 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Attention Maps with Token Optimization for Semantic Segmentation in Diffusion Models
Mar 21, 2024



Diffusion models represent a new paradigm in text-to-image generation. Beyond generating high-quality images from text prompts, models such as Stable Diffusion have been successfully extended to the joint generation of semantic segmentation pseudo-masks. However, current extensions primarily rely on extracting attentions linked to prompt words used for image synthesis. This approach limits the generation of segmentation masks derived from word tokens not contained in the text prompt. In this work, we introduce Open-Vocabulary Attention Maps (OVAM)-a training-free method for text-to-image diffusion models that enables the generation of attention maps for any word. In addition, we propose a lightweight optimization process based on OVAM for finding tokens that generate accurate attention maps for an object class with a single annotation. We evaluate these tokens within existing state-of-the-art Stable Diffusion extensions. The best-performing model improves its mIoU from 52.1 to 86.6 for the synthetic images' pseudo-masks, demonstrating that our optimized tokens are an efficient way to improve the performance of existing methods without architectural changes or retraining.
Online Clustering-based Multi-Camera Vehicle Tracking in Scenarios with overlapping FOVs
Feb 08, 2021

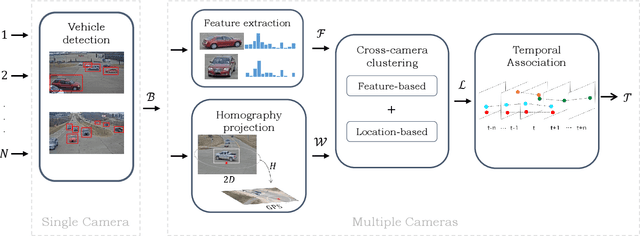

Multi-Target Multi-Camera (MTMC) vehicle tracking is an essential task of visual traffic monitoring, one of the main research fields of Intelligent Transportation Systems. Several offline approaches have been proposed to address this task; however, they are not compatible with real-world applications due to their high latency and post-processing requirements. In this paper, we present a new low-latency online approach for MTMC tracking in scenarios with partially overlapping fields of view (FOVs), such as road intersections. Firstly, the proposed approach detects vehicles at each camera. Then, the detections are merged between cameras by applying cross-camera clustering based on appearance and location. Lastly, the clusters containing different detections of the same vehicle are temporally associated to compute the tracks on a frame-by-frame basis. The experiments show promising low-latency results while addressing real-world challenges such as the a priori unknown and time-varying number of targets and the continuous state estimation of them without performing any post-processing of the trajectories.