 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Loop: Closing the Synthetic Replay Cycle for Continual VLM Learning
Jul 17, 2025Continual learning for vision-language models has achieved remarkable performance through synthetic replay, where samples are generated using Stable Diffusion to regularize during finetuning and retain knowledge. However, real-world downstream applications often exhibit domain-specific nuances and fine-grained semantics not captured by generators, causing synthetic-replay methods to produce misaligned samples that misguide finetuning and undermine retention of prior knowledge. In this work, we propose a LoRA-enhanced synthetic-replay framework that injects task-specific low-rank adapters into a frozen Stable Diffusion model, efficiently capturing each new task's unique visual and semantic patterns. Specifically, we introduce a two-stage, confidence-based sample selection: we first rank real task data by post-finetuning VLM confidence to focus LoRA finetuning on the most representative examples, then generate synthetic samples and again select them by confidence for distillation. Our approach integrates seamlessly with existing replay pipelines-simply swap in the adapted generator to boost replay fidelity. Extensive experiments on the Multi-domain Task Incremental Learning (MTIL) benchmark show that our method outperforms previous synthetic-replay techniques, achieving an optimal balance among plasticity, stability, and zero-shot capability. These results demonstrate the effectiveness of generator adaptation via LoRA for robust continual learning in VLMs.
Detecting Human Artifacts from Text-to-Image Models
Nov 21, 2024Despite recent advancements, text-to-image generation models often produce images containing artifacts, especially in human figures. These artifacts appear as poorly generated human bodies, including distorted, missing, or extra body parts, leading to visual inconsistencies with typical human anatomy and greatly impairing overall fidelity. In this study, we address this challenge by curating Human Artifact Dataset (HAD), the first large-scale dataset specifically designed to identify and localize human artifacts. HAD comprises over 37,000 images generated by several popular text-to-image models, annotated for human artifact localization. Using this dataset, we train the Human Artifact Detection Models (HADM), which can identify diverse artifact types across multiple generative domains and demonstrate strong generalization, even on images from unseen generators. Additionally, to further improve generators' perception of human structural coherence, we use the predictions from our HADM as feedback for diffusion model finetuning. Our experiments confirm a reduction in human artifacts in the resulting model. Furthermore, we showcase a novel application of our HADM in an iterative inpainting framework to correct human artifacts in arbitrary images directly, demonstrating its utility in improving image quality. Our dataset and detection models are available at: \url{https://github.com/wangkaihong/HADM}.
Exploring Consistency in Cross-Domain Transformer for Domain Adaptive Semantic Segmentation
Dec 21, 2022While transformers have greatly boosted performance in semantic segmentation, domain adaptive transformers are not yet well explored. We identify that the domain gap can cause discrepancies in self-attention. Due to this gap, the transformer attends to spurious regions or pixels, which deteriorates accuracy on the target domain. We propose to perform adaptation on attention maps with cross-domain attention layers that share features between the source and the target domains. Specifically, we impose consistency between predictions from cross-domain attention and self-attention modules to encourage similar distribution in the attention and output of the model across domains, i.e., attention-level and output-level alignment. We also enforce consistency in attention maps between different augmented views to further strengthen the attention-based alignment. Combining these two components, our method mitigates the discrepancy in attention maps across domains and further boosts the performance of the transformer under unsupervised domain adaptation settings. Our model outperforms the existing state-of-the-art baseline model on three widely used benchmarks, including GTAV-to-Cityscapes by 1.3 percent point (pp), Synthia-to-Cityscapes by 0.6 pp, and Cityscapes-to-ACDC by 1.1 pp, on average. Additionally, we verify the effectiveness and generalizability of our method through extensive experiments. Our code will be publicly available.
