 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTPano: Multi-Task Panoramic Scene Understanding via Label-Free Integration of Dense Prediction Priors
Feb 05, 2026Comprehensive panoramic scene understanding is critical for immersive applications, yet it remains challenging due to the scarcity of high-resolution, multi-task annotations. While perspective foundation models have achieved success through data scaling, directly adapting them to the panoramic domain often fails due to severe geometric distortions and coordinate system discrepancies. Furthermore, the underlying relations between diverse dense prediction tasks in spherical spaces are underexplored. To address these challenges, we propose MTPano, a robust multi-task panoramic foundation model established by a label-free training pipeline. First, to circumvent data scarcity, we leverage powerful perspective dense priors. We project panoramic images into perspective patches to generate accurate, domain-gap-free pseudo-labels using off-the-shelf foundation models, which are then re-projected to serve as patch-wise supervision. Second, to tackle the interference between task types, we categorize tasks into rotation-invariant (e.g., depth, segmentation) and rotation-variant (e.g., surface normals) groups. We introduce the Panoramic Dual BridgeNet, which disentangles these feature streams via geometry-aware modulation layers that inject absolute position and ray direction priors. To handle the distortion from equirectangular projections (ERP), we incorporate ERP token mixers followed by a dual-branch BridgeNet for interactions with gradient truncation, facilitating beneficial cross-task information sharing while blocking conflicting gradients from incompatible task attributes. Additionally, we introduce auxiliary tasks (image gradient, point map, etc.) to fertilize the cross-task learning process. Extensive experiments demonstrate that MTPano achieves state-of-the-art performance on multiple benchmarks and delivers competitive results against task-specific panoramic specialist foundation models.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
Refer to Anything with Vision-Language Prompts
Jun 05, 2025Recent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024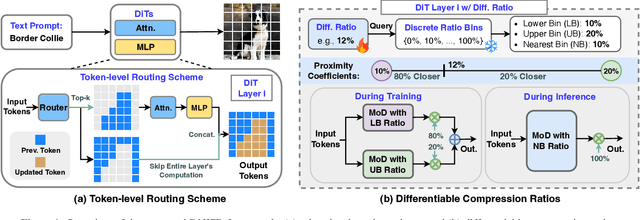



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
FINECAPTION: Compositional Image Captioning Focusing on Wherever You Want at Any Granularity
Nov 23, 2024



The advent of large Vision-Language Models (VLMs) has significantly advanced multimodal tasks, enabling more sophisticated and accurate reasoning across various applications, including image and video captioning, visual question answering, and cross-modal retrieval. Despite their superior capabilities, VLMs struggle with fine-grained image regional composition information perception. Specifically, they have difficulty accurately aligning the segmentation masks with the corresponding semantics and precisely describing the compositional aspects of the referred regions. However, compositionality - the ability to understand and generate novel combinations of known visual and textual components - is critical for facilitating coherent reasoning and understanding across modalities by VLMs. To address this issue, we propose FINECAPTION, a novel VLM that can recognize arbitrary masks as referential inputs and process high-resolution images for compositional image captioning at different granularity levels. To support this endeavor, we introduce COMPOSITIONCAP, a new dataset for multi-grained region compositional image captioning, which introduces the task of compositional attribute-aware regional image captioning. Empirical results demonstrate the effectiveness of our proposed model compared to other state-of-the-art VLMs. Additionally, we analyze the capabilities of current VLMs in recognizing various visual prompts for compositional region image captioning, highlighting areas for improvement in VLM design and training.
Detecting Human Artifacts from Text-to-Image Models
Nov 21, 2024Despite recent advancements, text-to-image generation models often produce images containing artifacts, especially in human figures. These artifacts appear as poorly generated human bodies, including distorted, missing, or extra body parts, leading to visual inconsistencies with typical human anatomy and greatly impairing overall fidelity. In this study, we address this challenge by curating Human Artifact Dataset (HAD), the first large-scale dataset specifically designed to identify and localize human artifacts. HAD comprises over 37,000 images generated by several popular text-to-image models, annotated for human artifact localization. Using this dataset, we train the Human Artifact Detection Models (HADM), which can identify diverse artifact types across multiple generative domains and demonstrate strong generalization, even on images from unseen generators. Additionally, to further improve generators' perception of human structural coherence, we use the predictions from our HADM as feedback for diffusion model finetuning. Our experiments confirm a reduction in human artifacts in the resulting model. Furthermore, we showcase a novel application of our HADM in an iterative inpainting framework to correct human artifacts in arbitrary images directly, demonstrating its utility in improving image quality. Our dataset and detection models are available at: \url{https://github.com/wangkaihong/HADM}.
Good Seed Makes a Good Crop: Discovering Secret Seeds in Text-to-Image Diffusion Models
May 23, 2024
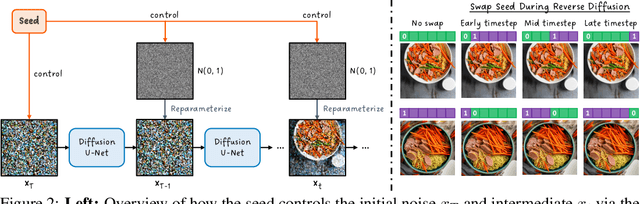


