 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPNSR: Prior-Enhanced Diffusion Image Super-Resolution via LR-Guided Noise Prediction
Mar 22, 2026Diffusion-based image super-resolution (SR), which aims to reconstruct high-resolution (HR) images from corresponding low-resolution (LR) observations, faces a fundamental trade-off between inference efficiency and reconstruction quality. The state-of-the-art residual-shifting diffusion framework achieves efficient 4-step inference, yet suffers from severe performance degradation in compact sampling trajectories. This is mainly attributed to two core limitations: the inherent suboptimality of unconstrained random Gaussian noise in intermediate steps, which leads to error accumulation and insufficient LR prior guidance, and the initialization bias caused by naive bicubic upsampling. In this paper, we propose LPNSR, a prior-enhanced efficient diffusion framework to address these issues. We first mathematically derive the closed-form analytical solution of the optimal intermediate noise for the residual-shifting diffusion paradigm, and accordingly design an LR-guided multi-input-aware noise predictor to replace random Gaussian noise, embedding LR structural priors into the reverse process while fully preserving the framework's core efficient residual-shifting mechanism. We further mitigate initial bias with a high-quality pre-upsampling network to optimize the diffusion starting point. With a compact 4-step trajectory, LPNSR can be optimized in an end-to-end manner. Extensive experiments demonstrate that LPNSR achieves state-of-the-art perceptual performance on both synthetic and real-world datasets, without relying on any large-scale text-to-image priors. The source code of our method can be found at https://github.com/Faze-Hsw/LPNSR.
Sparse-LaViDa: Sparse Multimodal Discrete Diffusion Language Models
Dec 16, 2025Masked Discrete Diffusion Models (MDMs) have achieved strong performance across a wide range of multimodal tasks, including image understanding, generation, and editing. However, their inference speed remains suboptimal due to the need to repeatedly process redundant masked tokens at every sampling step. In this work, we propose Sparse-LaViDa, a novel modeling framework that dynamically truncates unnecessary masked tokens at each inference step to accelerate MDM sampling. To preserve generation quality, we introduce specialized register tokens that serve as compact representations for the truncated tokens. Furthermore, to ensure consistency between training and inference, we design a specialized attention mask that faithfully matches the truncated sampling procedure during training. Built upon the state-of-the-art unified MDM LaViDa-O, Sparse-LaViDa achieves up to a 2x speedup across diverse tasks including text-to-image generation, image editing, and mathematical reasoning, while maintaining generation quality.
VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction
Dec 11, 2025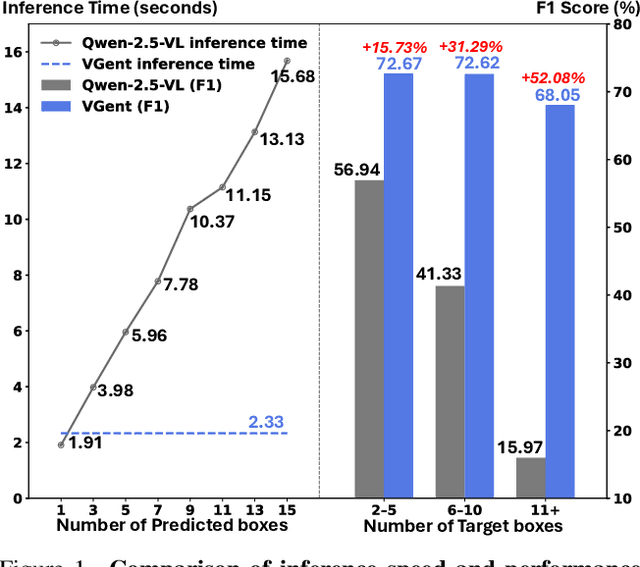
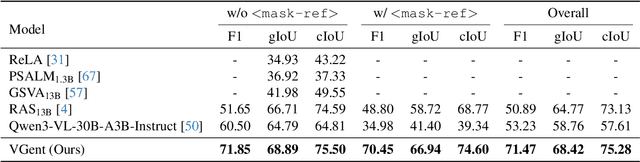
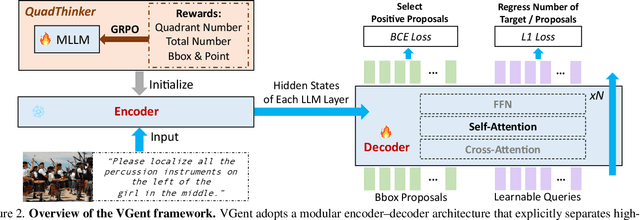
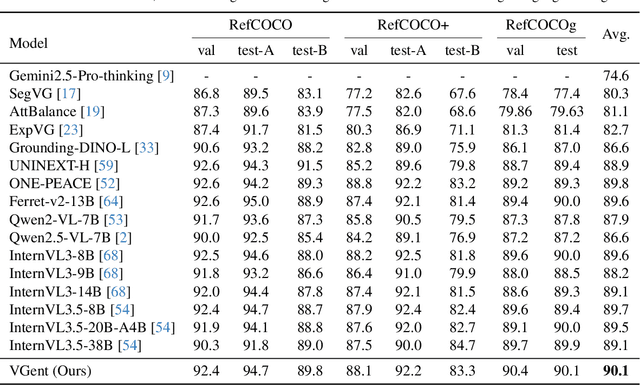
Current visual grounding models are either based on a Multimodal Large Language Model (MLLM) that performs auto-regressive decoding, which is slow and risks hallucinations, or on re-aligning an LLM with vision features to learn new special or object tokens for grounding, which may undermine the LLM's pretrained reasoning ability. In contrast, we propose VGent, a modular encoder-decoder architecture that explicitly disentangles high-level reasoning and low-level bounding box prediction. Specifically, a frozen MLLM serves as the encoder to provide untouched powerful reasoning capabilities, while a decoder takes high-quality boxes proposed by detectors as queries and selects target box(es) via cross-attending on encoder's hidden states. This design fully leverages advances in both object detection and MLLM, avoids the pitfalls of auto-regressive decoding, and enables fast inference. Moreover, it supports modular upgrades of both the encoder and decoder to benefit the whole system: we introduce (i) QuadThinker, an RL-based training paradigm for enhancing multi-target reasoning ability of the encoder; (ii) mask-aware label for resolving detection-segmentation ambiguity; and (iii) global target recognition to improve the recognition of all the targets which benefits the selection among augmented proposals. Experiments on multi-target visual grounding benchmarks show that VGent achieves a new state-of-the-art with +20.6% F1 improvement over prior methods, and further boosts gIoU by +8.2% and cIoU by +5.8% under visual reference challenges, while maintaining constant, fast inference latency.
