 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGene-SGAN: a method for discovering disease subtypes with imaging and genetic signatures via multi-view weakly-supervised deep clustering
Jan 25, 2023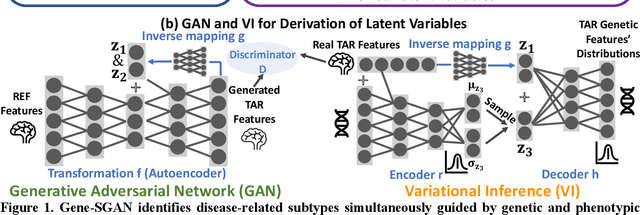
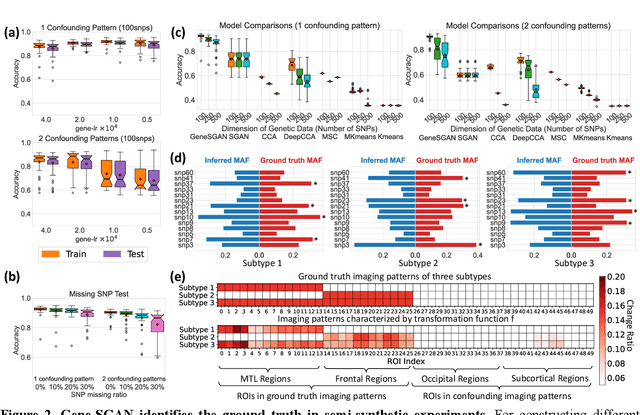
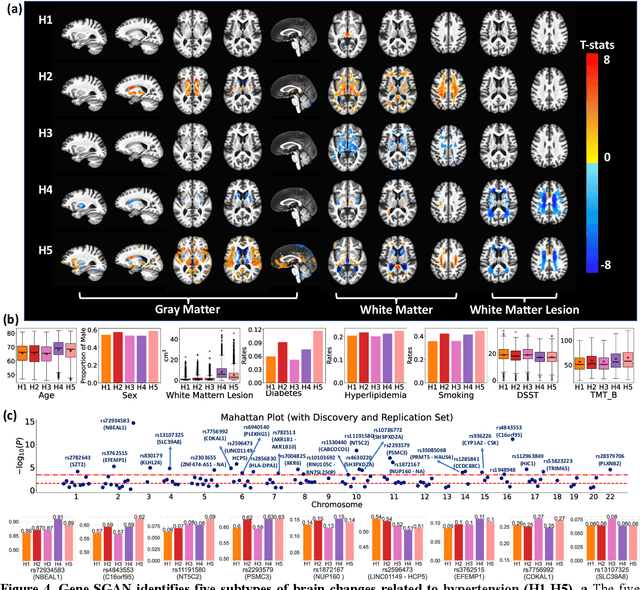
Disease heterogeneity has been a critical challenge for precision diagnosis and treatment, especially in neurologic and neuropsychiatric diseases. Many diseases can display multiple distinct brain phenotypes across individuals, potentially reflecting disease subtypes that can be captured using MRI and machine learning methods. However, biological interpretability and treatment relevance are limited if the derived subtypes are not associated with genetic drivers or susceptibility factors. Herein, we describe Gene-SGAN - a multi-view, weakly-supervised deep clustering method - which dissects disease heterogeneity by jointly considering phenotypic and genetic data, thereby conferring genetic correlations to the disease subtypes and associated endophenotypic signatures. We first validate the generalizability, interpretability, and robustness of Gene-SGAN in semi-synthetic experiments. We then demonstrate its application to real multi-site datasets from 28,858 individuals, deriving subtypes of Alzheimer's disease and brain endophenotypes associated with hypertension, from MRI and SNP data. Derived brain phenotypes displayed significant differences in neuroanatomical patterns, genetic determinants, biological and clinical biomarkers, indicating potentially distinct underlying neuropathologic processes, genetic drivers, and susceptibility factors. Overall, Gene-SGAN is broadly applicable to disease subtyping and endophenotype discovery, and is herein tested on disease-related, genetically-driven neuroimaging phenotypes.
