 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEAST: Fully Connected Expressive Attention for Spatial Transcriptomics
Mar 26, 2026Spatial Transcriptomics (ST) provides spatially-resolved gene expression, offering crucial insights into tissue architecture and complex diseases. However, its prohibitive cost limits widespread adoption, leading to significant attention on inferring spatial gene expression from readily available whole slide images. While graph neural networks have been proposed to model interactions between tissue regions, their reliance on pre-defined sparse graphs prevents them from considering potentially interacting spot pairs, resulting in a structural limitation in capturing complex biological relationships. To address this, we propose FEAST (Fully connected Expressive Attention for Spatial Transcriptomics), an attention-based framework that models the tissue as a fully connected graph, enabling the consideration of all pairwise interactions. To better reflect biological interactions, we introduce negative-aware attention, which models both excitatory and inhibitory interactions, capturing essential negative relationships that standard attention often overlooks. Furthermore, to mitigate the information loss from truncated or ignored context in standard spot image extraction, we introduce an off-grid sampling strategy that gathers additional images from intermediate regions, allowing the model to capture a richer morphological context. Experiments on public ST datasets show that FEAST surpasses state-of-the-art methods in gene expression prediction while providing biologically plausible attention maps that clarify positive and negative interactions. Our code is available at https://github.com/starforTJ/ FEAST.
Rethinking Glaucoma Calibration: Voting-Based Binocular and Metadata Integration
Mar 24, 2025



Glaucoma is an incurable ophthalmic disease that damages the optic nerve, leads to vision loss, and ranks among the leading causes of blindness worldwide. Diagnosing glaucoma typically involves fundus photography, optical coherence tomography (OCT), and visual field testing. However, the high cost of OCT often leads to reliance on fundus photography and visual field testing, both of which exhibit inherent inter-observer variability. This stems from glaucoma being a multifaceted disease that influenced by various factors. As a result, glaucoma diagnosis is highly subjective, emphasizing the necessity of calibration, which aligns predicted probabilities with actual disease likelihood. Proper calibration is essential to prevent overdiagnosis or misdiagnosis, which are critical concerns for high-risk diseases. Although AI has significantly improved diagnostic accuracy, overconfidence in models have worsen calibration performance. Recent study has begun focusing on calibration for glaucoma. Nevertheless, previous study has not fully considered glaucoma's systemic nature and the high subjectivity in its diagnostic process. To overcome these limitations, we propose V-ViT (Voting-based ViT), a novel framework that enhances calibration by incorporating disease-specific characteristics. V-ViT integrates binocular data and metadata, reflecting the multi-faceted nature of glaucoma diagnosis. Additionally, we introduce a MC dropout-based Voting System to address high subjectivity. Our approach achieves state-of-the-art performance across all metrics, including accuracy, demonstrating that our proposed methods are effective in addressing calibration issues. We validate our method using a custom dataset including binocular data.
Brain-Streams: fMRI-to-Image Reconstruction with Multi-modal Guidance
Sep 18, 2024
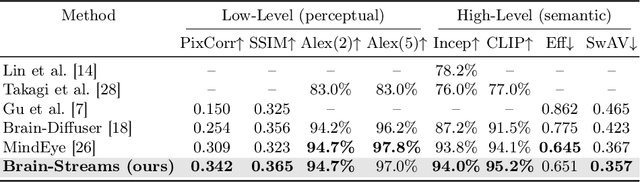
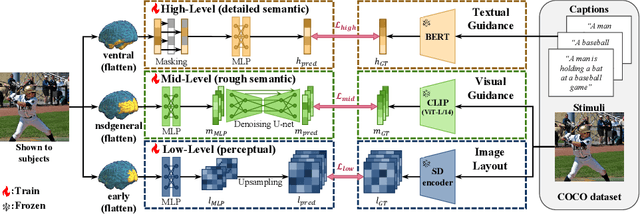
Understanding how humans process visual information is one of the crucial steps for unraveling the underlying mechanism of brain activity. Recently, this curiosity has motivated the fMRI-to-image reconstruction task; given the fMRI data from visual stimuli, it aims to reconstruct the corresponding visual stimuli. Surprisingly, leveraging powerful generative models such as the Latent Diffusion Model (LDM) has shown promising results in reconstructing complex visual stimuli such as high-resolution natural images from vision datasets. Despite the impressive structural fidelity of these reconstructions, they often lack details of small objects, ambiguous shapes, and semantic nuances. Consequently, the incorporation of additional semantic knowledge, beyond mere visuals, becomes imperative. In light of this, we exploit how modern LDMs effectively incorporate multi-modal guidance (text guidance, visual guidance, and image layout) for structurally and semantically plausible image generations. Specifically, inspired by the two-streams hypothesis suggesting that perceptual and semantic information are processed in different brain regions, our framework, Brain-Streams, maps fMRI signals from these brain regions to appropriate embeddings. That is, by extracting textual guidance from semantic information regions and visual guidance from perceptual information regions, Brain-Streams provides accurate multi-modal guidance to LDMs. We validate the reconstruction ability of Brain-Streams both quantitatively and qualitatively on a real fMRI dataset comprising natural image stimuli and fMRI data.