Refer to Anything with Vision-Language Prompts
Jun 05, 2025Recent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.
Predicting Visual Attention in Graphic Design Documents
Jul 02, 2024



We present a model for predicting visual attention during the free viewing of graphic design documents. While existing works on this topic have aimed at predicting static saliency of graphic designs, our work is the first attempt to predict both spatial attention and dynamic temporal order in which the document regions are fixated by gaze using a deep learning based model. We propose a two-stage model for predicting dynamic attention on such documents, with webpages being our primary choice of document design for demonstration. In the first stage, we predict the saliency maps for each of the document components (e.g. logos, banners, texts, etc. for webpages) conditioned on the type of document layout. These component saliency maps are then jointly used to predict the overall document saliency. In the second stage, we use these layout-specific component saliency maps as the state representation for an inverse reinforcement learning model of fixation scanpath prediction during document viewing. To test our model, we collected a new dataset consisting of eye movements from 41 people freely viewing 450 webpages (the largest dataset of its kind). Experimental results show that our model outperforms existing models in both saliency and scanpath prediction for webpages, and also generalizes very well to other graphic design documents such as comics, posters, mobile UIs, etc. and natural images.
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
Jun 16, 2024Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
Automatic High Resolution Wire Segmentation and Removal
Apr 01, 2023



Wires and powerlines are common visual distractions that often undermine the aesthetics of photographs. The manual process of precisely segmenting and removing them is extremely tedious and may take up hours, especially on high-resolution photos where wires may span the entire space. In this paper, we present an automatic wire clean-up system that eases the process of wire segmentation and removal/inpainting to within a few seconds. We observe several unique challenges: wires are thin, lengthy, and sparse. These are rare properties of subjects that common segmentation tasks cannot handle, especially in high-resolution images. We thus propose a two-stage method that leverages both global and local contexts to accurately segment wires in high-resolution images efficiently, and a tile-based inpainting strategy to remove the wires given our predicted segmentation masks. We also introduce the first wire segmentation benchmark dataset, WireSegHR. Finally, we demonstrate quantitatively and qualitatively that our wire clean-up system enables fully automated wire removal with great generalization to various wire appearances.
LightPainter: Interactive Portrait Relighting with Freehand Scribble
Mar 22, 2023Recent portrait relighting methods have achieved realistic results of portrait lighting effects given a desired lighting representation such as an environment map. However, these methods are not intuitive for user interaction and lack precise lighting control. We introduce LightPainter, a scribble-based relighting system that allows users to interactively manipulate portrait lighting effect with ease. This is achieved by two conditional neural networks, a delighting module that recovers geometry and albedo optionally conditioned on skin tone, and a scribble-based module for relighting. To train the relighting module, we propose a novel scribble simulation procedure to mimic real user scribbles, which allows our pipeline to be trained without any human annotations. We demonstrate high-quality and flexible portrait lighting editing capability with both quantitative and qualitative experiments. User study comparisons with commercial lighting editing tools also demonstrate consistent user preference for our method.
