 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiCV at CVPR 2025: The Women in Computer Vision Workshop
Nov 11, 2025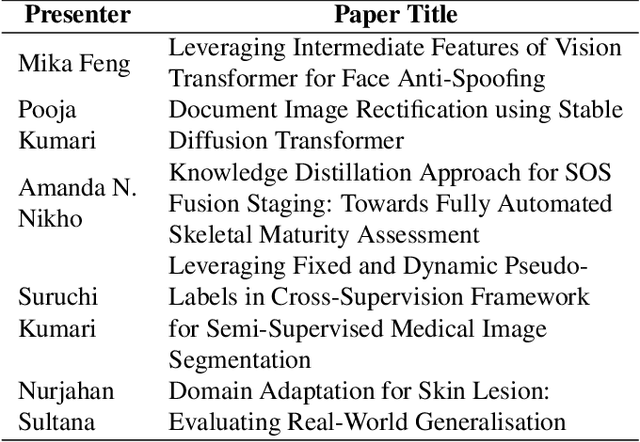
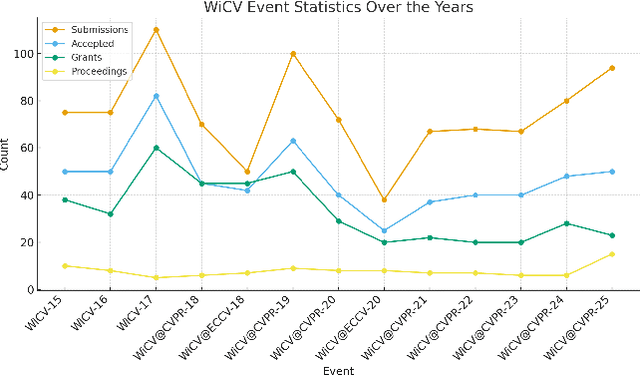
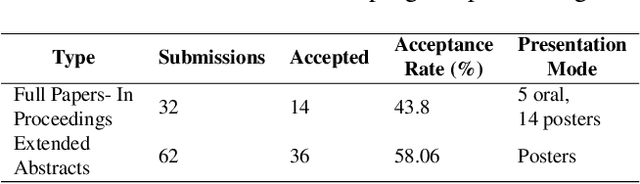

The Women in Computer Vision Workshop (WiCV@CVPR 2025) was held in conjunction with the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025) in Nashville, Tennessee, United States. This report presents an overview of the workshop program, participation statistics, mentorship outcomes, and historical trends from previous WiCV editions. The goal is to document the impact and evolution of WiCV as a reference for future editions and for other initiatives aimed at advancing diversity, equity, and inclusion within the AI and computer vision communities. WiCV@CVPR 2025 marked the 16th edition of this long-standing event dedicated to increasing the visibility, inclusion, and professional growth of women and underrepresented minorities in the computer vision community. This year's workshop featured 14 accepted papers in the CVPR Workshop Proceedings out of 32 full-paper submissions. Five of these were selected for oral presentations, while all 14 were also presented as posters, along with 36 extended abstract posters accepted from 62 short-paper submissions, which are not included in the proceedings. The mentoring program matched 80 mentees with 37 mentors from both academia and industry. The 2025 edition attracted over 100 onsite participants, fostering rich technical and networking interactions across all career stages. Supported by 10 sponsors and approximately $44,000 USD in travel grants and diversity awards, WiCV continued its mission to empower emerging researchers and amplify diverse voices in computer vision.
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024
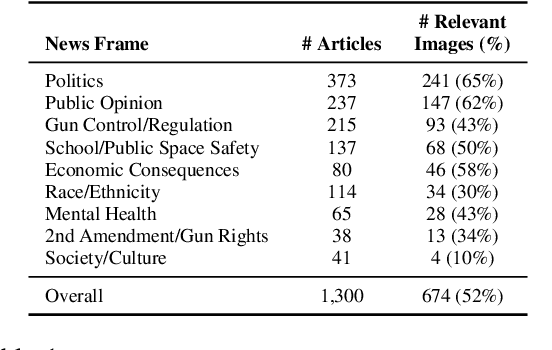

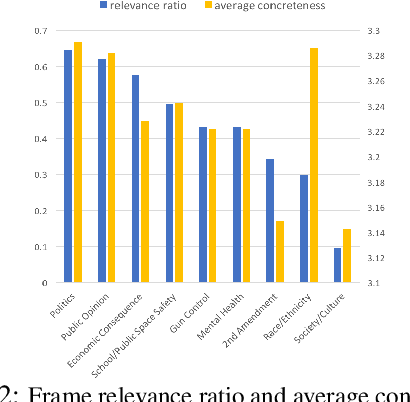
News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.
OpenFraming: We brought the ML; you bring the data. Interact with your data and discover its frames
Aug 16, 2020