Medical Image Harmonization Using Deep Learning Based Canonical Mapping: Toward Robust and Generalizable Learning in Imaging
Oct 11, 2020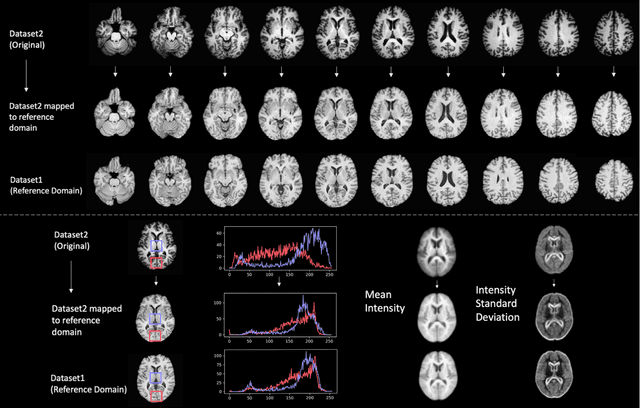

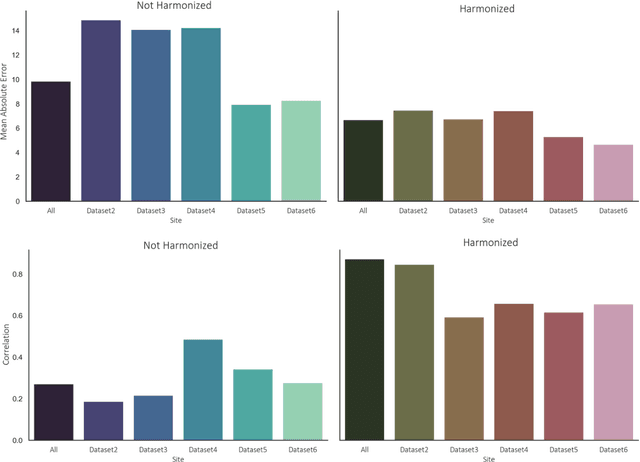
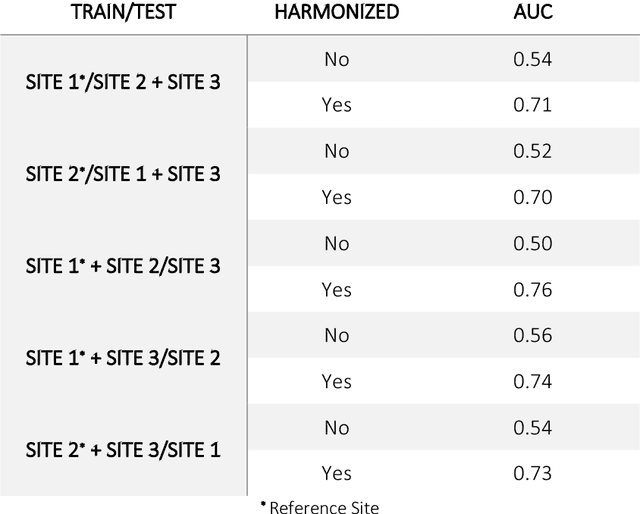
Conventional and deep learning-based methods have shown great potential in the medical imaging domain, as means for deriving diagnostic, prognostic, and predictive biomarkers, and by contributing to precision medicine. However, these methods have yet to see widespread clinical adoption, in part due to limited generalization performance across various imaging devices, acquisition protocols, and patient populations. In this work, we propose a new paradigm in which data from a diverse range of acquisition conditions are "harmonized" to a common reference domain, where accurate model learning and prediction can take place. By learning an unsupervised image to image canonical mapping from diverse datasets to a reference domain using generative deep learning models, we aim to reduce confounding data variation while preserving semantic information, thereby rendering the learning task easier in the reference domain. We test this approach on two example problems, namely MRI-based brain age prediction and classification of schizophrenia, leveraging pooled cohorts of neuroimaging MRI data spanning 9 sites and 9701 subjects. Our results indicate a substantial improvement in these tasks in out-of-sample data, even when training is restricted to a single site.