Recent advances in text-to-image (T2I) diffusion models have facilitated creative and photorealistic image synthesis. By varying the random seeds, we can generate various images for a fixed text prompt. Technically, the seed controls the initial noise and, in multi-step diffusion inference, the noise used for reparameterization at intermediate timesteps in the reverse diffusion process. However, the specific impact of the random seed on the generated images remains relatively unexplored. In this work, we conduct a large-scale scientific study into the impact of random seeds during diffusion inference. Remarkably, we reveal that the best 'golden' seed achieved an impressive FID of 21.60, compared to the worst 'inferior' seed's FID of 31.97. Additionally, a classifier can predict the seed number used to generate an image with over 99.9% accuracy in just a few epochs, establishing that seeds are highly distinguishable based on generated images. Encouraged by these findings, we examined the influence of seeds on interpretable visual dimensions. We find that certain seeds consistently produce grayscale images, prominent sky regions, or image borders. Seeds also affect image composition, including object location, size, and depth. Moreover, by leveraging these 'golden' seeds, we demonstrate improved image generation such as high-fidelity inference and diversified sampling. Our investigation extends to inpainting tasks, where we uncover some seeds that tend to insert unwanted text artifacts. Overall, our extensive analyses highlight the importance of selecting good seeds and offer practical utility for image generation.
Detecting Image Attribution for Text-to-Image Diffusion Models in RGB and Beyond
Apr 10, 2024
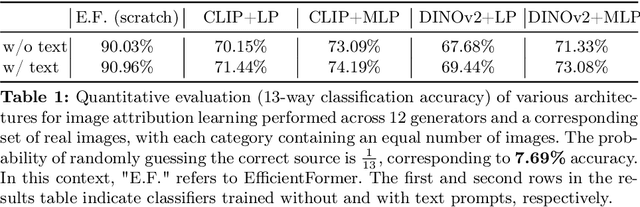