When journalists cover a news story, they can cover the story from multiple angles or perspectives. A news article written about COVID-19 for example, might focus on personal preventative actions such as mask-wearing, while another might focus on COVID-19's impact on the economy. These perspectives are called "frames," which when used may influence public perception and opinion of the issue. We introduce a Web-based system for analyzing and classifying frames in text documents. Our goal is to make effective tools for automatic frame discovery and labeling based on topic modeling and deep learning widely accessible to researchers from a diverse array of disciplines. To this end, we provide both state-of-the-art pre-trained frame classification models on various issues as well as a user-friendly pipeline for training novel classification models on user-provided corpora. Researchers can submit their documents and obtain frames of the documents. The degree of user involvement is flexible: they can run models that have been pre-trained on select issues; submit labeled documents and train a new model for frame classification; or submit unlabeled documents and obtain potential frames of the documents. The code making up our system is also open-sourced and well-documented, making the system transparent and expandable. The system is available on-line at http://www.openframing.org and via our GitHub page https://github.com/davidatbu/openFraming .
Online Graph Completion: Multivariate Signal Recovery in Computer Vision
Aug 12, 2020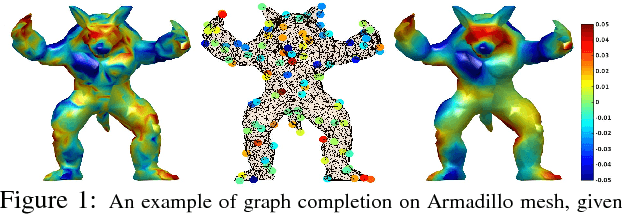
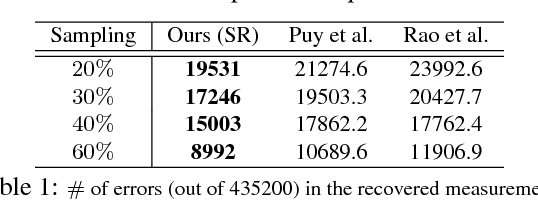
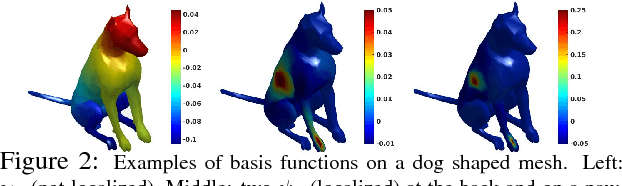
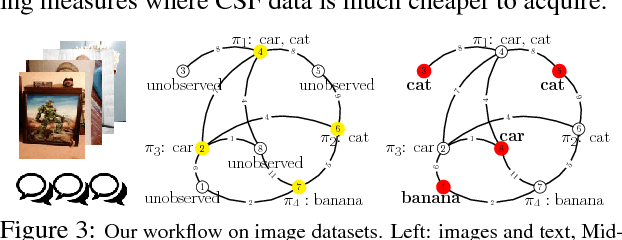
The adoption of "human-in-the-loop" paradigms in computer vision and machine learning is leading to various applications where the actual data acquisition (e.g., human supervision) and the underlying inference algorithms are closely interwined. While classical work in active learning provides effective solutions when the learning module involves classification and regression tasks, many practical issues such as partially observed measurements, financial constraints and even additional distributional or structural aspects of the data typically fall outside the scope of this treatment. For instance, with sequential acquisition of partial measurements of data that manifest as a matrix (or tensor), novel strategies for completion (or collaborative filtering) of the remaining entries have only been studied recently. Motivated by vision problems where we seek to annotate a large dataset of images via a crowdsourced platform or alternatively, complement results from a state-of-the-art object detector using human feedback, we study the "completion" problem defined on graphs, where requests for additional measurements must be made sequentially. We design the optimization model in the Fourier domain of the graph describing how ideas based on adaptive submodularity provide algorithms that work well in practice. On a large set of images collected from Imgur, we see promising results on images that are otherwise difficult to categorize. We also show applications to an experimental design problem in neuroimaging.
SIDOD: A Synthetic Image Dataset for 3D Object Pose Recognition with Distractors
Aug 12, 2020


