 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Object Grouping in Self-supervised Vision Transformers
Mar 14, 2026Vision foundation models trained with self-supervised objectives achieve strong performance across diverse tasks and exhibit emergent object segmentation properties. However, their alignment with human object perception remains poorly understood. Here, we introduce a behavioral benchmark in which participants make same/different object judgments for dot pairs on naturalistic scenes, scaling up a classical psychophysics paradigm to over 1000 trials. We test a diverse set of vision models using a simple readout from their representations to predict subjects' reaction times. We observe a steady improvement across model generations, with both architecture and training objective contributing to alignment, and transformer-based models trained with the DINO self-supervised objective showing the strongest performance. To investigate the source of this improvement, we propose a novel metric to quantify the object-centric component of representations by measuring patch similarity within and between objects. Across models, stronger object-centric structure predicts human segmentation behavior more accurately. We further show that matching the Gram matrix of supervised transformer models, capturing similarity structure across image patches, with that of a self-supervised model through distillation improves their alignment with human behavior, converging with the prior finding that Gram anchoring improves DINOv3's feature quality. Together, these results demonstrate that self-supervised vision models capture object structure in a behaviorally human-like manner, and that Gram matrix structure plays a role in driving perceptual alignment.
Generating metamers of human scene understanding
Jan 16, 2026Human vision combines low-resolution "gist" information from the visual periphery with sparse but high-resolution information from fixated locations to construct a coherent understanding of a visual scene. In this paper, we introduce MetamerGen, a tool for generating scenes that are aligned with latent human scene representations. MetamerGen is a latent diffusion model that combines peripherally obtained scene gist information with information obtained from scene-viewing fixations to generate image metamers for what humans understand after viewing a scene. Generating images from both high and low resolution (i.e. "foveated") inputs constitutes a novel image-to-image synthesis problem, which we tackle by introducing a dual-stream representation of the foveated scenes consisting of DINOv2 tokens that fuse detailed features from fixated areas with peripherally degraded features capturing scene context. To evaluate the perceptual alignment of MetamerGen generated images to latent human scene representations, we conducted a same-different behavioral experiment where participants were asked for a "same" or "different" response between the generated and the original image. With that, we identify scene generations that are indeed metamers for the latent scene representations formed by the viewers. MetamerGen is a powerful tool for understanding scene understanding. Our proof-of-concept analyses uncovered specific features at multiple levels of visual processing that contributed to human judgments. While it can generate metamers even conditioned on random fixations, we find that high-level semantic alignment most strongly predicts metamerism when the generated scenes are conditioned on viewers' own fixated regions.
Look Hear: Gaze Prediction for Speech-directed Human Attention
Jul 28, 2024
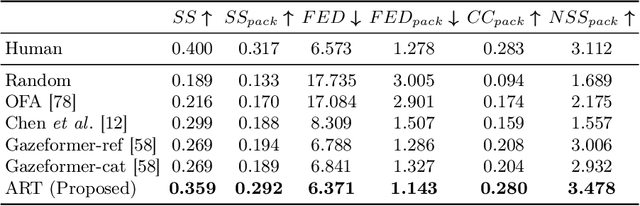

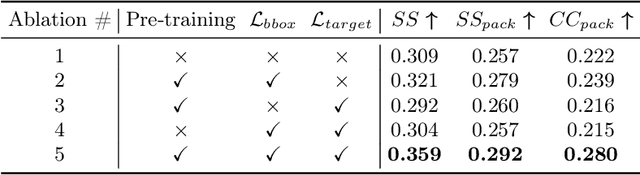
For computer systems to effectively interact with humans using spoken language, they need to understand how the words being generated affect the users' moment-by-moment attention. Our study focuses on the incremental prediction of attention as a person is seeing an image and hearing a referring expression defining the object in the scene that should be fixated by gaze. To predict the gaze scanpaths in this incremental object referral task, we developed the Attention in Referral Transformer model or ART, which predicts the human fixations spurred by each word in a referring expression. ART uses a multimodal transformer encoder to jointly learn gaze behavior and its underlying grounding tasks, and an autoregressive transformer decoder to predict, for each word, a variable number of fixations based on fixation history. To train ART, we created RefCOCO-Gaze, a large-scale dataset of 19,738 human gaze scanpaths, corresponding to 2,094 unique image-expression pairs, from 220 participants performing our referral task. In our quantitative and qualitative analyses, ART not only outperforms existing methods in scanpath prediction, but also appears to capture several human attention patterns, such as waiting, scanning, and verification.
Predicting Visual Attention in Graphic Design Documents
Jul 02, 2024



