 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
HOPE-Net: A Graph-based Model for Hand-Object Pose Estimation
Mar 31, 2020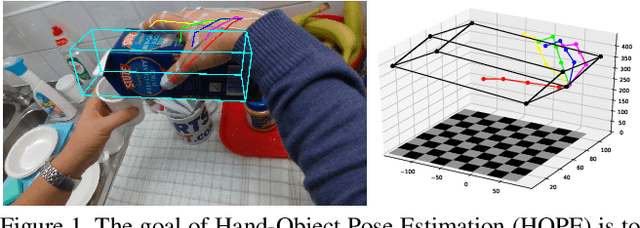



Hand-object pose estimation (HOPE) aims to jointly detect the poses of both a hand and of a held object. In this paper, we propose a lightweight model called HOPE-Net which jointly estimates hand and object pose in 2D and 3D in real-time. Our network uses a cascade of two adaptive graph convolutional neural networks, one to estimate 2D coordinates of the hand joints and object corners, followed by another to convert 2D coordinates to 3D. Our experiments show that through end-to-end training of the full network, we achieve better accuracy for both the 2D and 3D coordinate estimation problems. The proposed 2D to 3D graph convolution-based model could be applied to other 3D landmark detection problems, where it is possible to first predict the 2D keypoints and then transform them to 3D.
Gated Feedback Refinement Network for Coarse-to-Fine Dense Semantic Image Labeling
Jun 29, 2018



Effective integration of local and global contextual information is crucial for semantic segmentation and dense image labeling. We develop two encoder-decoder based deep learning architectures to address this problem. We first propose a network architecture called Label Refinement Network (LRN) that predicts segmentation labels in a coarse-to-fine fashion at several spatial resolutions. In this network, we also define loss functions at several stages to provide supervision at different stages of training. However, there are limits to the quality of refinement possible if ambiguous information is passed forward. In order to address this issue, we also propose Gated Feedback Refinement Network (G-FRNet) that addresses this limitation. Initially, G-FRNet makes a coarse-grained prediction which it progressively refines to recover details by effectively integrating local and global contextual information during the refinement stages. This is achieved by gate units proposed in this work, that control information passed forward in order to resolve the ambiguity. Experiments were conducted on four challenging dense labeling datasets (CamVid, PASCAL VOC 2012, Horse-Cow Parsing, PASCAL-Person-Part, and SUN-RGBD). G-FRNet achieves state-of-the-art semantic segmentation results on the CamVid and Horse-Cow Parsing datasets and produces results competitive with the best performing approaches that appear in the literature for the other three datasets.
Label Refinement Network for Coarse-to-Fine Semantic Segmentation
Mar 01, 2017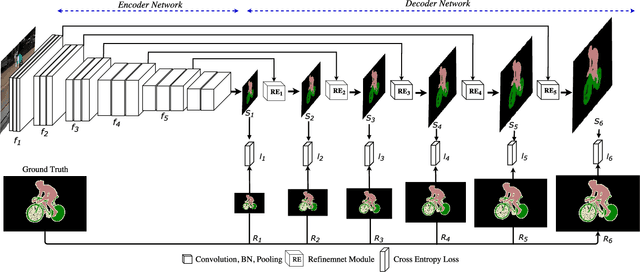


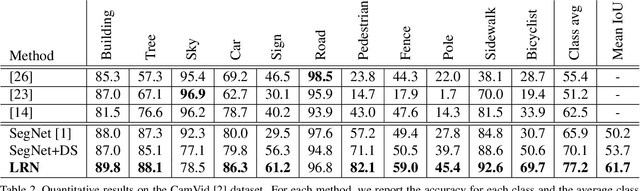
We consider the problem of semantic image segmentation using deep convolutional neural networks. We propose a novel network architecture called the label refinement network that predicts segmentation labels in a coarse-to-fine fashion at several resolutions. The segmentation labels at a coarse resolution are used together with convolutional features to obtain finer resolution segmentation labels. We define loss functions at several stages in the network to provide supervisions at different stages. Our experimental results on several standard datasets demonstrate that the proposed model provides an effective way of producing pixel-wise dense image labeling.