A Unified Framework for Domain Adaptive Pose Estimation
Apr 06, 2022
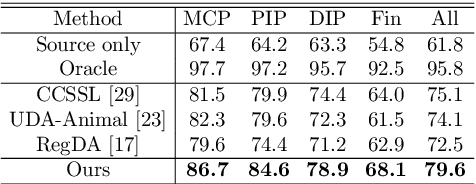
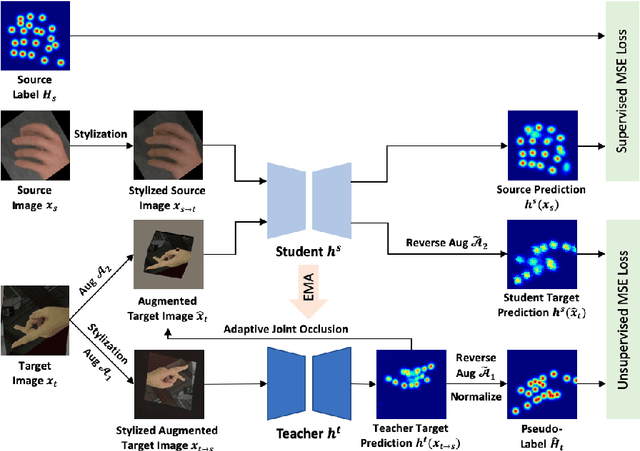
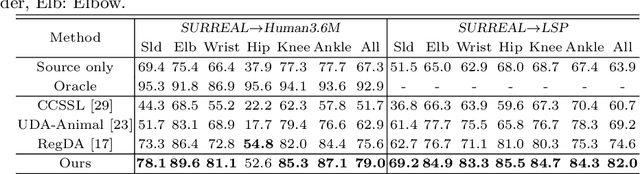
While pose estimation is an important computer vision task, it requires expensive annotation and suffers from domain shift. In this paper, we investigate the problem of domain adaptive 2D pose estimation that transfers knowledge learned on a synthetic source domain to a target domain without supervision. While several domain adaptive pose estimation models have been proposed recently, they are not generic but only focus on either human pose or animal pose estimation, and thus their effectiveness is somewhat limited to specific scenarios. In this work, we propose a unified framework that generalizes well on various domain adaptive pose estimation problems. We propose to align representations using both input-level and output-level cues (pixels and pose labels, respectively), which facilitates the knowledge transfer from the source domain to the unlabeled target domain. Our experiments show that our method achieves state-of-the-art performance under various domain shifts. Our method outperforms existing baselines on human pose estimation by up to 4.5 percent points (pp), hand pose estimation by up to 7.4 pp, and animal pose estimation by up to 4.8 pp for dogs and 3.3 pp for sheep. These results suggest that our method is able to mitigate domain shift on diverse tasks and even unseen domains and objects (e.g., trained on horse and tested on dog).
A Broad Study of Pre-training for Domain Generalization and Adaptation
Mar 25, 2022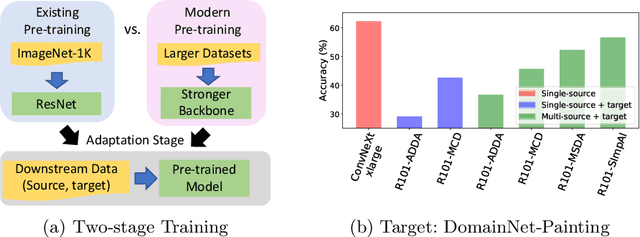
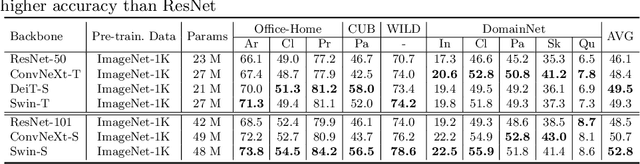
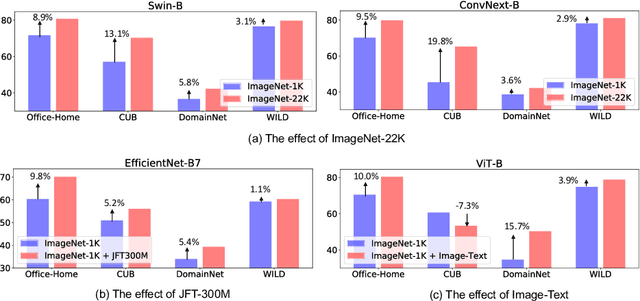
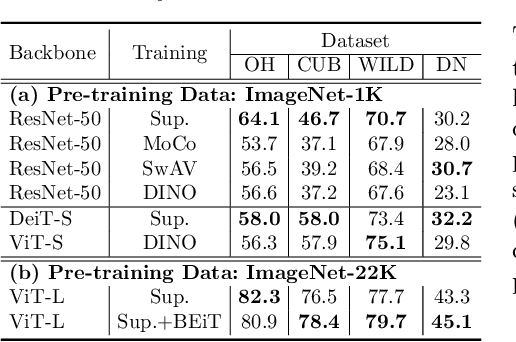
Deep models must learn robust and transferable representations in order to perform well on new domains. While domain transfer methods (e.g., domain adaptation, domain generalization) have been proposed to learn transferable representations across domains, they are typically applied to ResNet backbones pre-trained on ImageNet. Thus, existing works pay