Online Graph Completion: Multivariate Signal Recovery in Computer Vision
Aug 12, 2020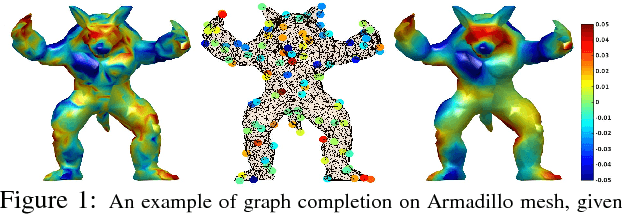
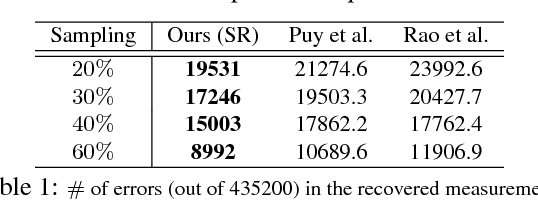
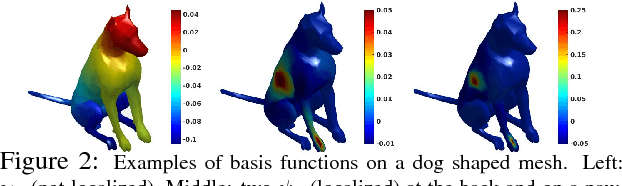
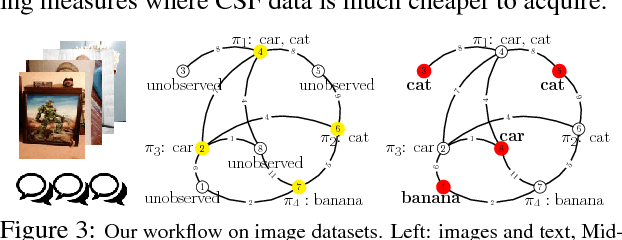
The adoption of "human-in-the-loop" paradigms in computer vision and machine learning is leading to various applications where the actual data acquisition (e.g., human supervision) and the underlying inference algorithms are closely interwined. While classical work in active learning provides effective solutions when the learning module involves classification and regression tasks, many practical issues such as partially observed measurements, financial constraints and even additional distributional or structural aspects of the data typically fall outside the scope of this treatment. For instance, with sequential acquisition of partial measurements of data that manifest as a matrix (or tensor), novel strategies for completion (or collaborative filtering) of the remaining entries have only been studied recently. Motivated by vision problems where we seek to annotate a large dataset of images via a crowdsourced platform or alternatively, complement results from a state-of-the-art object detector using human feedback, we study the "completion" problem defined on graphs, where requests for additional measurements must be made sequentially. We design the optimization model in the Fourier domain of the graph describing how ideas based on adaptive submodularity provide algorithms that work well in practice. On a large set of images collected from Imgur, we see promising results on images that are otherwise difficult to categorize. We also show applications to an experimental design problem in neuroimaging.
DUAL-GLOW: Conditional Flow-Based Generative Model for Modality Transfer
Aug 21, 2019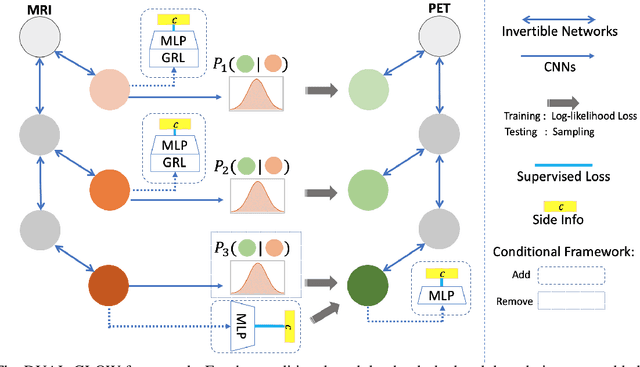


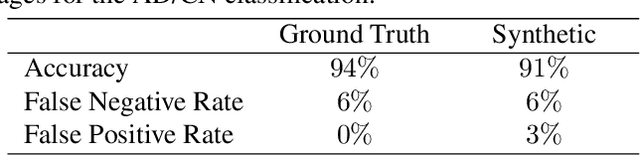
Positron emission tomography (PET) imaging is an imaging modality for diagnosing a number of neurological diseases. In contrast to Magnetic Resonance Imaging (MRI), PET is costly and involves injecting a radioactive substance into the patient. Motivated by developments in modality transfer in vision, we study the generation of certain types of PET images from MRI data. We derive new flow-based generative models which we show perform well in this small sample size regime (much smaller than dataset sizes available in standard vision tasks). Our formulation, DUAL-GLOW, is based on two invertible networks and a relation network that maps the latent spaces to each other. We discuss how given the prior distribution, learning the conditional distribution of PET given the MRI image reduces to obtaining the conditional distribution between the two latent codes w.r.t. the two image types. We also extend our framework to leverage 'side' information (or attributes) when available. By controlling the PET generation through 'conditioning' on age, our model is also able to capture brain FDG-PET (hypometabolism) changes, as a function of age. We present experiments on the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset with 826 subjects, and obtain good performance in PET image synthesis, qualitatively and quantitatively better than recent works.
