 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthmanticLiDAR: A Synthetic Dataset for Semantic Segmentation on LiDAR Imaging
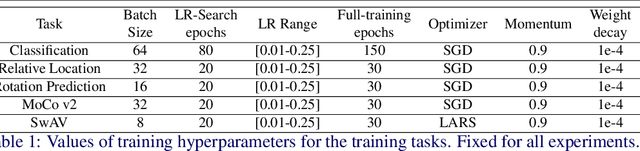
Jan 31, 2025



Semantic segmentation on LiDAR imaging is increasingly gaining attention, as it can provide useful knowledge for perception systems and potential for autonomous driving. However, collecting and labeling real LiDAR data is an expensive and time-consuming task. While datasets such as SemanticKITTI have been manually collected and labeled, the introduction of simulation tools such as CARLA, has enabled the creation of synthetic datasets on demand. In this work, we present a modified CARLA simulator designed with LiDAR semantic segmentation in mind, with new classes, more consistent object labeling with their counterparts from real datasets such as SemanticKITTI, and the possibility to adjust the object class distribution. Using this tool, we have generated SynthmanticLiDAR, a synthetic dataset for semantic segmentation on LiDAR imaging, designed to be similar to SemanticKITTI, and we evaluate its contribution to the training process of different semantic segmentation algorithms by using a naive transfer learning approach. Our results show that incorporating SynthmanticLiDAR into the training process improves the overall performance of tested algorithms, proving the usefulness of our dataset, and therefore, our adapted CARLA simulator. The dataset and simulator are available in https://github.com/vpulab/SynthmanticLiDAR.
* 2024 IEEE International Conference on Image Processing (ICIP)
Unsupervised Class Generation to Expand Semantic Segmentation Datasets
Jan 04, 2025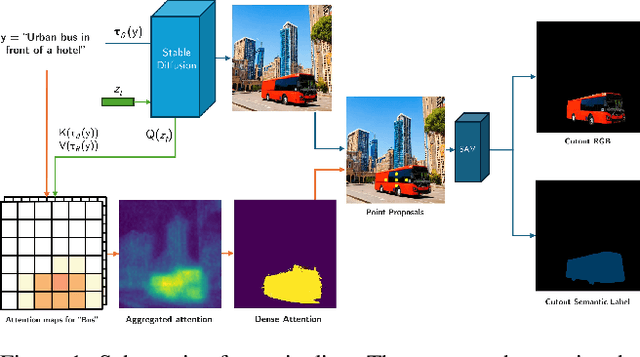
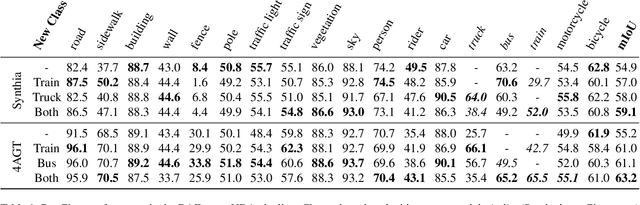

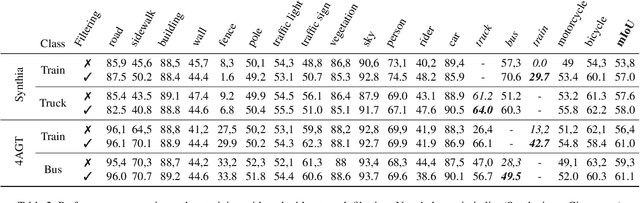
Semantic segmentation is a computer vision task where classification is performed at a pixel level. Due to this, the process of labeling images for semantic segmentation is time-consuming and expensive. To mitigate this cost there has been a surge in the use of synthetically generated data -- usually created using simulators or videogames -- which, in combination with domain adaptation methods, can effectively learn how to segment real data. Still, these datasets have a particular limitation: due to their closed-set nature, it is not possible to include novel classes without modifying the tool used to generate them, which is often not public. Concurrently, generative models have made remarkable progress, particularly with the introduction of diffusion models, enabling the creation of high-quality images from text prompts without additional supervision. In this work, we propose an unsupervised pipeline that leverages Stable Diffusion and Segment Anything Module to generate class examples with an associated segmentation mask, and a method to integrate generated cutouts for novel classes in semantic segmentation datasets, all with minimal user input. Our approach aims to improve the performance of unsupervised domain adaptation methods by introducing novel samples into the training data without modifications to the underlying algorithms. With our methods, we show how models can not only effectively learn how to segment novel classes, with an average performance of 51% IoU, but also reduce errors for other, already existing classes, reaching a higher performance level overall.