little attention to the effects of pre-training on domain transfer tasks. In this paper, we provide a broad study and in-depth analysis of pre-training for domain adaptation and generalization, namely: network architectures, size, pre-training loss, and datasets. We observe that simply using a state-of-the-art backbone outperforms existing state-of-the-art domain adaptation baselines and set new baselines on Office-Home and DomainNet improving by 10.7\% and 5.5\%. We hope that this work can provide more insights for future domain transfer research.
Learning Temporally and Semantically Consistent Unpaired Video-to-video Translation Through Pseudo-Supervision From Synthetic Optical Flow
Jan 15, 2022
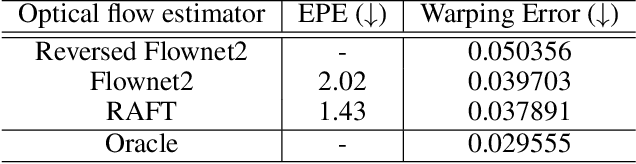


Unpaired video-to-video translation aims to translate videos between a source and a target domain without the need of paired training data, making it more feasible for real applications. Unfortunately, the translated videos generally suffer from temporal and semantic inconsistency. To address this, many existing works adopt spatiotemporal consistency constraints incorporating temporal information based on motion estimation. However, the inaccuracies in the estimation of motion deteriorate the quality of the guidance towards spatiotemporal consistency, which leads to unstable translation. In this work, we propose a novel paradigm that regularizes the spatiotemporal consistency by synthesizing motions in input videos with the generated optical flow instead of estimating them. Therefore, the synthetic motion can be applied in the regularization paradigm to keep motions consistent across domains without the risk of errors in motion estimation. Thereafter, we utilize our unsupervised recycle and unsupervised spatial loss, guided by the pseudo-supervision provided by the synthetic optical flow, to accurately enforce spatiotemporal consistency in both domains. Experiments show that our method is versatile in various scenarios and achieves state-of-the-art performance in generating temporally and semantically consistent videos. Code is available at: https://github.com/wangkaihong/Unsup_Recycle_GAN/.
