extensions. The best-performing model improves its mIoU from 52.1 to 86.6 for the synthetic images' pseudo-masks, demonstrating that our optimized tokens are an efficient way to improve the performance of existing methods without architectural changes or retraining.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Soft labelling for semantic segmentation: Bringing coherence to label down-sampling
Mar 08, 2023



In semantic segmentation, training data down-sampling is commonly performed due to limited resources, the need to adapt image size to the model input, or improve data augmentation. This down-sampling typically employs different strategies for the image data and the annotated labels. Such discrepancy leads to mismatches between the down-sampled color and label images. Hence, the training performance significantly decreases as the down-sampling factor increases. In this paper, we bring together the down-sampling strategies for the image data and the training labels. To that aim, we propose a novel framework for label down-sampling via soft-labeling that better conserves label information after down-sampling. Therefore, fully aligning soft-labels with image data to keep the distribution of the sampled pixels. This proposal also produces reliable annotations for under-represented semantic classes. Altogether, it allows training competitive models at lower resolutions. Experiments show that the proposal outperforms other down-sampling strategies. Moreover, state-of-the-art performance is achieved for reference benchmarks, but employing significantly less computational resources than foremost approaches. This proposal enables competitive research for semantic segmentation under resource constraints.