 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Visual Attention in Graphic Design Documents
Jul 02, 2024We present a model for predicting visual attention during the free viewing of graphic design documents. While existing works on this topic have aimed at predicting static saliency of graphic designs, our work is the first attempt to predict both spatial attention and dynamic temporal order in which the document regions are fixated by gaze using a deep learning based model. We propose a two-stage model for predicting dynamic attention on such documents, with webpages being our primary choice of document design for demonstration. In the first stage, we predict the saliency maps for each of the document components (e.g. logos, banners, texts, etc. for webpages) conditioned on the type of document layout. These component saliency maps are then jointly used to predict the overall document saliency. In the second stage, we use these layout-specific component saliency maps as the state representation for an inverse reinforcement learning model of fixation scanpath prediction during document viewing. To test our model, we collected a new dataset consisting of eye movements from 41 people freely viewing 450 webpages (the largest dataset of its kind). Experimental results show that our model outperforms existing models in both saliency and scanpath prediction for webpages, and also generalizes very well to other graphic design documents such as comics, posters, mobile UIs, etc. and natural images.
Self-supervised co-salient object detection via feature correspondence at multiple scales
Mar 27, 2024Our paper introduces a novel two-stage self-supervised approach for detecting co-occurring salient objects (CoSOD) in image groups without requiring segmentation annotations. Unlike existing unsupervised methods that rely solely on patch-level information (e.g. clustering patch descriptors) or on computation heavy off-the-shelf components for CoSOD, our lightweight model leverages feature correspondences at both patch and region levels, significantly improving prediction performance. In the first stage, we train a self-supervised network that detects co-salient regions by computing local patch-level feature correspondences across images. We obtain the segmentation predictions using confidence-based adaptive thresholding. In the next stage, we refine these intermediate segmentations by eliminating the detected regions (within each image) whose averaged feature representations are dissimilar to the foreground feature representation averaged across all the cross-attention maps (from the previous stage). Extensive experiments on three CoSOD benchmark datasets show that our self-supervised model outperforms the corresponding state-of-the-art models by a huge margin (e.g. on the CoCA dataset, our model has a 13.7% F-measure gain over the SOTA unsupervised CoSOD model). Notably, our self-supervised model also outperforms several recent fully supervised CoSOD models on the three test datasets (e.g., on the CoCA dataset, our model has a 4.6% F-measure gain over a recent supervised CoSOD model).
