 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-Streams: fMRI-to-Image Reconstruction with Multi-modal Guidance
Sep 18, 2024
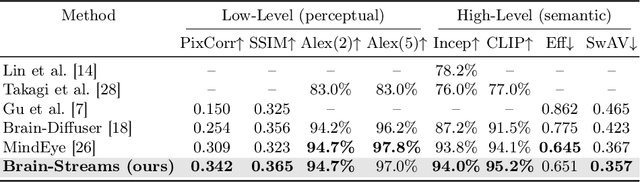
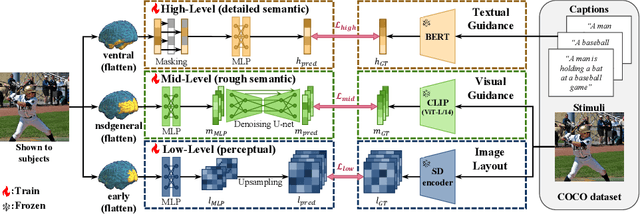
Understanding how humans process visual information is one of the crucial steps for unraveling the underlying mechanism of brain activity. Recently, this curiosity has motivated the fMRI-to-image reconstruction task; given the fMRI data from visual stimuli, it aims to reconstruct the corresponding visual stimuli. Surprisingly, leveraging powerful generative models such as the Latent Diffusion Model (LDM) has shown promising results in reconstructing complex visual stimuli such as high-resolution natural images from vision datasets. Despite the impressive structural fidelity of these reconstructions, they often lack details of small objects, ambiguous shapes, and semantic nuances. Consequently, the incorporation of additional semantic knowledge, beyond mere visuals, becomes imperative. In light of this, we exploit how modern LDMs effectively incorporate multi-modal guidance (text guidance, visual guidance, and image layout) for structurally and semantically plausible image generations. Specifically, inspired by the two-streams hypothesis suggesting that perceptual and semantic information are processed in different brain regions, our framework, Brain-Streams, maps fMRI signals from these brain regions to appropriate embeddings. That is, by extracting textual guidance from semantic information regions and visual guidance from perceptual information regions, Brain-Streams provides accurate multi-modal guidance to LDMs. We validate the reconstruction ability of Brain-Streams both quantitatively and qualitatively on a real fMRI dataset comprising natural image stimuli and fMRI data.
Online Graph Completion: Multivariate Signal Recovery in Computer Vision
Aug 12, 2020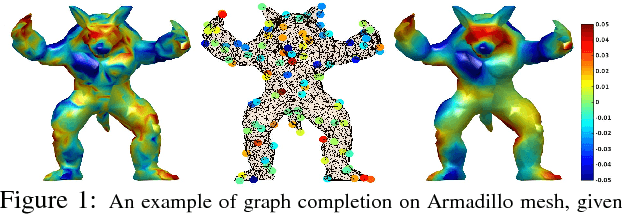
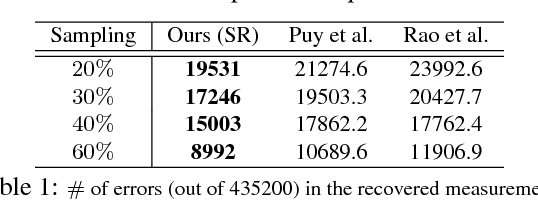
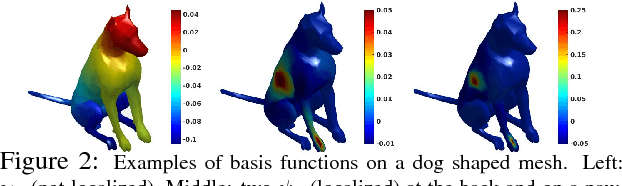
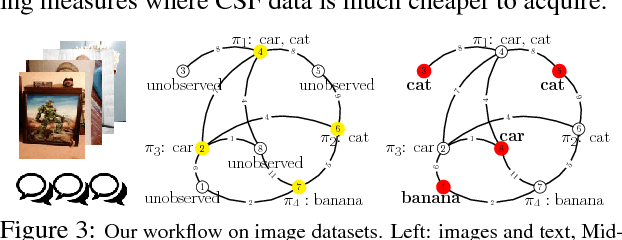
The adoption of "human-in-the-loop" paradigms in computer vision and machine learning is leading to various applications where the actual data acquisition (e.g., human supervision) and the underlying inference algorithms are closely interwined. While classical work in active learning provides effective solutions when the learning module involves classification and regression tasks, many practical issues such as partially observed measurements, financial constraints and even additional distributional or structural aspects of the data typically fall outside the scope of this treatment. For instance, with sequential acquisition of partial measurements of data that manifest as a matrix (or tensor), novel strategies for completion (or collaborative filtering) of the remaining entries have only been studied recently. Motivated by vision problems where we seek to annotate a large dataset of images via a crowdsourced platform or alternatively, complement results from a state-of-the-art object detector using human feedback, we study the "completion" problem defined on graphs, where requests for additional measurements must be made sequentially. We design the optimization model in the Fourier domain of the graph describing how ideas based on adaptive submodularity provide algorithms that work well in practice. On a large set of images collected from Imgur, we see promising results on images that are otherwise difficult to categorize. We also show applications to an experimental design problem in neuroimaging.