 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthmanticLiDAR: A Synthetic Dataset for Semantic Segmentation on LiDAR Imaging
Jan 31, 2025



Semantic segmentation on LiDAR imaging is increasingly gaining attention, as it can provide useful knowledge for perception systems and potential for autonomous driving. However, collecting and labeling real LiDAR data is an expensive and time-consuming task. While datasets such as SemanticKITTI have been manually collected and labeled, the introduction of simulation tools such as CARLA, has enabled the creation of synthetic datasets on demand. In this work, we present a modified CARLA simulator designed with LiDAR semantic segmentation in mind, with new classes, more consistent object labeling with their counterparts from real datasets such as SemanticKITTI, and the possibility to adjust the object class distribution. Using this tool, we have generated SynthmanticLiDAR, a synthetic dataset for semantic segmentation on LiDAR imaging, designed to be similar to SemanticKITTI, and we evaluate its contribution to the training process of different semantic segmentation algorithms by using a naive transfer learning approach. Our results show that incorporating SynthmanticLiDAR into the training process improves the overall performance of tested algorithms, proving the usefulness of our dataset, and therefore, our adapted CARLA simulator. The dataset and simulator are available in https://github.com/vpulab/SynthmanticLiDAR.
* 2024 IEEE International Conference on Image Processing (ICIP)
Unsupervised Class Generation to Expand Semantic Segmentation Datasets
Jan 04, 2025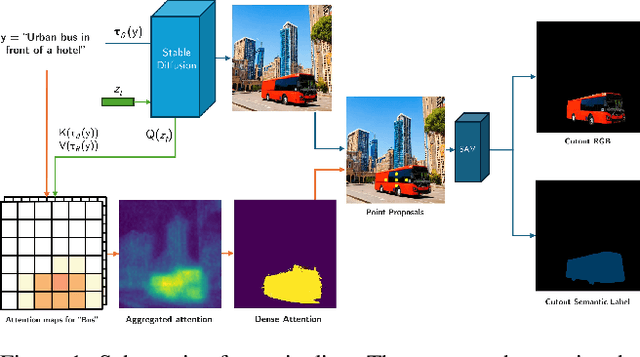
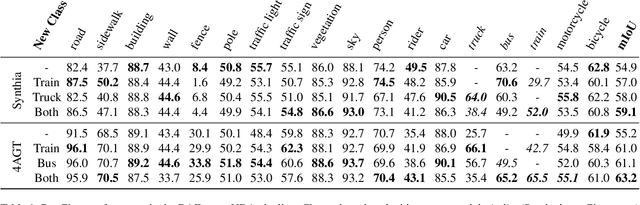

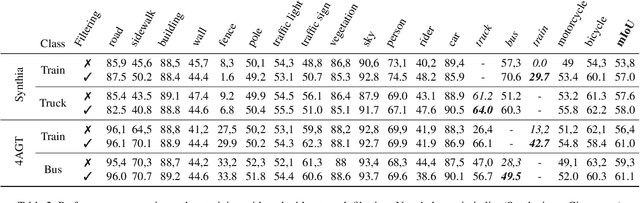
Semantic segmentation is a computer vision task where classification is performed at a pixel level. Due to this, the process of labeling images for semantic segmentation is time-consuming and expensive. To mitigate this cost there has been a surge in the use of synthetically generated data -- usually created using simulators or videogames -- which, in combination with domain adaptation methods, can effectively learn how to segment real data. Still, these datasets have a particular limitation: due to their closed-set nature, it is not possible to include novel classes without modifying the tool used to generate them, which is often not public. Concurrently, generative models have made remarkable progress, particularly with the introduction of diffusion models, enabling the creation of high-quality images from text prompts without additional supervision. In this work, we propose an unsupervised pipeline that leverages Stable Diffusion and Segment Anything Module to generate class examples with an associated segmentation mask, and a method to integrate generated cutouts for novel classes in semantic segmentation datasets, all with minimal user input. Our approach aims to improve the performance of unsupervised domain adaptation methods by introducing novel samples into the training data without modifications to the underlying algorithms. With our methods, we show how models can not only effectively learn how to segment novel classes, with an average performance of 51% IoU, but also reduce errors for other, already existing classes, reaching a higher performance level overall.
Leveraging Contrastive Learning for Semantic Segmentation with Consistent Labels Across Varying Appearances
Dec 21, 2024


