 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Goal-directed Human Attention Using Inverse Reinforcement Learning
Paper and Code

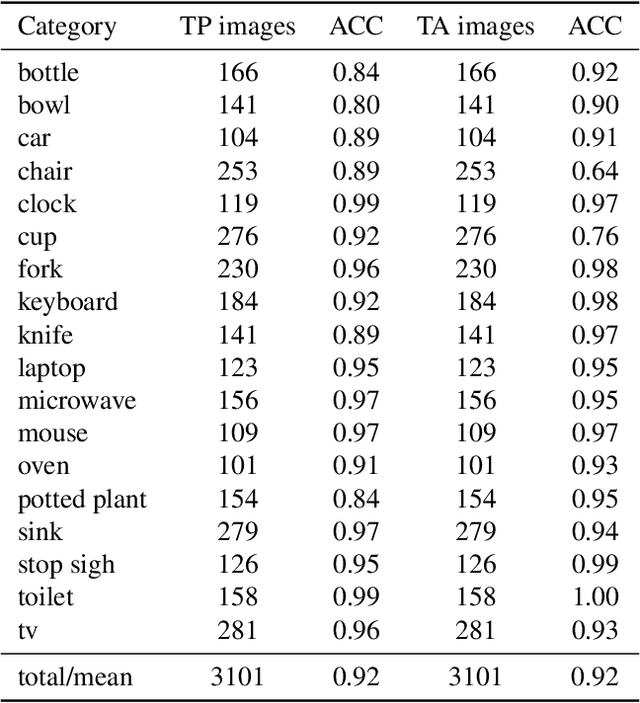

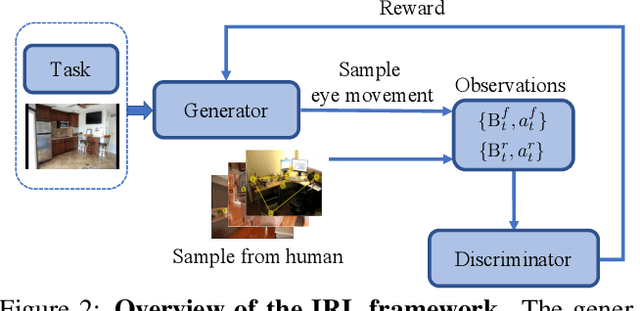
Being able to predict human gaze behavior has obvious importance for behavioral vision and for computer vision applications. Most models have mainly focused on predicting free-viewing behavior using saliency maps, but these predictions do not generalize to goal-directed behavior, such as when a person searches for a visual target object. We propose the first inverse reinforcement learning (IRL) model to learn the internal reward function and policy used by humans during visual search. The viewer's internal belief states were modeled as dynamic contextual belief maps of object locations. These maps were learned by IRL and then used to predict behavioral scanpaths for multiple target categories. To train and evaluate our IRL model we created COCO-Search18, which is now the largest dataset of high-quality search fixations in existence. COCO-Search18 has 10 participants searching for each of 18 target-object categories in 6202 images, making about 300,000 goal-directed fixations. When trained and evaluated on COCO-Search18, the IRL model outperformed baseline models in predicting search fixation scanpaths, both in terms of similarity to human search behavior and search efficiency. Finally, reward maps recovered by the IRL model reveal distinctive target-dependent patterns of object prioritization, which we interpret as a learned object context.