Leveraging Contrastive Learning for Semantic Segmentation with Consistent Labels Across Varying Appearances
Dec 21, 2024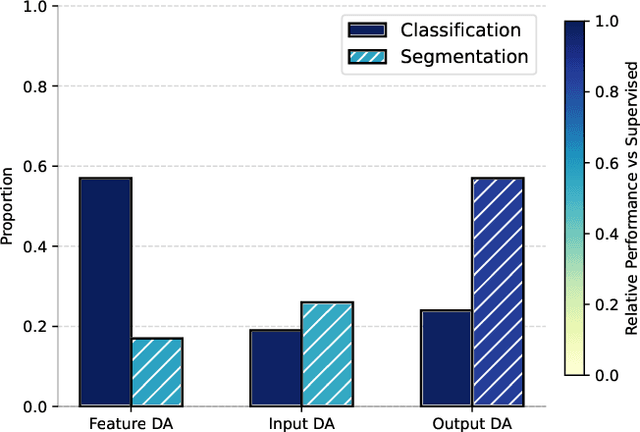


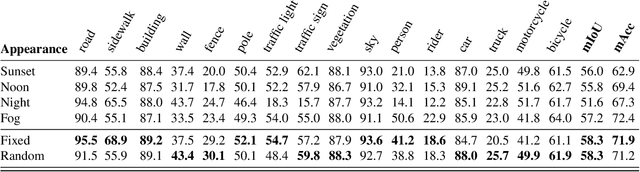
This paper introduces a novel synthetic dataset that captures urban scenes under a variety of weather conditions, providing pixel-perfect, ground-truth-aligned images to facilitate effective feature alignment across domains. Additionally, we propose a method for domain adaptation and generalization that takes advantage of the multiple versions of each scene, enforcing feature consistency across different weather scenarios. Our experimental results demonstrate the impact of our dataset in improving performance across several alignment metrics, addressing key challenges in domain adaptation and generalization for segmentation tasks. This research also explores critical aspects of synthetic data generation, such as optimizing the balance between the volume and variability of generated images to enhance segmentation performance. Ultimately, this work sets forth a new paradigm for synthetic data generation and domain adaptation.
Pinpoint Counterfactuals: Reducing social bias in foundation models via localized counterfactual generation
Dec 12, 2024
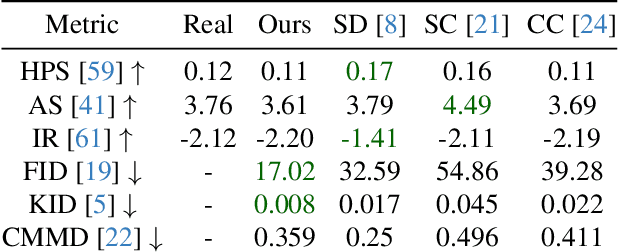

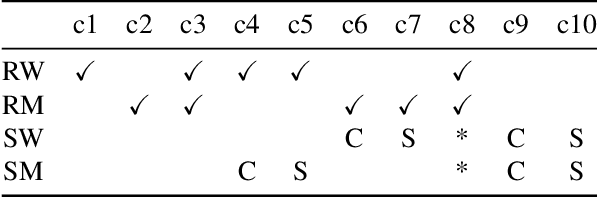
Foundation models trained on web-scraped datasets propagate societal biases to downstream tasks. While counterfactual generation enables bias analysis, existing methods introduce artifacts by modifying contextual elements like clothing and background. We present a localized counterfactual generation method that preserves image context by constraining counterfactual modifications to specific attribute-relevant regions through automated masking and guided inpainting. When applied to the Conceptual Captions dataset for creating gender counterfactuals, our method results in higher visual and semantic fidelity than state-of-the-art alternatives, while maintaining the performance of models trained using only real data on non-human-centric tasks. Models fine-tuned with our counterfactuals demonstrate measurable bias reduction across multiple metrics, including a decrease in gender classification disparity and balanced person preference scores, while preserving ImageNet zero-shot performance. The results establish a framework for creating balanced datasets that enable both accurate bias profiling and effective mitigation.
