 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Object Grouping in Self-supervised Vision Transformers
Mar 14, 2026Vision foundation models trained with self-supervised objectives achieve strong performance across diverse tasks and exhibit emergent object segmentation properties. However, their alignment with human object perception remains poorly understood. Here, we introduce a behavioral benchmark in which participants make same/different object judgments for dot pairs on naturalistic scenes, scaling up a classical psychophysics paradigm to over 1000 trials. We test a diverse set of vision models using a simple readout from their representations to predict subjects' reaction times. We observe a steady improvement across model generations, with both architecture and training objective contributing to alignment, and transformer-based models trained with the DINO self-supervised objective showing the strongest performance. To investigate the source of this improvement, we propose a novel metric to quantify the object-centric component of representations by measuring patch similarity within and between objects. Across models, stronger object-centric structure predicts human segmentation behavior more accurately. We further show that matching the Gram matrix of supervised transformer models, capturing similarity structure across image patches, with that of a self-supervised model through distillation improves their alignment with human behavior, converging with the prior finding that Gram anchoring improves DINOv3's feature quality. Together, these results demonstrate that self-supervised vision models capture object structure in a behaviorally human-like manner, and that Gram matrix structure plays a role in driving perceptual alignment.
Transformer brain encoders explain human high-level visual responses
May 22, 2025A major goal of neuroscience is to understand brain computations during visual processing in naturalistic settings. A dominant approach is to use image-computable deep neural networks trained with different task objectives as a basis for linear encoding models. However, in addition to requiring tuning a large number of parameters, the linear encoding approach ignores the structure of the feature maps both in the brain and the models. Recently proposed alternatives have focused on decomposing the linear mapping to spatial and feature components but focus on finding static receptive fields for units that are applicable only in early visual areas. In this work, we employ the attention mechanism used in the transformer architecture to study how retinotopic visual features can be dynamically routed to category-selective areas in high-level visual processing. We show that this computational motif is significantly more powerful than alternative methods in predicting brain activity during natural scene viewing, across different feature basis models and modalities. We also show that this approach is inherently more interpretable, without the need to create importance maps, by interpreting the attention routing signal for different high-level categorical areas. Our approach proposes a mechanistic model of how visual information from retinotopic maps can be routed based on the relevance of the input content to different category-selective regions.
Meta-Learning an In-Context Transformer Model of Human Higher Visual Cortex
May 21, 2025Understanding functional representations within higher visual cortex is a fundamental question in computational neuroscience. While artificial neural networks pretrained on large-scale datasets exhibit striking representational alignment with human neural responses, learning image-computable models of visual cortex relies on individual-level, large-scale fMRI datasets. The necessity for expensive, time-intensive, and often impractical data acquisition limits the generalizability of encoders to new subjects and stimuli. BraInCoRL uses in-context learning to predict voxelwise neural responses from few-shot examples without any additional finetuning for novel subjects and stimuli. We leverage a transformer architecture that can flexibly condition on a variable number of in-context image stimuli, learning an inductive bias over multiple subjects. During training, we explicitly optimize the model for in-context learning. By jointly conditioning on image features and voxel activations, our model learns to directly generate better performing voxelwise models of higher visual cortex. We demonstrate that BraInCoRL consistently outperforms existing voxelwise encoder designs in a low-data regime when evaluated on entirely novel images, while also exhibiting strong test-time scaling behavior. The model also generalizes to an entirely new visual fMRI dataset, which uses different subjects and fMRI data acquisition parameters. Further, BraInCoRL facilitates better interpretability of neural signals in higher visual cortex by attending to semantically relevant stimuli. Finally, we show that our framework enables interpretable mappings from natural language queries to voxel selectivity.