Decoding the visual attention of pathologists to reveal their level of expertise
Mar 25, 2024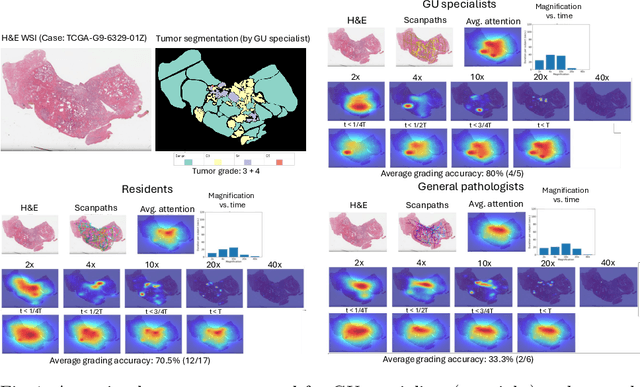
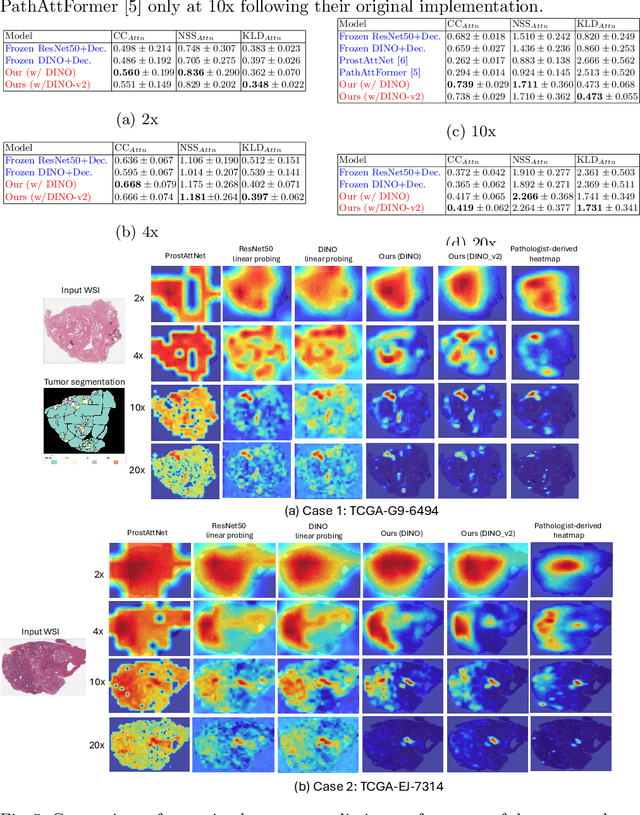
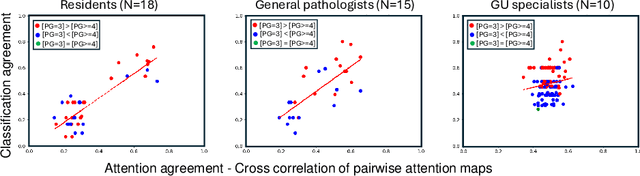

We present a method for classifying the expertise of a pathologist based on how they allocated their attention during a cancer reading. We engage this decoding task by developing a novel method for predicting the attention of pathologists as they read whole-slide Images (WSIs) of prostate and make cancer grade classifications. Our ground truth measure of a pathologists' attention is the x, y and z (magnification) movement of their viewport as they navigated through WSIs during readings, and to date we have the attention behavior of 43 pathologists reading 123 WSIs. These data revealed that specialists have higher agreement in both their attention and cancer grades compared to general pathologists and residents, suggesting that sufficient information may exist in their attention behavior to classify their expertise level. To attempt this, we trained a transformer-based model to predict the visual attention heatmaps of resident, general, and specialist (GU) pathologists during Gleason grading. Based solely on a pathologist's attention during a reading, our model was able to predict their level of expertise with 75.3%, 56.1%, and 77.2% accuracy, respectively, better than chance and baseline models. Our model therefore enables a pathologist's expertise level to be easily and objectively evaluated, important for pathology training and competency assessment. Tools developed from our model could also be used to help pathology trainees learn how to read WSIs like an expert.
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
Visual attention analysis of pathologists examining whole slide images of Prostate cancer
Feb 17, 2022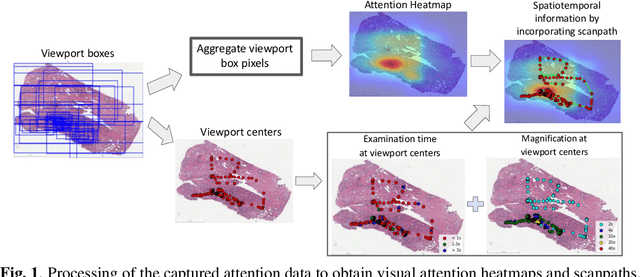
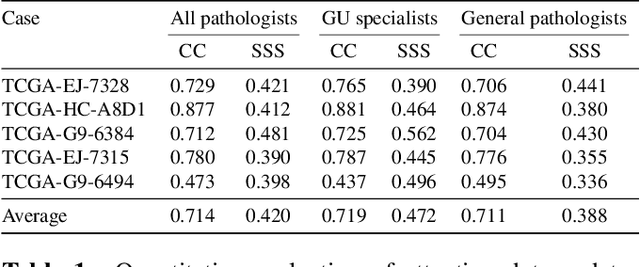
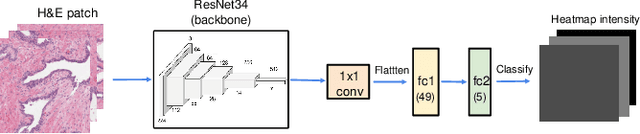
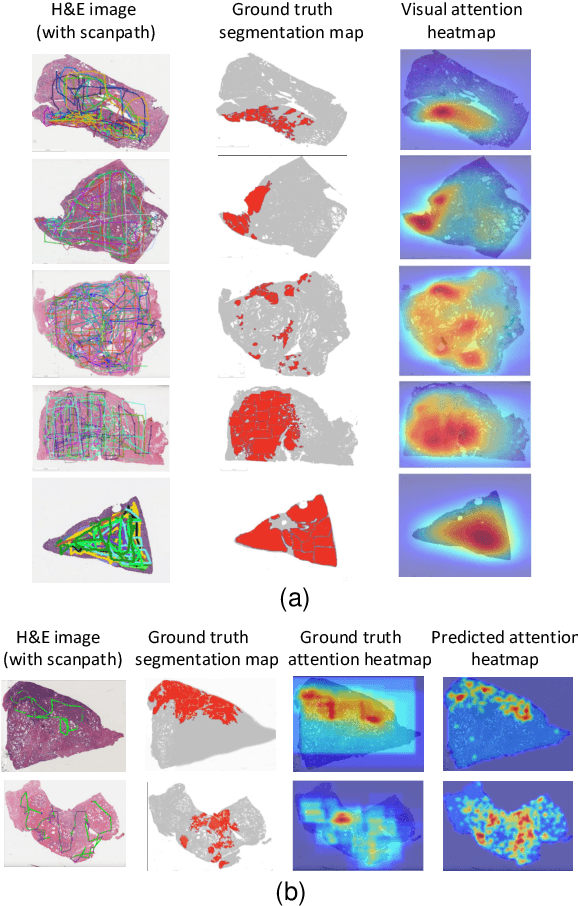
We study the attention of pathologists as they examine whole-slide images (WSIs) of prostate cancer tissue using a digital microscope. To the best of our knowledge, our study is the first to report in detail how pathologists navigate WSIs of prostate cancer as they accumulate information for their diagnoses. We collected slide navigation data (i.e., viewport location, magnification level, and time) from 13 pathologists in 2 groups (5 genitourinary (GU) specialists and 8 general pathologists) and generated visual attention heatmaps and