We present a model for predicting visual attention during the free viewing of graphic design documents. While existing works on this topic have aimed at predicting static saliency of graphic designs, our work is the first attempt to predict both spatial attention and dynamic temporal order in which the document regions are fixated by gaze using a deep learning based model. We propose a two-stage model for predicting dynamic attention on such documents, with webpages being our primary choice of document design for demonstration. In the first stage, we predict the saliency maps for each of the document components (e.g. logos, banners, texts, etc. for webpages) conditioned on the type of document layout. These component saliency maps are then jointly used to predict the overall document saliency. In the second stage, we use these layout-specific component saliency maps as the state representation for an inverse reinforcement learning model of fixation scanpath prediction during document viewing. To test our model, we collected a new dataset consisting of eye movements from 41 people freely viewing 450 webpages (the largest dataset of its kind). Experimental results show that our model outperforms existing models in both saliency and scanpath prediction for webpages, and also generalizes very well to other graphic design documents such as comics, posters, mobile UIs, etc. and natural images.
Affinity-based Attention in Self-supervised Transformers Predicts Dynamics of Object Grouping in Humans
Jun 01, 2023

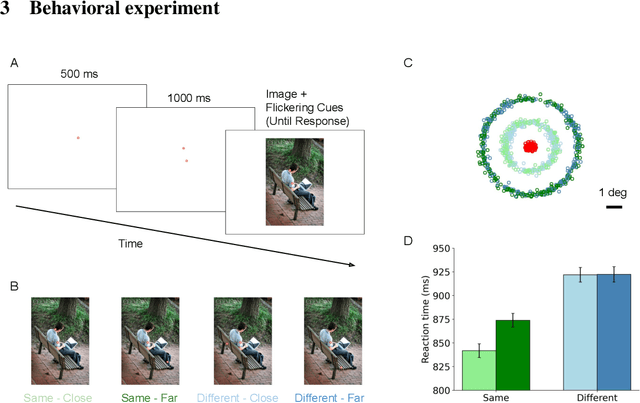

The spreading of attention has been proposed as a mechanism for how humans group features to segment objects. However, such a mechanism has not yet been implemented and tested in naturalistic images. Here, we leverage the feature maps from self-supervised vision Transformers and propose a model of human object-based attention spreading and segmentation. Attention spreads within an object through the feature affinity signal between different patches of the image. We also collected behavioral data on people grouping objects in natural images by judging whether two dots are on the same object or on two different objects. We found that our models of affinity spread that were built on feature maps from the self-supervised Transformers showed significant improvement over baseline and CNN based models on predicting reaction time patterns of humans, despite not being trained on the task or with any other object labels. Our work provides new benchmarks for evaluating models of visual representation learning including Transformers.
Predicting Human Attention using Computational Attention
Apr 04, 2023



Most models of visual attention are aimed at predicting either top-down or bottom-up control, as studied using different visual search and free-viewing tasks. We propose Human Attention Transformer (HAT), a single model predicting both forms of attention control. HAT is the new state-of-the-art (SOTA) in predicting the scanpath of fixations made during target-present and target-absent search, and matches or exceeds SOTA in the prediction of taskless free-viewing fixation scanpaths. HAT achieves this new SOTA by using a novel transformer-based architecture and a simplified foveated retina that collectively create a spatio-temporal awareness akin to the dynamic visual working memory of humans. Unlike previous methods that rely on a coarse grid of fixation cells and experience information loss due to fixation discretization, HAT features a dense-prediction architecture and outputs a dense heatmap for each fixation, thus avoiding discretizing fixations. HAT sets a new standard in computational attention, which emphasizes both effectiveness and generality. HAT's demonstrated scope and applicability will likely inspire the development of new attention models that can better predict human behavior in various attention-demanding scenarios.
Gazeformer: Scalable, Effective and Fast Prediction of Goal-Directed Human Attention
Mar 27, 2023