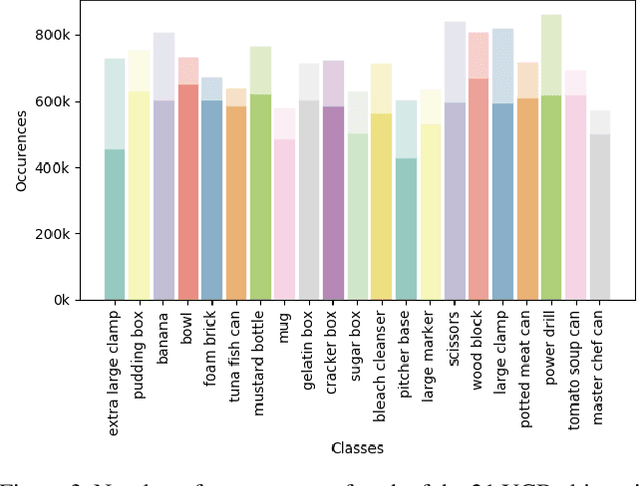
We present a new, publicly-available image dataset generated by the NVIDIA Deep Learning Data Synthesizer intended for use in object detection, pose estimation, and tracking applications. This dataset contains 144k stereo image pairs that synthetically combine 18 camera viewpoints of three photorealistic virtual environments with up to 10 objects (chosen randomly from the 21 object models of the YCB dataset [1]) and flying distractors. Object and camera pose, scene lighting, and quantity of objects and distractors were randomized. Each provided view includes RGB, depth, segmentation, and surface normal images, all pixel level. We describe our approach for domain randomization and provide insight into the decisions that produced the dataset.
Leveraging Affect Transfer Learning for Behavior Prediction in an Intelligent Tutoring System
Feb 12, 2020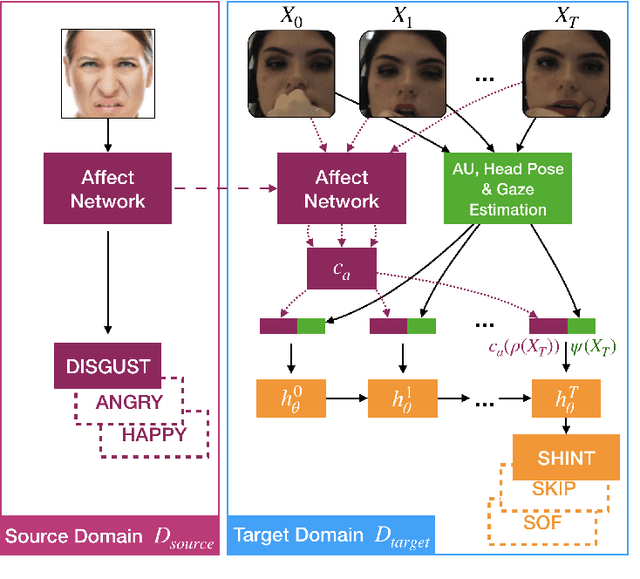


In the context of building an intelligent tutoring system (ITS), which improves student learning outcomes by intervention, we set out to improve prediction of student problem outcome. In essence, we want to predict the outcome of a student answering a problem in an ITS from a video feed by analyzing their face and gestures. For this, we present a novel transfer learning facial affect representation and a user-personalized training scheme that unlocks the potential of this representation. We model the temporal structure of video sequences of students solving math problems using a recurrent neural network architecture. Additionally, we extend the largest dataset of student interactions with an intelligent online math tutor by a factor of two. Our final model, coined ATL-BP (Affect Transfer Learning for Behavior Prediction) achieves an increase in mean F-score over state-of-the-art of 45% on this new dataset in the general case and 50% in a more challenging leave-users-out experimental setting when we use a user-personalized training scheme.
Performance Comparison of Crowdworkers and NLP Tools onNamed-Entity Recognition and Sentiment Analysis of Political Tweets
Feb 11, 2020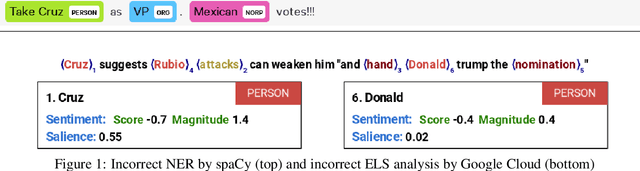
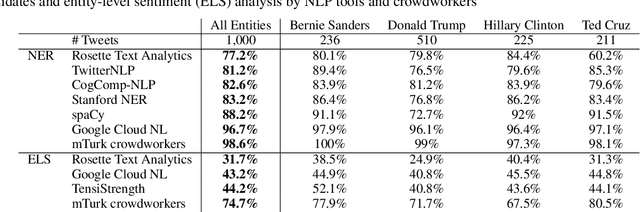
We report results of a comparison of the accuracy of crowdworkers and seven NaturalLanguage Processing (NLP) toolkits in solving two important NLP tasks, named-entity recognition (NER) and entity-level sentiment(ELS) analysis. We here focus on a challenging dataset, 1,000 political tweets that were collected during the U.S. presidential primary election in February 2016. Each tweet refers to at least one of four presidential candidates,i.e., four named entities. The groundtruth, established by experts in political communication, has entity-level sentiment information for each candidate mentioned in the tweet. We tested several commercial and open-source tools. Our experiments show that, for our dataset of political tweets, the most accurate NER system, Google Cloud NL, performed almost on par with crowdworkers, but the most accurate ELS analysis system, TensiStrength, did not match the accuracy of crowdworkers by a large margin of more than 30 percent points.
Scraping Social Media Photos Posted in Kenya and Elsewhere to Detect and Analyze Food Types
Aug 31, 2019
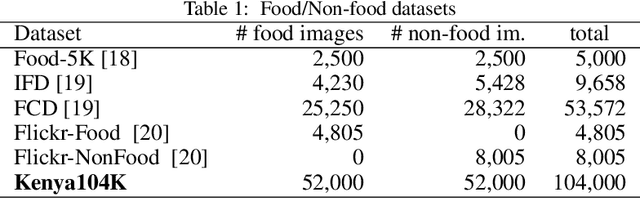