SPIN: Spacecraft Imagery for Navigation
Jun 12, 2024


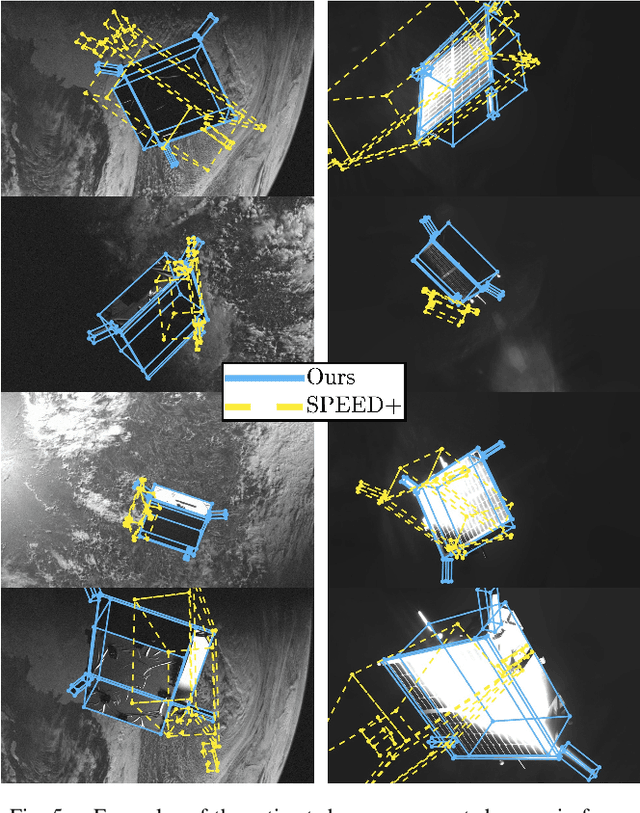
Data acquired in space operational conditions is scarce due to the costs and complexity of space operations. This poses a challenge to learning-based visual-based navigation algorithms employed in autonomous spacecraft navigation. Existing datasets, which largely depend on computer-simulated data, have partially filled this gap. However, the image generation tools they use are proprietary, which limits the evaluation of methods to unseen scenarios. Furthermore, these datasets provide limited ground-truth data, primarily focusing on the spacecraft's translation and rotation relative to the camera. To address these limitations, we present SPIN (SPacecraft Imagery for Navigation), an open-source realistic spacecraft image generation tool for relative navigation between two spacecrafts. SPIN provides a wide variety of ground-truth data and allows researchers to employ custom 3D models of satellites, define specific camera-relative poses, and adjust various settings such as camera parameters and environmental illumination conditions. For the task of spacecraft pose estimation, we compare the results of training with a SPIN-generated dataset against existing synthetic datasets. We show a %50 average error reduction in common testbed data (that simulates realistic space conditions). Both the SPIN tool (and source code) and our enhanced version of the synthetic datasets will be publicly released upon paper acceptance on GitHub https://github.com/vpulab/SPIN.
Self-Supervised Curricular Deep Learning for Chest X-Ray Image Classification
Jan 25, 2023
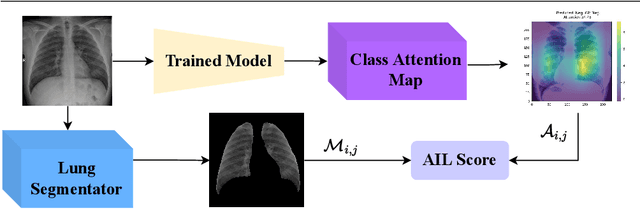
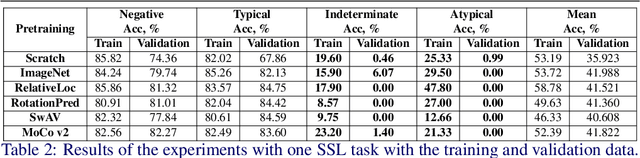
Deep learning technologies have already demonstrated a high potential to build diagnosis support systems from medical imaging data, such as Chest X-Ray images. However, the shortage of labeled data in the medical field represents one key obstacle to narrow down the performance gap with respect to applications in other image domains. In this work, we investigate the benefits of a curricular Self-Supervised Learning (SSL) pretraining scheme with respect to fully-supervised training regimes for pneumonia recognition on Chest X-Ray images of Covid-19 patients. We show that curricular SSL pretraining, which leverages unlabeled data, outperforms models trained from scratch, or pretrained on ImageNet, indicating the potential of performance gains by SSL pretraining on massive unlabeled datasets. Finally, we demonstrate that top-performing SSLpretrained models show a higher degree of attention in the lung regions, embodying models that may be more robust to possible external confounding factors in the training datasets, identified by previous works.