Finding Differentially Covarying Needles in a Temporally Evolving Haystack: A Scan Statistics Perspective
Nov 20, 2017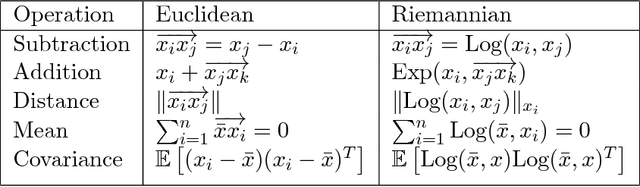

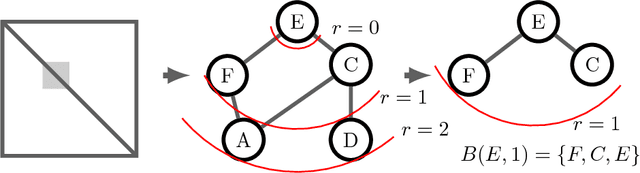
Recent results in coupled or temporal graphical models offer schemes for estimating the relationship structure between features when the data come from related (but distinct) longitudinal sources. A novel application of these ideas is for analyzing group-level differences, i.e., in identifying if trends of estimated objects (e.g., covariance or precision matrices) are different across disparate conditions (e.g., gender or disease). Often, poor effect sizes make detecting the differential signal over the full set of features difficult: for example, dependencies between only a subset of features may manifest differently across groups. In this work, we first give a parametric model for estimating trends in the space of SPD matrices as a function of one or more covariates. We then generalize scan statistics to graph structures, to search over distinct subsets of features (graph partitions) whose temporal dependency structure may show statistically significant group-wise differences. We theoretically analyze the Family Wise Error Rate (FWER) and bounds on Type 1 and Type 2 error. On a cohort of individuals with risk factors for Alzheimer's disease (but otherwise cognitively healthy), we find scientifically interesting group differences where the default analysis, i.e., models estimated on the full graph, do not survive reasonable significance thresholds.
Accelerating Permutation Testing in Voxel-wise Analysis through Subspace Tracking: A new plugin for SnPM
Jul 24, 2017
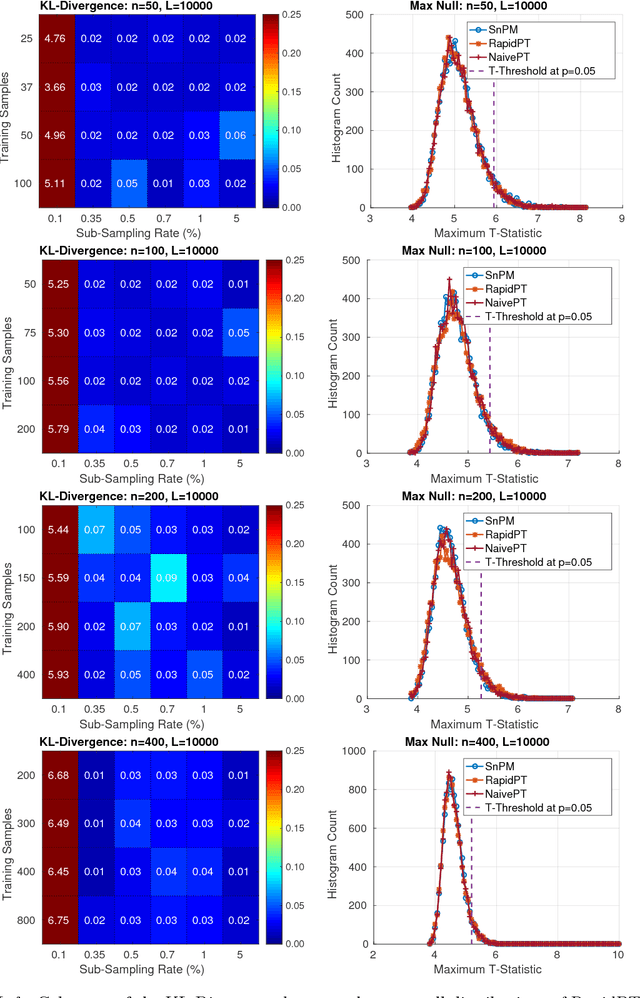

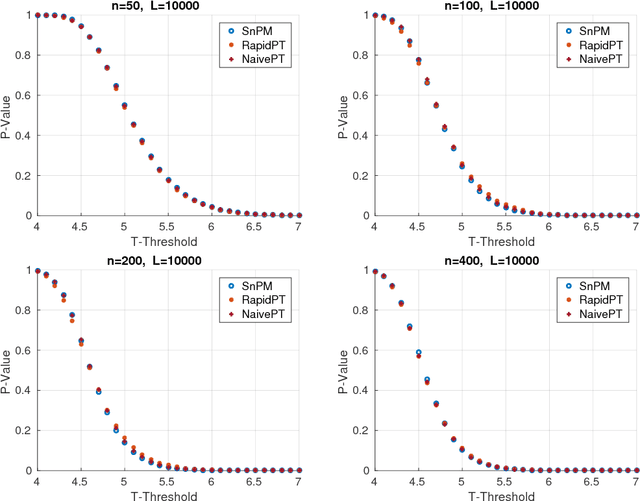
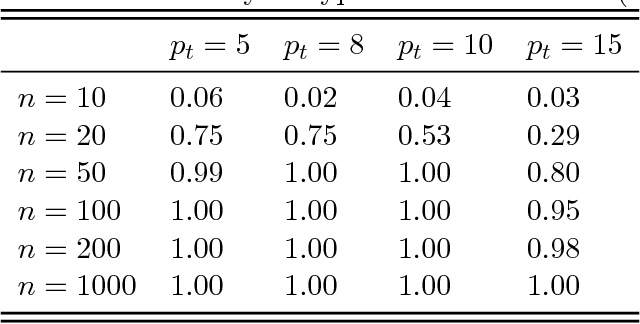
Permutation testing is a non-parametric method for obtaining the max null distribution used to compute corrected $p$-values that provide strong control of false positives. In neuroimaging, however, the computational burden of running such an algorithm can be significant. We find that by viewing the permutation testing procedure as the construction of a very large permutation testing matrix, $T$, one can exploit structural properties derived from the data and the test statistics to reduce the runtime under certain conditions. In particular, we see that $T$ is low-rank plus