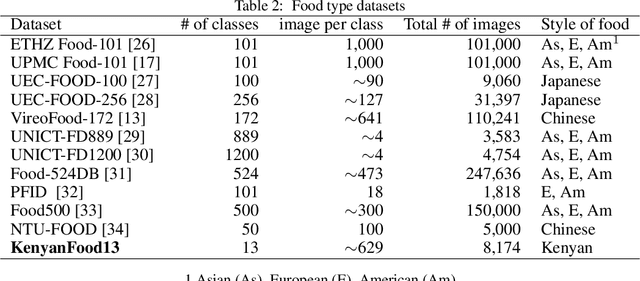
Monitoring population-level changes in diet could be useful for education and for implementing interventions to improve health. Research has shown that data from social media sources can be used for monitoring dietary behavior. We propose a scrape-by-location methodology to create food image datasets from Instagram posts. We used it to collect 3.56 million images over a period of 20 days in March 2019. We also propose a scrape-by-keywords methodology and used it to scrape ~30,000 images and their captions of 38 Kenyan food types. We publish two datasets of 104,000 and 8,174 image/caption pairs, respectively. With the first dataset, Kenya104K, we train a Kenyan Food Classifier, called KenyanFC, to distinguish Kenyan food from non-food images posted in Kenya. We used the second dataset, KenyanFood13, to train a classifier KenyanFTR, short for Kenyan Food Type Recognizer, to recognize 13 popular food types in Kenya. The KenyanFTR is a multimodal deep neural network that can identify 13 types of Kenyan foods using both images and their corresponding captions. Experiments show that the average top-1 accuracy of KenyanFC is 99% over 10,400 tested Instagram images and of KenyanFTR is 81% over 8,174 tested data points. Ablation studies show that three of the 13 food types are particularly difficult to categorize based on image content only and that adding analysis of captions to the image analysis yields a classifier that is 9 percent points more accurate than a classifier that relies only on images. Our food trend analysis revealed that cakes and roasted meats were the most popular foods in photographs on Instagram in Kenya in March 2019.
SAVOIAS: A Diverse, Multi-Category Visual Complexity Dataset
Oct 03, 2018
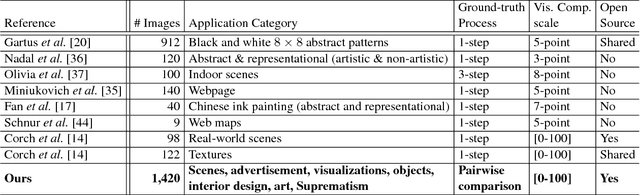


Visual complexity identifies the level of intricacy and details in an image or the level of difficulty to describe the image. It is an important concept in a variety of areas such as cognitive psychology, computer vision and visualization, and advertisement. Yet, efforts to create large, downloadable image datasets with diverse content and unbiased groundtruthing are lacking. In this work, we introduce Savoias, a visual complexity dataset that compromises of more than 1,400 images from seven image categories relevant to the above research areas, namely Scenes, Advertisements, Visualization and infographics, Objects, Interior design, Art, and Suprematism. The images in each category portray diverse characteristics including various low-level and high-level features, objects, backgrounds, textures and patterns, text, and graphics. The ground truth for Savoias is obtained by crowdsourcing more than 37,000 pairwise comparisons of images using the forced-choice methodology and with more than 1,600 contributors. The resulting relative scores are then converted to absolute visual complexity scores using the Bradley-Terry method and matrix completion. When applying five state-of-the-art algorithms to analyze the visual complexity of the images in the Savoias dataset, we found that the scores obtained from these baseline tools only correlate well with crowdsourced labels for abstract patterns in the Suprematism category (Pearson correlation r=0.84). For the other categories, in particular, the objects and advertisement categories, low correlation coefficients were revealed (r=0.3 and 0.56, respectively). These findings suggest that (1) state-of-the-art approaches are mostly insufficient and (2) Savoias enables category-specific method development, which is likely to improve the impact of visual complexity analysis on specific application areas, including computer vision.