A study on the distribution of social biases in self-supervised learning visual models
Mar 03, 2022


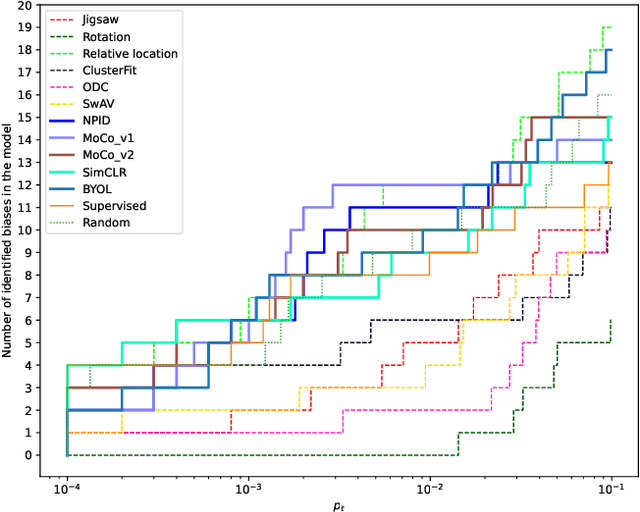
Deep neural networks are efficient at learning the data distribution if it is sufficiently sampled. However, they can be strongly biased by non-relevant factors implicitly incorporated in the training data. These include operational biases, such as ineffective or uneven data sampling, but also ethical concerns, as the social biases are implicitly present\textemdash even inadvertently, in the training data or explicitly defined in unfair training schedules. In tasks having impact on human processes, the learning of social biases may produce discriminatory, unethical and untrustworthy consequences. It is often assumed that social biases stem from supervised learning on labelled data, and thus, Self-Supervised Learning (SSL) wrongly appears as an efficient and bias-free solution, as it does not require labelled data. However, it was recently proven that a popular SSL method also incorporates biases. In this paper, we study the biases of a varied set of SSL visual models, trained using ImageNet data, using a method and dataset designed by psychological experts to measure social biases. We show that there is a correlation between the type of the SSL model and the number of biases that it incorporates. Furthermore, the results also suggest that this number does not strictly depend on the model's accuracy and changes throughout the network. Finally, we conclude that a careful SSL model selection process can reduce the number of social biases in the deployed model, whilst keeping high performance.
Graph Neural Networks for Cross-Camera Data Association
Jan 17, 2022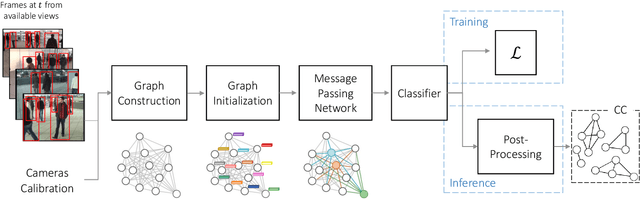
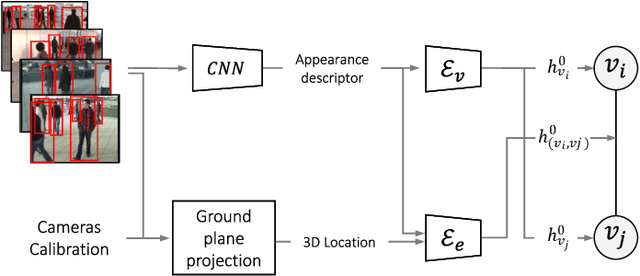
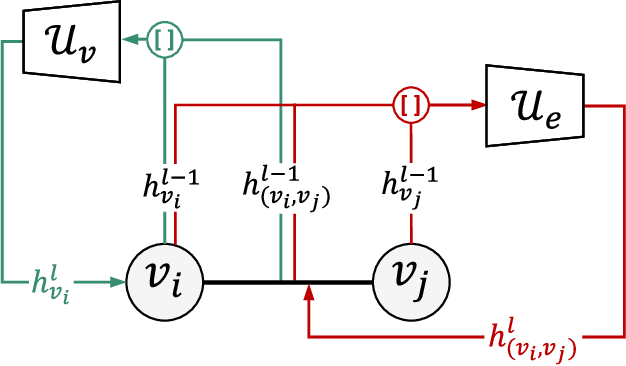
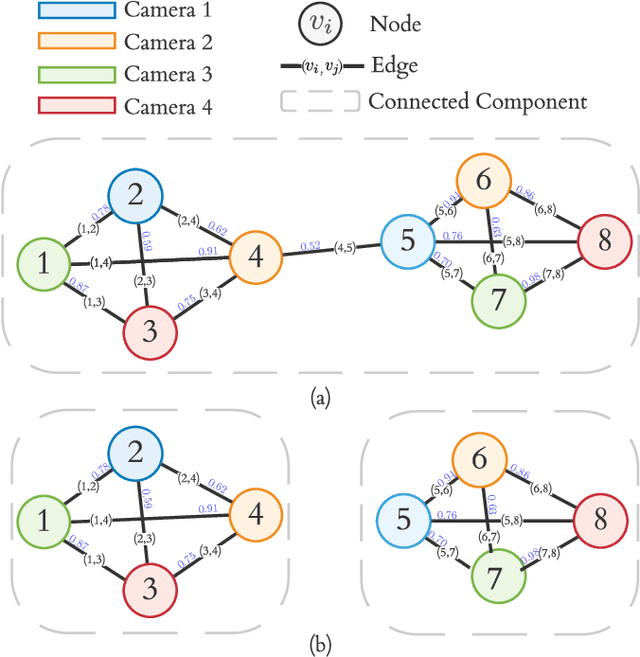
