 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Attention Models with Object-centric Capsule Representation for Multi-object Recognition
Paper and Code

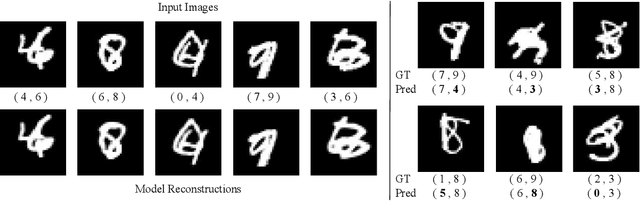


The visual system processes a scene using a sequence of selective glimpses, each driven by spatial and object-based attention. These glimpses reflect what is relevant to the ongoing task and are selected through recurrent processing and recognition of the objects in the scene. In contrast, most models treat attention selection and recognition as separate stages in a feedforward process. Here we show that using capsule networks to create an object-centric hidden representation in an encoder-decoder model with iterative glimpse attention yields effective integration of attention and recognition. We evaluate our model on three multi-object recognition tasks; highly overlapping digits, digits among distracting clutter and house numbers, and show that it learns to effectively move its glimpse window, recognize and reconstruct the objects, all with only the classification as supervision. Our work takes a step toward a general architecture for how to integrate recurrent object-centric representation into the planning of attentional glimpses.