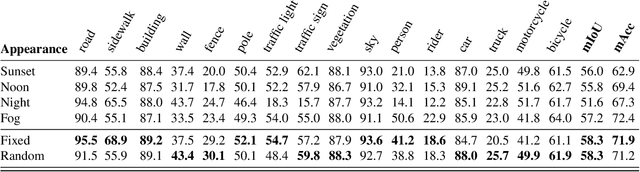
This paper introduces a novel synthetic dataset that captures urban scenes under a variety of weather conditions, providing pixel-perfect, ground-truth-aligned images to facilitate effective feature alignment across domains. Additionally, we propose a method for domain adaptation and generalization that takes advantage of the multiple versions of each scene, enforcing feature consistency across different weather scenarios. Our experimental results demonstrate the impact of our dataset in improving performance across several alignment metrics, addressing key challenges in domain adaptation and generalization for segmentation tasks. This research also explores critical aspects of synthetic data generation, such as optimizing the balance between the volume and variability of generated images to enhance segmentation performance. Ultimately, this work sets forth a new paradigm for synthetic data generation and domain adaptation.
SPIN: Spacecraft Imagery for Navigation
Jun 12, 2024


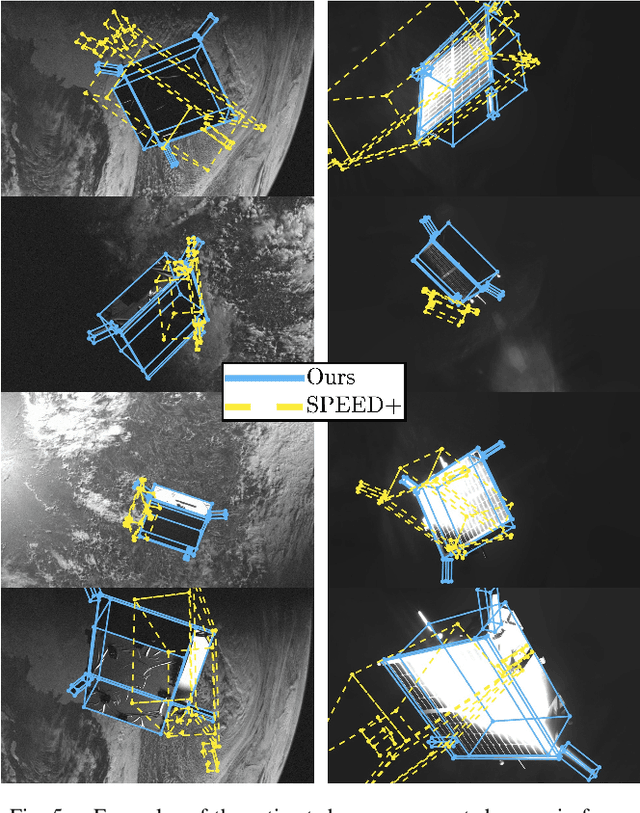
Data acquired in space operational conditions is scarce due to the costs and complexity of space operations. This poses a challenge to learning-based visual-based navigation algorithms employed in autonomous spacecraft navigation. Existing datasets, which largely depend on computer-simulated data, have partially filled this gap. However, the image generation tools they use are proprietary, which limits the evaluation of methods to unseen scenarios. Furthermore, these datasets provide limited ground-truth data, primarily focusing on the spacecraft's translation and rotation relative to the camera. To address these limitations, we present SPIN (SPacecraft Imagery for Navigation), an open-source realistic spacecraft image generation tool for relative navigation between two spacecrafts. SPIN provides a wide variety of ground-truth data and allows researchers to employ custom 3D models of satellites, define specific camera-relative poses, and adjust various settings such as camera parameters and environmental illumination conditions. For the task of spacecraft pose estimation, we compare the results of training with a SPIN-generated dataset against existing synthetic datasets. We show a %50 average error reduction in common testbed data (that simulates realistic space conditions). Both the SPIN tool (and source code) and our enhanced version of the synthetic datasets will be publicly released upon paper acceptance on GitHub https://github.com/vpulab/SPIN.