 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Model Merging for Unsupervised Domain Adaptation in Segmentation Tasks
Sep 24, 2024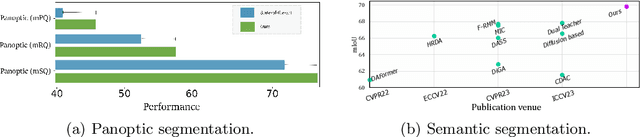
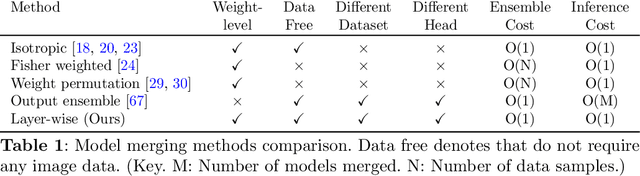
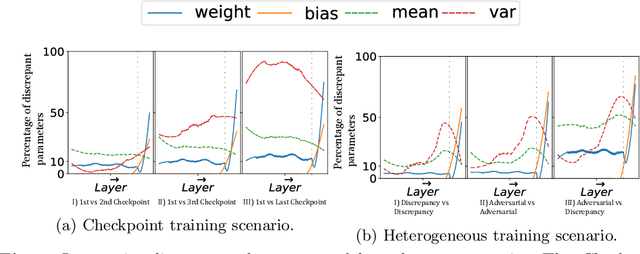
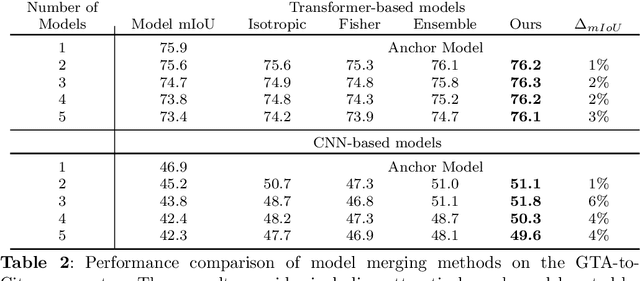
Merging parameters of multiple models has resurfaced as an effective strategy to enhance task performance and robustness, but prior work is limited by the high costs of ensemble creation and inference. In this paper, we leverage the abundance of freely accessible trained models to introduce a cost-free approach to model merging. It focuses on a layer-wise integration of merged models, aiming to maintain the distinctiveness of the task-specific final layers while unifying the initial layers, which are primarily associated with feature extraction. This approach ensures parameter consistency across all layers, essential for boosting performance. Moreover, it facilitates seamless integration of knowledge, enabling effective merging of models from different datasets and tasks. Specifically, we investigate its applicability in Unsupervised Domain Adaptation (UDA), an unexplored area for model merging, for Semantic and Panoptic Segmentation. Experimental results demonstrate substantial UDA improvements without additional costs for merging same-architecture models from distinct datasets ($\uparrow 2.6\%$ mIoU) and different-architecture models with a shared backbone ($\uparrow 6.8\%$ mIoU). Furthermore, merging Semantic and Panoptic Segmentation models increases mPQ by $\uparrow 7\%$. These findings are validated across a wide variety of UDA strategies, architectures, and datasets.