Consistency Regularization with High-dimensional Non-adversarial Source-guided Perturbation for Unsupervised Domain Adaptation in Segmentation
Sep 18, 2020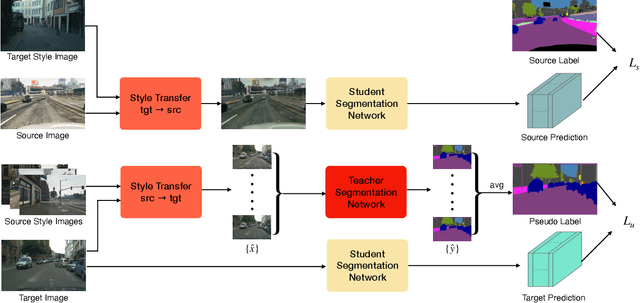
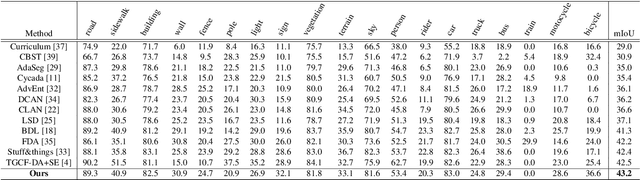
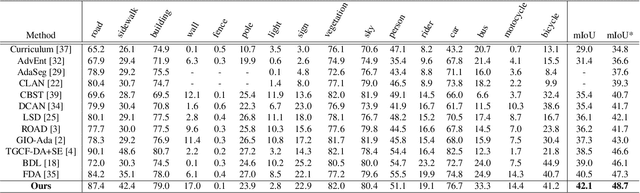

Unsupervised domain adaptation for semantic segmentation has been intensively studied due to the low cost of the pixel-level annotation for synthetic data. The most common approaches try to generate images or features mimicking the distribution in the target domain while preserving the semantic contents in the source domain so that a model can be trained with annotations from the latter. However, such methods highly rely on an image translator or feature extractor trained in an elaborated mechanism including adversarial training, which brings in extra complexity and instability in the adaptation process. Furthermore, these methods mainly focus on taking advantage of the labeled source dataset, leaving the unlabeled target dataset not fully utilized. In this paper, we propose a bidirectional style-induced domain adaptation method, called BiSIDA, that employs consistency regularization to efficiently exploit information from the unlabeled target domain dataset, requiring only a simple neural style transfer model. BiSIDA aligns domains by not only transferring source images into the style of target images but also transferring target images into the style of source images to perform high-dimensional perturbation on the unlabeled target images, which is crucial to the success in applying consistency regularization in segmentation tasks. Extensive experiments show that our BiSIDA achieves new state-of-the-art on two commonly-used synthetic-to-real domain adaptation benchmarks: GTA5-to-CityScapes and SYNTHIA-to-CityScapes.
Learning to Separate: Detecting Heavily-Occluded Objects in Urban Scenes
Dec 09, 2019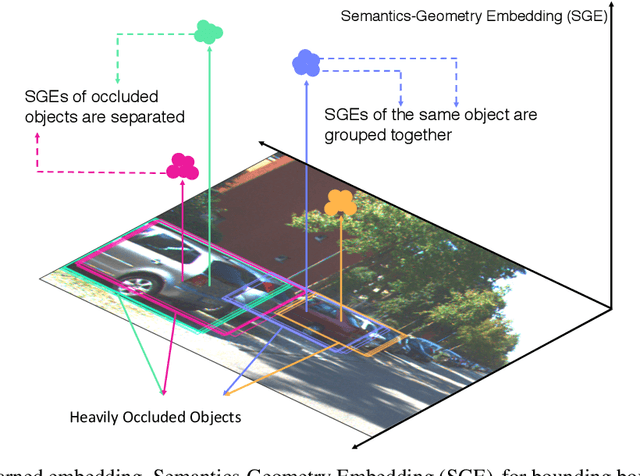
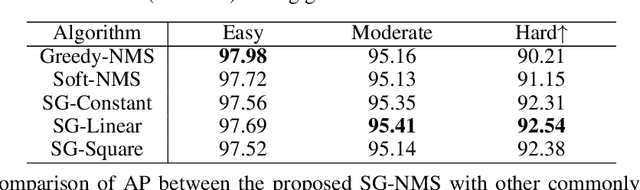
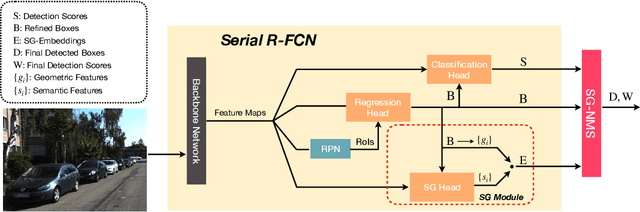
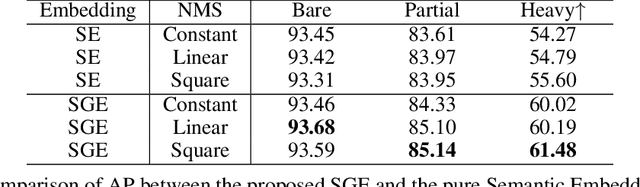