Affinity-based Attention in Self-supervised Transformers Predicts Dynamics of Object Grouping in Humans
Jun 01, 2023

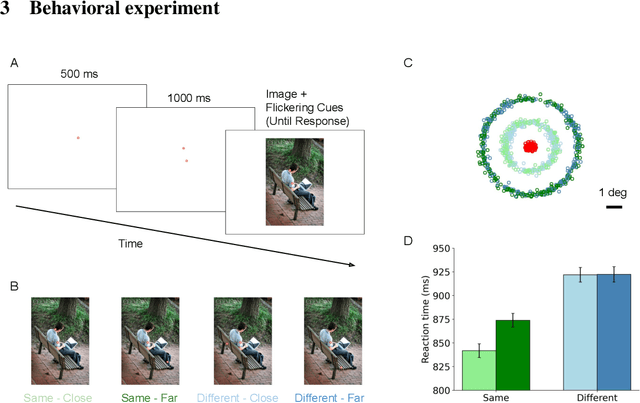

The spreading of attention has been proposed as a mechanism for how humans group features to segment objects. However, such a mechanism has not yet been implemented and tested in naturalistic images. Here, we leverage the feature maps from self-supervised vision Transformers and propose a model of human object-based attention spreading and segmentation. Attention spreads within an object through the feature affinity signal between different patches of the image. We also collected behavioral data on people grouping objects in natural images by judging whether two dots are on the same object or on two different objects. We found that our models of affinity spread that were built on feature maps from the self-supervised Transformers showed significant improvement over baseline and CNN based models on predicting reaction time patterns of humans, despite not being trained on the task or with any other object labels. Our work provides new benchmarks for evaluating models of visual representation learning including Transformers.
Reconstruction-guided attention improves the robustness and shape processing of neural networks
Sep 27, 2022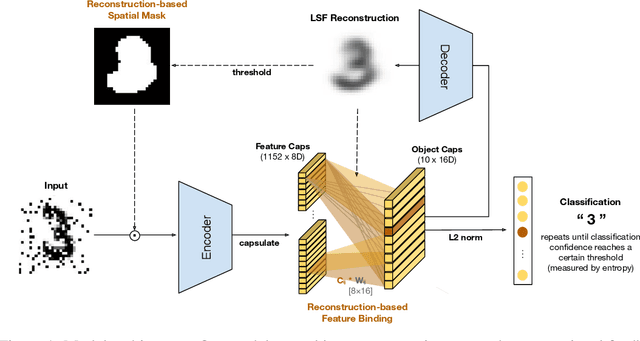
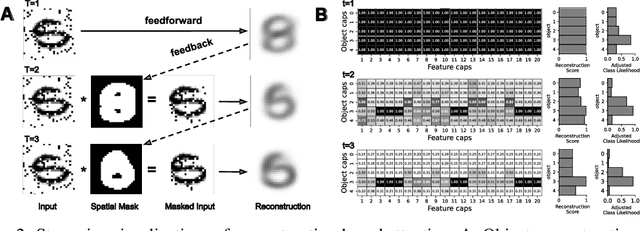
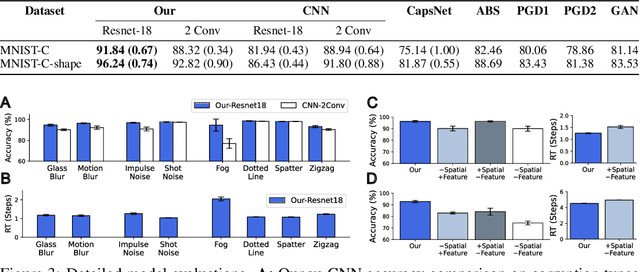
Many visual phenomena suggest that humans use top-down generative or reconstructive processes to create visual percepts (e.g., imagery, object completion, pareidolia), but little is known about the role reconstruction plays in robust object recognition. We built an iterative encoder-decoder network that generates an object reconstruction and used it as top-down attentional feedback to route the most relevant spatial and feature information to feed-forward object recognition processes. We tested this model using the challenging out-of-distribution digit recognition dataset, MNIST-C, where 15 different types of transformation and corruption are applied to handwritten digit images. Our model showed strong generalization performance against various image perturbations, on average outperforming all other models including feedforward CNNs and adversarially trained networks. Our model is particularly robust to blur, noise, and occlusion corruptions, where shape perception plays an important role. Ablation studies further reveal two complementary roles of spatial and feature-based attention in robust object recognition, with the former largely consistent with spatial masking benefits in the attention literature (the reconstruction serves as a mask) and the latter mainly contributing to the model's inference speed (i.e., number of time steps to reach a certain confidence threshold) by reducing the space of possible object hypotheses. We also observed that the model sometimes hallucinates a non-existing pattern out of noise, leading to highly interpretable human-like errors. Our study shows that modeling reconstruction-based feedback endows AI systems with a powerful attention mechanism, which can help us understand the role of generating perception in human visual processing.