DragText: Rethinking Text Embedding in Point-based Image Editing
Jul 25, 2024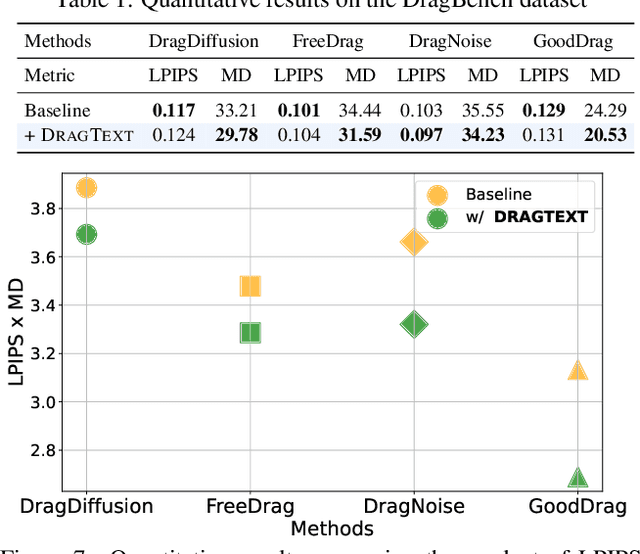
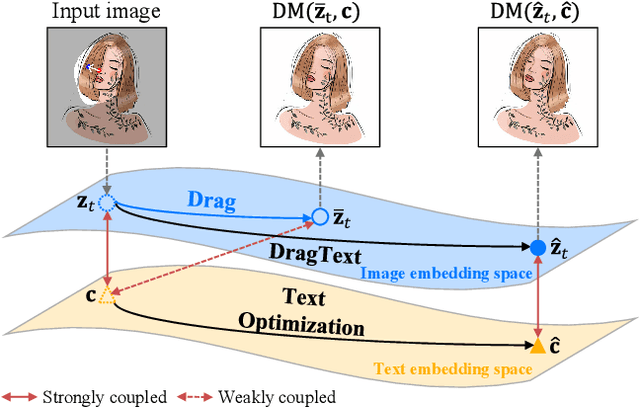


Point-based image editing enables accurate and flexible control through content dragging. However, the role of text embedding in the editing process has not been thoroughly investigated. A significant aspect that remains unexplored is the interaction between text and image embeddings. In this study, we show that during the progressive editing of an input image in a diffusion model, the text embedding remains constant. As the image embedding increasingly diverges from its initial state, the discrepancy between the image and text embeddings presents a significant challenge. Moreover, we found that the text prompt significantly influences the dragging process, particularly in maintaining content integrity and achieving the desired manipulation. To utilize these insights, we propose DragText, which optimizes text embedding in conjunction with the dragging process to pair with the modified image embedding. Simultaneously, we regularize the text optimization process to preserve the integrity of the original text prompt. Our approach can be seamlessly integrated with existing diffusion-based drag methods with only a few lines of code.