In the past decade, deep learning based visual object detection has received a significant amount of attention, but cases when heavy intra-class occlusions occur are not studied thoroughly. In this work, we propose a novel Non-MaximumSuppression (NMS) algorithm that dramatically improves the detection recall while maintaining high precision in scenes with heavy occlusions. Our NMS algorithm is derived from a novel embedding mechanism, in which the semantic and geometric features of the detected boxes are jointly exploited. The embedding makes it possible to determine whether two heavily-overlapping boxes belong to the same object in the physical world. Our approach is particularly useful for car detection and pedestrian detection in urban scenes where occlusions tend to happen. We validate our approach on two widely-adopted datasets, KITTI and CityPersons, and achieve state-of-the-art performance.
Scraping Social Media Photos Posted in Kenya and Elsewhere to Detect and Analyze Food Types
Aug 31, 2019
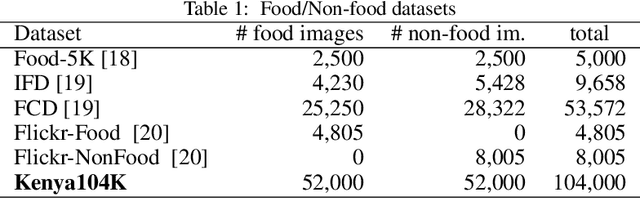

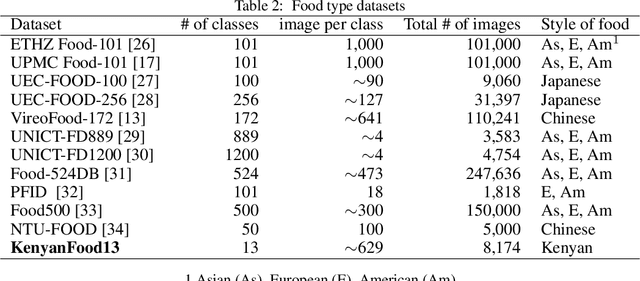
Monitoring population-level changes in diet could be useful for education and for implementing interventions to improve health. Research has shown that data from social media sources can be used for monitoring dietary behavior. We propose a scrape-by-location methodology to create food image datasets from Instagram posts. We used it to collect 3.56 million images over a period of 20 days in March 2019. We also propose a scrape-by-keywords methodology and used it to scrape ~30,000 images and their captions of 38 Kenyan food types. We publish two datasets of 104,000 and 8,174 image/caption pairs, respectively. With the first dataset, Kenya104K, we train a Kenyan Food Classifier, called KenyanFC, to distinguish Kenyan food from non-food images posted in Kenya. We used the second dataset, KenyanFood13, to train a classifier KenyanFTR, short for Kenyan Food Type Recognizer, to recognize 13 popular food types in Kenya. The KenyanFTR is a multimodal deep neural network that can identify 13 types of Kenyan foods using both images and their corresponding captions. Experiments show that the average top-1 accuracy of KenyanFC is 99% over 10,400 tested Instagram images and of KenyanFTR is 81% over 8,174 tested data points. Ablation studies show that three of the 13 food types are particularly difficult to categorize based on image content only and that adding analysis of captions to the image analysis yields a classifier that is 9 percent points more accurate than a classifier that relies only on images. Our food trend analysis revealed that cakes and roasted meats were the most popular foods in photographs on Instagram in Kenya in March 2019.