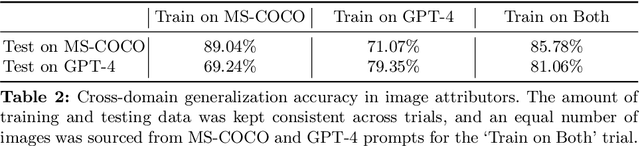
Modern text-to-image (T2I) diffusion models can generate images with remarkable realism and creativity. These advancements have sparked research in fake image detection and attribution, yet prior studies have not fully explored the practical and scientific dimensions of this task. In addition to attributing images to 12 state-of-the-art T2I generators, we provide extensive analyses on what inference stage hyperparameters and image modifications are discernible. Our experiments reveal that initialization seeds are highly detectable, along with other subtle variations in the image generation process to some extent. We further investigate what visual traces are leveraged in image attribution by perturbing high-frequency details and employing mid-level representations of image style and structure. Notably, altering high-frequency information causes only slight reductions in accuracy, and training an attributor on style representations outperforms training on RGB images. Our analyses underscore that fake images are detectable and attributable at various levels of visual granularity than previously explored.
Amodal Completion via Progressive Mixed Context Diffusion
Dec 24, 2023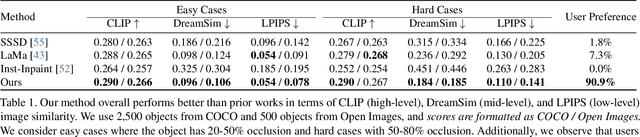
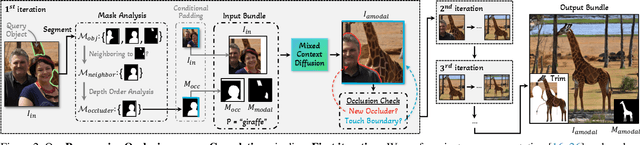
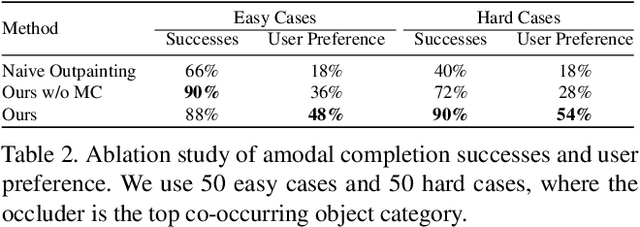
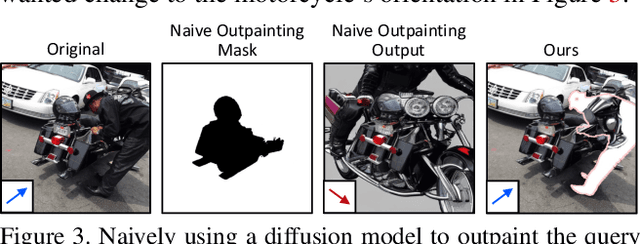
Our brain can effortlessly recognize objects even when partially hidden from view. Seeing the visible of the hidden is called amodal completion; however, this task remains a challenge for generative AI despite rapid progress. We propose to sidestep many of the difficulties of existing approaches, which typically involve a two-step process of predicting amodal masks and then generating pixels. Our method involves thinking outside the box, literally! We go outside the object bounding box to use its context to guide a pre-trained diffusion inpainting model, and then progressively grow the occluded object and trim the extra background. We overcome two technical challenges: 1) how to be free of unwanted co-occurrence bias, which tends to regenerate similar occluders, and 2) how to judge if an amodal completion has succeeded. Our amodal completion method exhibits improved photorealistic completion results compared to existing approaches in numerous successful completion cases. And the best part? It doesn't require any special training or fine-tuning of models.
Perceptual Artifacts Localization for Image Synthesis Tasks
Oct 09, 2023



Recent advancements in deep generative models have facilitated the creation of photo-realistic images across various tasks. However, these generated images often exhibit perceptual artifacts in specific regions, necessitating manual correction. In this study, we present a comprehensive empirical examination of Perceptual Artifacts Localization (PAL) spanning diverse image synthesis endeavors. We introduce a novel dataset comprising 10,168 generated images, each annotated with per-pixel perceptual artifact labels across ten synthesis tasks. A segmentation model, trained on our proposed dataset, effectively localizes artifacts across a range of tasks. Additionally, we illustrate its proficiency in adapting to previously unseen models using minimal training samples. We further propose an innovative zoom-in inpainting pipeline that seamlessly rectifies perceptual artifacts in the generated images. Through our experimental analyses, we elucidate several practical downstream applications, such as automated artifact rectification, non-referential image quality evaluation, and abnormal region detection in images. The dataset and code are released.