Predicting human gaze is important in Human-Computer Interaction (HCI). However, to practically serve HCI applications, gaze prediction models must be scalable, fast, and accurate in their spatial and temporal gaze predictions. Recent scanpath prediction models focus on goal-directed attention (search). Such models are limited in their application due to a common approach relying on trained target detectors for all possible objects, and the availability of human gaze data for their training (both not scalable). In response, we pose a new task called ZeroGaze, a new variant of zero-shot learning where gaze is predicted for never-before-searched objects, and we develop a novel model, Gazeformer, to solve the ZeroGaze problem. In contrast to existing methods using object detector modules, Gazeformer encodes the target using a natural language model, thus leveraging semantic similarities in scanpath prediction. We use a transformer-based encoder-decoder architecture because transformers are particularly useful for generating contextual representations. Gazeformer surpasses other models by a large margin on the ZeroGaze setting. It also outperforms existing target-detection models on standard gaze prediction for both target-present and target-absent search tasks. In addition to its improved performance, Gazeformer is more than five times faster than the state-of-the-art target-present visual search model.
Reconstruction-guided attention improves the robustness and shape processing of neural networks
Sep 27, 2022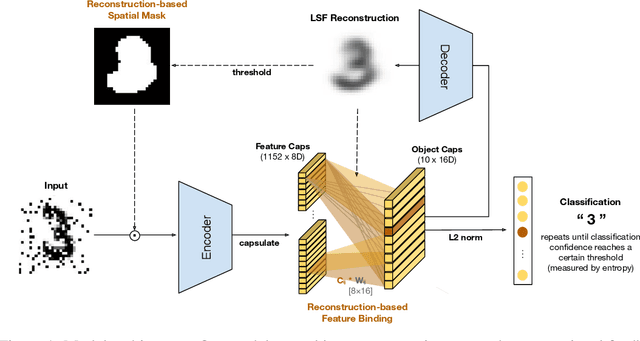
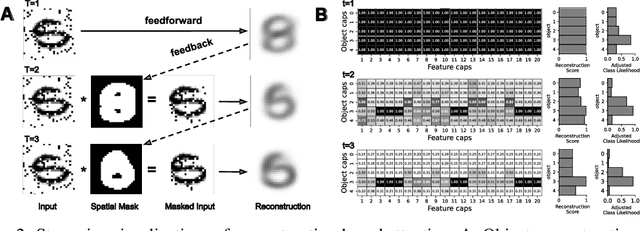
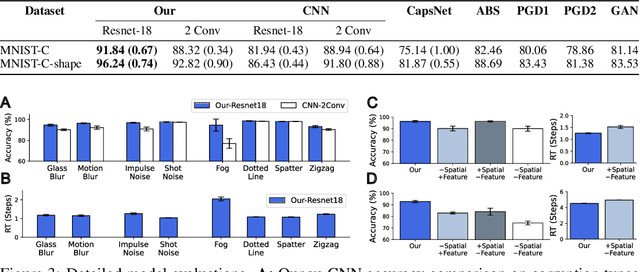
Many visual phenomena suggest that humans use top-down generative or reconstructive processes to create visual percepts (e.g., imagery, object completion, pareidolia), but little is known about the role reconstruction plays in robust object recognition. We built an iterative encoder-decoder network that generates an object reconstruction and used it as top-down attentional feedback to route the most relevant spatial and feature information to feed-forward object recognition processes. We tested this model using the challenging out-of-distribution digit recognition dataset, MNIST-C, where 15 different types of transformation and corruption are applied to handwritten digit images. Our model showed strong generalization performance against various image perturbations, on average outperforming all other models including feedforward CNNs and adversarially trained networks. Our model is particularly robust to blur, noise, and occlusion corruptions, where shape perception plays an important role. Ablation studies further reveal two complementary roles of spatial and feature-based attention in robust object recognition, with the former largely consistent with spatial masking benefits in the attention literature (the reconstruction serves as a mask) and the latter mainly contributing to the model's inference speed (i.e., number of time steps to reach a certain confidence threshold) by reducing the space of possible object hypotheses. We also observed that the model sometimes hallucinates a non-existing pattern out of noise, leading to highly interpretable human-like errors. Our study shows that modeling reconstruction-based feedback endows AI systems with a powerful attention mechanism, which can help us understand the role of generating perception in human visual processing.
Target-absent Human Attention
Jul 04, 2022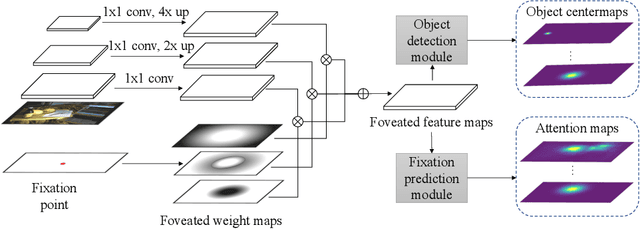
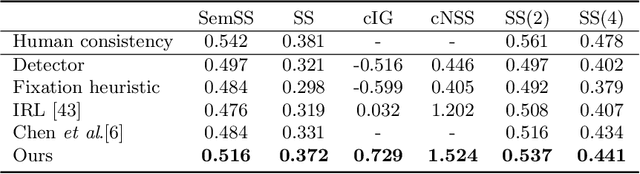