Cross-camera image data association is essential for many multi-camera computer vision tasks, such as multi-camera pedestrian detection, multi-camera multi-target tracking, 3D pose estimation, etc. This association task is typically stated as a bipartite graph matching problem and often solved by applying minimum-cost flow techniques, which may be computationally inefficient with large data. Furthermore, cameras are usually treated by pairs, obtaining local solutions, rather than finding a global solution at once. Other key issue is that of the affinity measurement: the widespread usage of non-learnable pre-defined distances, such as the Euclidean and Cosine ones. This paper proposes an efficient approach for cross-cameras data-association focused on a global solution, instead of processing cameras by pairs. To avoid the usage of fixed distances, we leverage the connectivity of Graph Neural Networks, previously unused in this scope, using a Message Passing Network to jointly learn features and similarity. We validate the proposal for pedestrian multi-view association, showing results over the EPFL multi-camera pedestrian dataset. Our approach considerably outperforms the literature data association techniques, without requiring to be trained in the same scenario in which it is tested. Our code is available at \url{http://www-vpu.eps.uam.es/publications/gnn_cca}.
Improved skin lesion recognition by a Self-Supervised Curricular Deep Learning approach
Dec 22, 2021
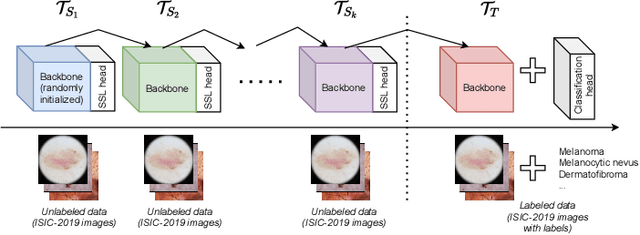
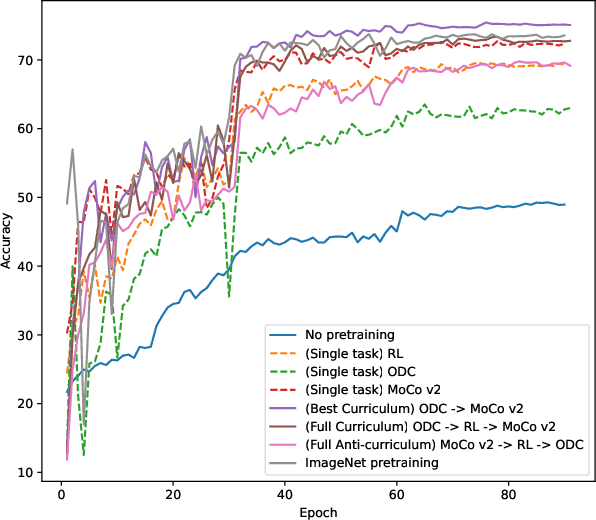
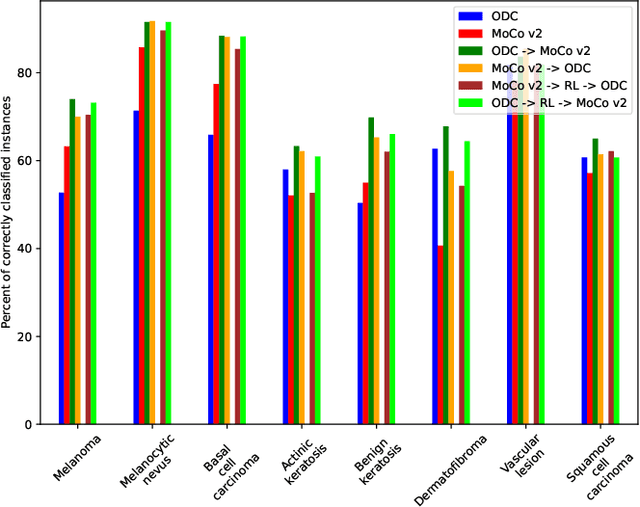
State-of-the-art deep learning approaches for skin lesion recognition often require pretraining on larger and more varied datasets, to overcome the generalization limitations derived from the reduced size of the skin lesion imaging datasets. ImageNet is often used as the pretraining dataset, but its transferring potential is hindered by the domain gap between the source dataset and the target dermatoscopic scenario. In this work, we introduce a novel pretraining approach that sequentially trains a series of Self-Supervised Learning pretext tasks and only requires the unlabeled skin lesion imaging data. We present a simple methodology to establish an ordering that defines a pretext task curriculum. For the multi-class skin lesion classification problem, and ISIC-2019 dataset, we provide experimental evidence showing that: i) a