Recurrent Attention Models with Object-centric Capsule Representation for Multi-object Recognition
Oct 11, 2021
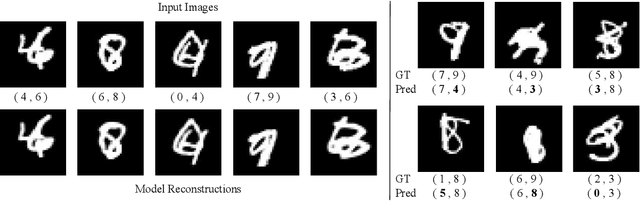


The visual system processes a scene using a sequence of selective glimpses, each driven by spatial and object-based attention. These glimpses reflect what is relevant to the ongoing task and are selected through recurrent processing and recognition of the objects in the scene. In contrast, most models treat attention selection and recognition as separate stages in a feedforward process. Here we show that using capsule networks to create an object-centric hidden representation in an encoder-decoder model with iterative glimpse attention yields effective integration of attention and recognition. We evaluate our model on three multi-object recognition tasks; highly overlapping digits, digits among distracting clutter and house numbers, and show that it learns to effectively move its glimpse window, recognize and reconstruct the objects, all with only the classification as supervision. Our work takes a step toward a general architecture for how to integrate recurrent object-centric representation into the planning of attentional glimpses.
Predicting Goal-directed Attention Control Using Inverse-Reinforcement Learning
Jan 31, 2020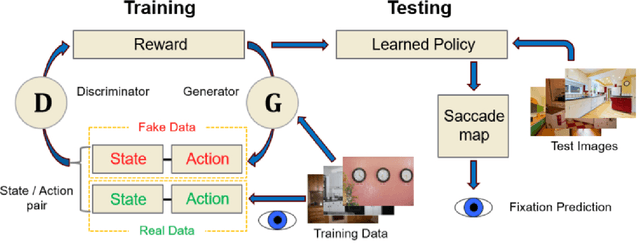



Understanding how goal states control behavior is a question ripe for interrogation by new methods from machine learning. These methods require large and labeled datasets to train models. To annotate a large-scale image dataset with observed search fixations, we collected 16,184 fixations from people searching for either microwaves or clocks in a dataset of 4,366 images (MS-COCO). We then used this behaviorally-annotated dataset and the machine learning method of Inverse-Reinforcement Learning (IRL) to learn target-specific reward functions and policies for these two target goals. Finally, we used these learned policies to predict the fixations of 60 new behavioral searchers (clock = 30, microwave = 30) in a disjoint test dataset of kitchen scenes depicting both a microwave and a clock (thus controlling for differences in low-level image contrast). We found that the IRL model predicted behavioral search efficiency and fixation-density maps using multiple metrics. Moreover, reward maps from the IRL model revealed target-specific patterns that suggest, not just attention guidance by target features, but also guidance by scene context (e.g., fixations along walls in the search of clocks). Using machine learning and the psychologically-meaningful principle of reward, it is possible to learn the visual features used in goal-directed attention control.
Learning to attend in a brain-inspired deep neural network
Nov 23, 2018
Recent machine learning models have shown that including attention as a component results in improved model accuracy and interpretability, despite the concept of attention in these approaches only loosely approximating the brain's attention mechanism. Here we extend this work by building a more brain-inspired deep network model of the primate ATTention Network (ATTNet) that learns to shift its attention so as to maximize the reward. Using deep reinforcement learning, ATTNet learned to shift its attention to the visual features of a target category in the context of a search task. ATTNet's dorsal layers also learned to prioritize these shifts of attention so as to maximize success of the ventral pathway classification and receive greater reward. Model behavior was tested against the fixations made by subjects searching images for the same cued category. Both subjects and ATTNet showed evidence for attention being preferentially directed to target goals, behaviorally measured as oculomotor guidance to targets. More fundamentally, ATTNet learned to shift its attention to target like objects and spatially route its visual inputs to accomplish the task. This work makes a step toward a better understanding of the role of attention in the brain and other computational systems.