 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-SL: Contrastive Sound Localization with Inertial-Acoustic Sensors
Jun 09, 2020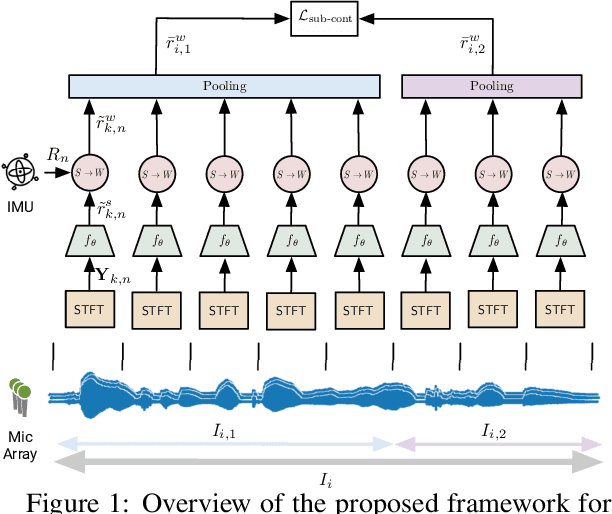
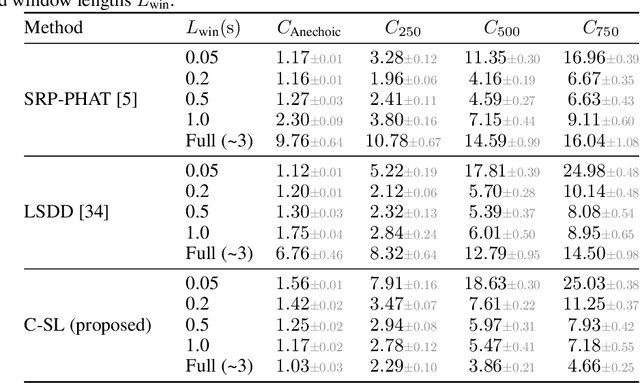
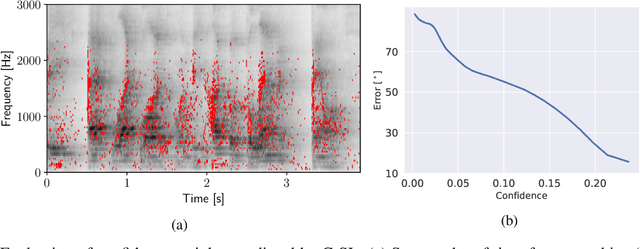

Human brain employs perceptual information about the head and eye movements to update the spatial relationship between the individual and the surrounding environment. Based on this cognitive process known as spatial updating, we introduce contrastive sound localization (C-SL) with mobile inertial-acoustic sensor arrays of arbitrary geometry. C-SL uses unlabeled multi-channel audio recordings and inertial measurement unit (IMU) readings collected during free rotational movements of the array to learn mappings from acoustical measurements to an array-centered direction-of-arrival (DOA) in a self-supervised manner. Contrary to conventional DOA estimation methods that require the knowledge of either the array geometry or source locations in the calibration stage, C-SL is agnostic to both, and can be trained on data collected in minimally constrained settings. To achieve this capability, our proposed method utilizes a customized contrastive loss measuring the spatial contrast between source locations predicted for disjoint segments of the input to jointly update estimated DOAs and the acoustic-spatial mapping in linear time. We provide quantitative and qualitative evaluations of C-SL comparing its performance with baseline DOA estimation methods in a wide range of conditions. We believe the relaxed calibration process offered by C-SL paves the way toward truly personalized augmented hearing applications.
HOPE-Net: A Graph-based Model for Hand-Object Pose Estimation
Mar 31, 2020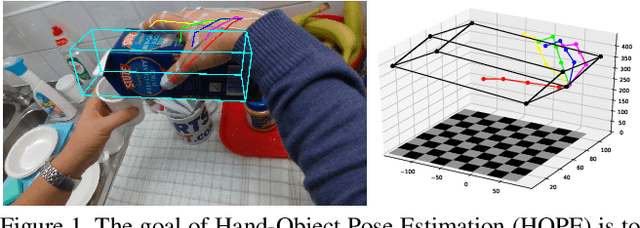



Hand-object pose estimation (HOPE) aims to jointly detect the poses of both a hand and of a held object. In this paper, we propose a lightweight model called HOPE-Net which jointly estimates hand and object pose in 2D and 3D in real-time. Our network uses a cascade of two adaptive graph convolutional neural networks, one to estimate 2D coordinates of the hand joints and object corners, followed by another to convert 2D coordinates to 3D. Our experiments show that through end-to-end training of the full network, we achieve better accuracy for both the 2D and 3D coordinate estimation problems. The proposed 2D to 3D graph convolution-based model could be applied to other 3D landmark detection problems, where it is possible to first predict the 2D keypoints and then transform them to 3D.