Interactive Portrait Harmonization
Mar 15, 2022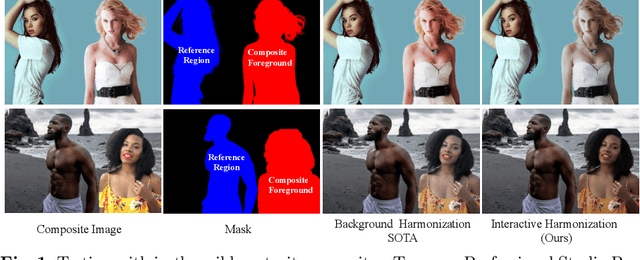
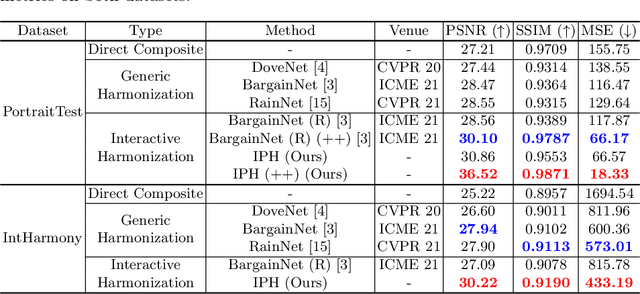

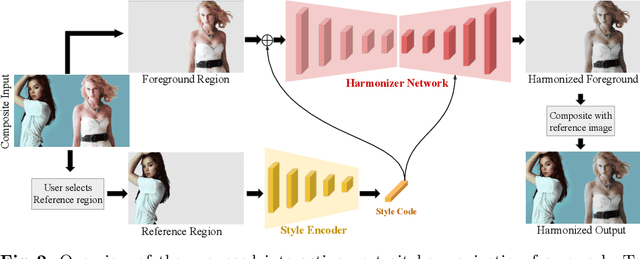
Current image harmonization methods consider the entire background as the guidance for harmonization. However, this may limit the capability for user to choose any specific object/person in the background to guide the harmonization. To enable flexible interaction between user and harmonization, we introduce interactive harmonization, a new setting where the harmonization is performed with respect to a selected \emph{region} in the reference image instead of the entire background. A new flexible framework that allows users to pick certain regions of the background image and use it to guide the harmonization is proposed. Inspired by professional portrait harmonization users, we also introduce a new luminance matching loss to optimally match the color/luminance conditions between the composite foreground and select reference region. This framework provides more control to the image harmonization pipeline achieving visually pleasing portrait edits. Furthermore, we also introduce a new dataset carefully curated for validating portrait harmonization. Extensive experiments on both synthetic and real-world datasets show that the proposed approach is efficient and robust compared to previous harmonization baselines, especially for portraits. Project Webpage at \href{https://jeya-maria-jose.github.io/IPH-web/}{https://jeya-maria-jose.github.io/IPH-web/}
Lite Vision Transformer with Enhanced Self-Attention
Dec 20, 2021
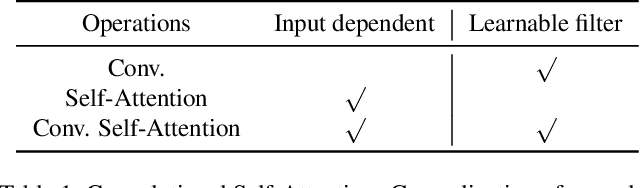
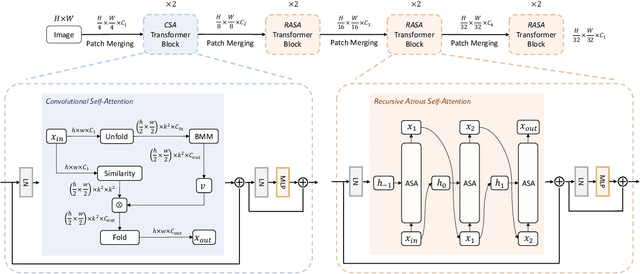
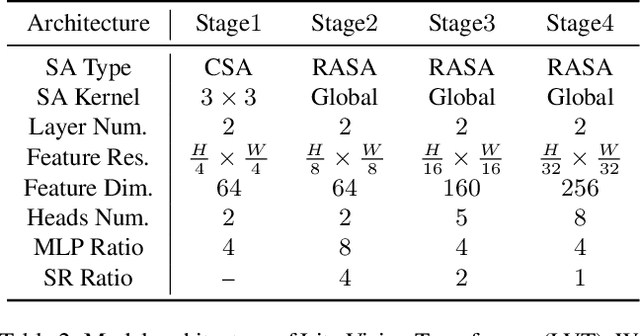
Despite the impressive representation capacity of vision transformer models, current light-weight vision transformer models still suffer from inconsistent and incorrect dense predictions at local regions. We suspect that the power of their self-attention mechanism is limited in shallower and thinner networks. We propose Lite Vision Transformer (LVT), a novel light-weight transformer network with two enhanced self-attention mechanisms to improve the model performances for mobile deployment. For the low-level features, we introduce Convolutional Self-Attention (CSA). Unlike previous approaches of merging convolution and self-attention, CSA introduces local self-attention into the convolution within a kernel of size 3x3 to enrich low-level features in the first stage of LVT. For the high-level features, we propose Recursive Atrous Self-Attention (RASA), which utilizes the multi-scale context when calculating the similarity map and a recursive mechanism to increase the representation capability with marginal extra parameter cost. The superiority of LVT is demonstrated on ImageNet recognition, ADE20K semantic segmentation, and COCO panoptic segmentation. The code is made publicly available.