model pretrained by a curriculum of pretext tasks outperforms models pretrained by individual pretext tasks, and ii) a model pretrained by the optimal pretext task curriculum outperforms a model pretrained on ImageNet. We demonstrate that this performance gain is related to the fact that the curriculum of pretext tasks better focuses the attention of the final model on the skin lesion. Beyond performance improvement, this strategy allows for a large reduction in the training time with respect to ImageNet pretraining, which is especially advantageous for network architectures tailored for a specific problem.
FVV Live: A real-time free-viewpoint video system with consumer electronics hardware
Jul 01, 2020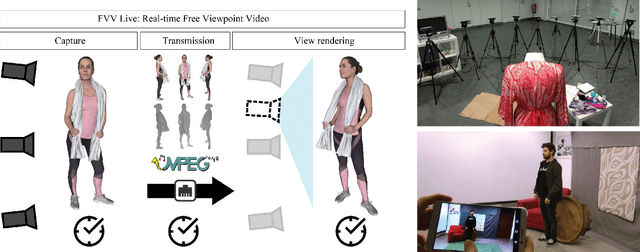
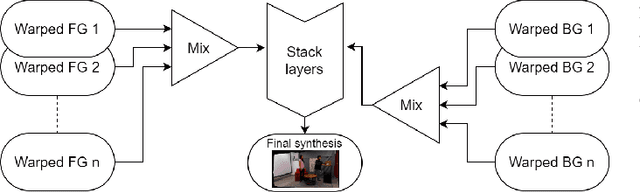
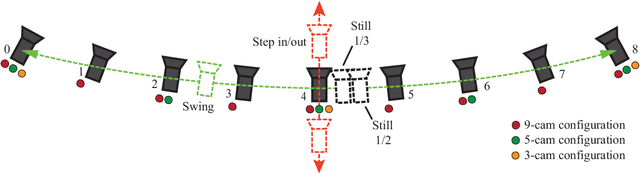

FVV Live is a novel end-to-end free-viewpoint video system, designed for low cost and real-time operation, based on off-the-shelf components. The system has been designed to yield high-quality free-viewpoint video using consumer-grade cameras and hardware, which enables low deployment costs and easy installation for immersive event-broadcasting or videoconferencing. The paper describes the architecture of the system, including acquisition and encoding of multiview plus depth data in several capture servers and virtual view synthesis on an edge server. All the blocks of the system have been designed to overcome the limitations imposed by hardware and network, which impact directly on the accuracy of depth data and thus on the quality of virtual view synthesis. The design of FVV Live allows for an arbitrary number of cameras and capture servers, and the results presented in this paper correspond to an implementation with nine stereo-based depth cameras. FVV Live presents low motion-to-photon and end-to-end delays, which enables seamless free-viewpoint navigation and bilateral immersive communications. Moreover, the visual quality of FVV Live has been assessed through subjective assessment with satisfactory results, and additional comparative tests show that it is preferred over state-of-the-art DIBR alternatives.