The prediction of human gaze behavior is important for building human-computer interactive systems that can anticipate a user's attention. Computer vision models have been developed to predict the fixations made by people as they search for target objects. But what about when the image has no target? Equally important is to know how people search when they cannot find a target, and when they would stop searching. In this paper, we propose the first data-driven computational model that addresses the search-termination problem and predicts the scanpath of search fixations made by people searching for targets that do not appear in images. We model visual search as an imitation learning problem and represent the internal knowledge that the viewer acquires through fixations using a novel state representation that we call Foveated Feature Maps (FFMs). FFMs integrate a simulated foveated retina into a pretrained ConvNet that produces an in-network feature pyramid, all with minimal computational overhead. Our method integrates FFMs as the state representation in inverse reinforcement learning. Experimentally, we improve the state of the art in predicting human target-absent search behavior on the COCO-Search18 dataset
Recurrent Attention Models with Object-centric Capsule Representation for Multi-object Recognition
Oct 11, 2021
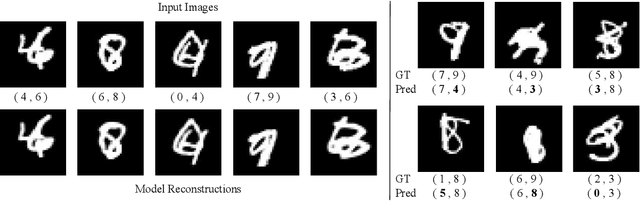


The visual system processes a scene using a sequence of selective glimpses, each driven by spatial and object-based attention. These glimpses reflect what is relevant to the ongoing task and are selected through recurrent processing and recognition of the objects in the scene. In contrast, most models treat attention selection and recognition as separate stages in a feedforward process. Here we show that using capsule networks to create an object-centric hidden representation in an encoder-decoder model with iterative glimpse attention yields effective integration of attention and recognition. We evaluate our model on three multi-object recognition tasks; highly overlapping digits, digits among distracting clutter and house numbers, and show that it learns to effectively move its glimpse window, recognize and reconstruct the objects, all with only the classification as supervision. Our work takes a step toward a general architecture for how to integrate recurrent object-centric representation into the planning of attentional glimpses.