a low-variance residual. This makes $T$ a good candidate for low-rank matrix completion, where only a very small number of entries of $T$ ($\sim0.35\%$ of all entries in our experiments) have to be computed to obtain a good estimate. Based on this observation, we present RapidPT, an algorithm that efficiently recovers the max null distribution commonly obtained through regular permutation testing in voxel-wise analysis. We present an extensive validation on a synthetic dataset and four varying sized datasets against two baselines: Statistical NonParametric Mapping (SnPM13) and a standard permutation testing implementation (referred as NaivePT). We find that RapidPT achieves its best runtime performance on medium sized datasets ($50 \leq n \leq 200$), with speedups of 1.5x - 38x (vs. SnPM13) and 20x-1000x (vs. NaivePT). For larger datasets ($n \geq 200$) RapidPT outperforms NaivePT (6x - 200x) on all datasets, and provides large speedups over SnPM13 when more than 10000 permutations (2x - 15x) are needed. The implementation is a standalone toolbox and also integrated within SnPM13, able to leverage multi-core architectures when available.
The Incremental Multiresolution Matrix Factorization Algorithm
May 16, 2017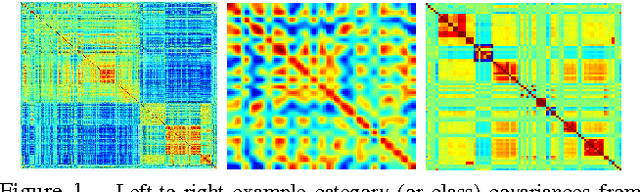


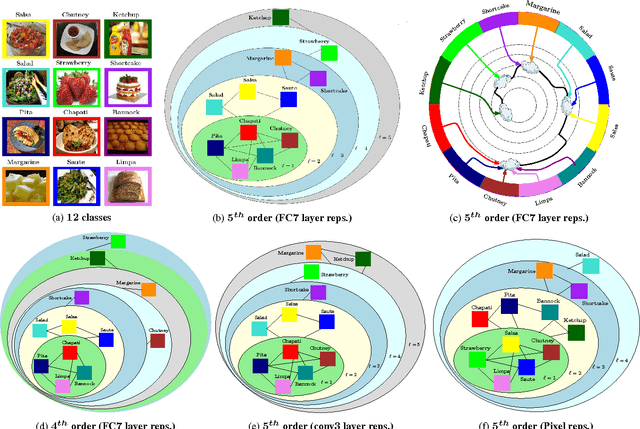
Multiresolution analysis and matrix factorization are foundational tools in computer vision. In this work, we study the interface between these two distinct topics and obtain techniques to uncover hierarchical block structure in symmetric matrices -- an important aspect in the success of many vision problems. Our new algorithm, the incremental multiresolution matrix factorization, uncovers such structure one feature at a time, and hence scales well to large matrices. We describe how this multiscale analysis goes much farther than what a direct global factorization of the data can identify. We evaluate the efficacy of the resulting factorizations for relative leveraging within regression tasks using medical imaging data. We also use the factorization on representations learned by popular deep networks, providing evidence of their ability to infer semantic relationships even when they are not explicitly trained to do so. We show that this algorithm can be used as an exploratory tool to improve the network architecture, and within numerous other settings in vision.