 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Cross-Camera Data Association
Jan 17, 2022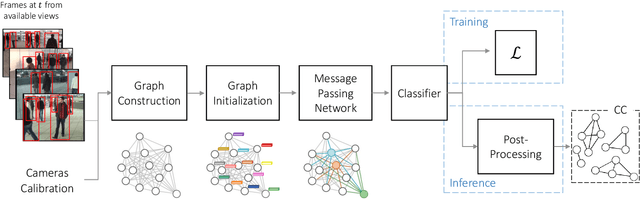
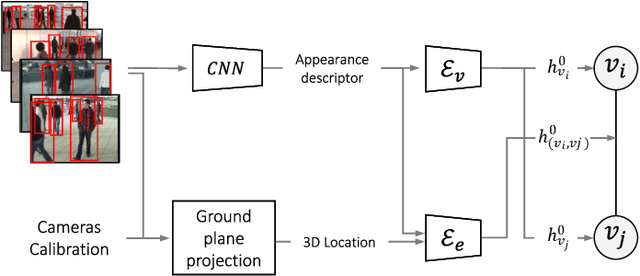
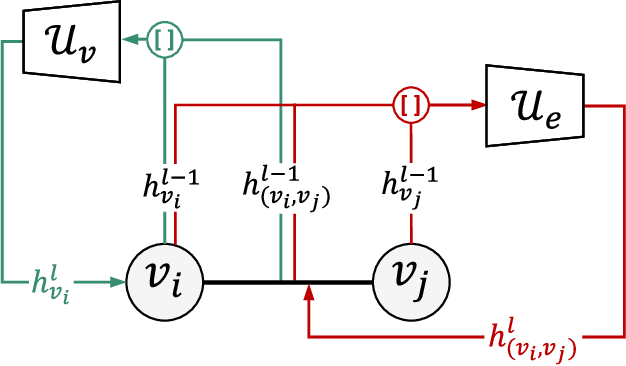
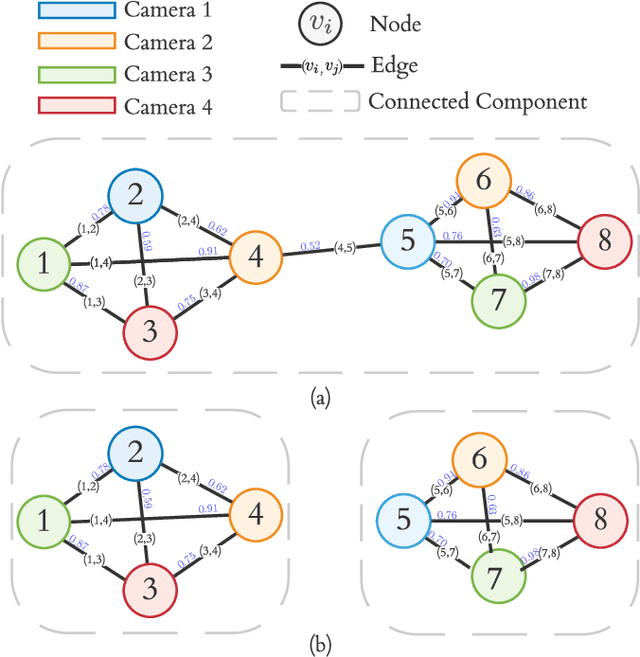
Cross-camera image data association is essential for many multi-camera computer vision tasks, such as multi-camera pedestrian detection, multi-camera multi-target tracking, 3D pose estimation, etc. This association task is typically stated as a bipartite graph matching problem and often solved by applying minimum-cost flow techniques, which may be computationally inefficient with large data. Furthermore, cameras are usually treated by pairs, obtaining local solutions, rather than finding a global solution at once. Other key issue is that of the affinity measurement: the widespread usage of non-learnable pre-defined distances, such as the Euclidean and Cosine ones. This paper proposes an efficient approach for cross-cameras data-association focused on a global solution, instead of processing cameras by pairs. To avoid the usage of fixed distances, we leverage the connectivity of Graph Neural Networks, previously unused in this scope, using a Message Passing Network to jointly learn features and similarity. We validate the proposal for pedestrian multi-view association, showing results over the EPFL multi-camera pedestrian dataset. Our approach considerably outperforms the literature data association techniques, without requiring to be trained in the same scenario in which it is tested. Our code is available at \url{http://www-vpu.eps.uam.es/publications/gnn_cca}.
On guiding video object segmentation
Apr 25, 2019



This paper presents a novel approach for segmenting moving objects in unconstrained environments using guided convolutional neural networks. This guiding process relies on foreground masks from independent algorithms (i.e. state-of-the-art algorithms) to implement an attention mechanism that incorporates the spatial location of foreground and background to compute their separated representations. Our approach initially extracts two kinds of features for each frame using colour and optical flow information. Such features are combined following a multiplicative scheme to benefit from their complementarity. These unified colour and motion features are later processed to obtain the separated foreground and background representations. Then, both independent representations are concatenated and decoded to perform foreground segmentation. Experiments conducted on the challenging DAVIS 2016 dataset demonstrate that our guided representations not only outperform non-guided, but also recent and top-performing video object segmentation algorithms.