scanpaths. Each pathologist examined five WSIs from the TCGA PRAD dataset, which were selected by a GU pathology specialist. We examined and analyzed the distributions of visual attention for each group of pathologists after each WSI was examined. To quantify the relationship between a pathologist's attention and evidence for cancer in the WSI, we obtained tumor annotations from a genitourinary specialist. We used these annotations to compute the overlap between the distribution of visual attention and annotated tumor region to identify strong correlations. Motivated by this analysis, we trained a deep learning model to predict visual attention on unseen WSIs. We find that the attention heatmaps predicted by our model correlate quite well with the ground truth attention heatmap and tumor annotations on a test set of 17 WSIs by using various spatial and temporal evaluation metrics.
Deep Reinforcement Learning in Financial Markets
Jul 25, 2019



In this paper we explore the usage of deep reinforcement learning algorithms to automatically generate consistently profitable, robust, uncorrelated trading signals in any general financial market. In order to do this, we present a novel Markov decision process (MDP) model to capture the financial trading markets. We review and propose various modifications to existing approaches and explore different techniques to succinctly capture the market dynamics to model the markets. We then go on to use deep reinforcement learning to enable the agent (the algorithm) to learn how to take profitable trades in any market on its own, while suggesting various methodology changes and leveraging the unique representation of the FMDP (financial MDP) to tackle the primary challenges faced in similar works. Through our experimentation results, we go on to show that our model could be easily extended to two very different financial markets and generates a positively robust performance in all conducted experiments.
A dense subgraph based algorithm for compact salient image region detection
Dec 19, 2015


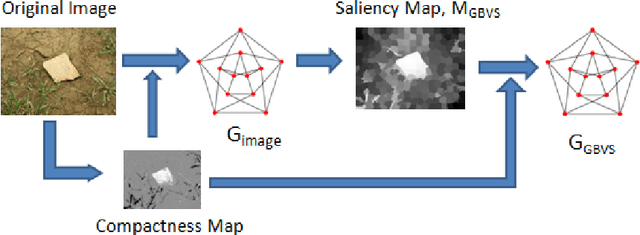
We present an algorithm for graph based saliency computation that utilizes the underlying dense subgraphs in finding visually salient regions in an image. To compute the salient regions, the model first obtains a saliency map using random walks on a Markov chain. Next, k-dense subgraphs are detected to further enhance the salient regions in the image. Dense subgraphs convey more information about local graph structure than simple centrality measures. To generate the Markov chain, intensity and color features of an image in addition to region compactness is used. For evaluating the proposed model, we do extensive experiments on benchmark image data sets. The proposed method performs comparable to well-known algorithms in salient region detection.