 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACS: Mass Conditioned 3D Hand and Object Motion Synthesis
Dec 22, 2023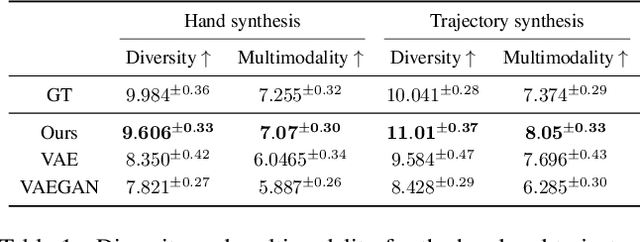
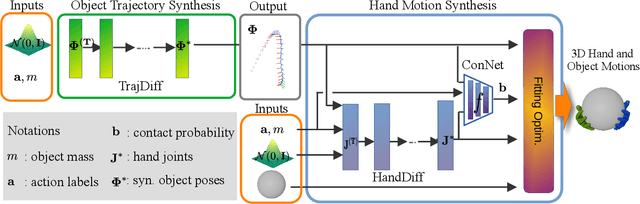
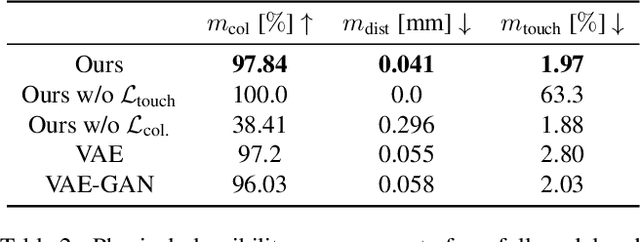

The physical properties of an object, such as mass, significantly affect how we manipulate it with our hands. Surprisingly, this aspect has so far been neglected in prior work on 3D motion synthesis. To improve the naturalness of the synthesized 3D hand object motions, this work proposes MACS the first MAss Conditioned 3D hand and object motion Synthesis approach. Our approach is based on cascaded diffusion models and generates interactions that plausibly adjust based on the object mass and interaction type. MACS also accepts a manually drawn 3D object trajectory as input and synthesizes the natural 3D hand motions conditioned by the object mass. This flexibility enables MACS to be used for various downstream applications, such as generating synthetic training data for ML tasks, fast animation of hands for graphics workflows, and generating character interactions for computer games. We show experimentally that a small-scale dataset is sufficient for MACS to reasonably generalize across interpolated and extrapolated object masses unseen during the training. Furthermore, MACS shows moderate generalization to unseen objects, thanks to the mass-conditioned contact labels generated by our surface contact synthesis model ConNet. Our comprehensive user study confirms that the synthesized 3D hand-object interactions are highly plausible and realistic.
Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images
Aug 21, 2023We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications.
Boosting Image-based Mutual Gaze Detection using Pseudo 3D Gaze
Oct 15, 2020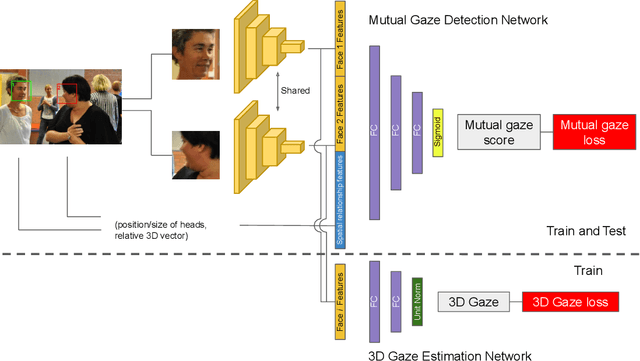


Mutual gaze detection, i.e., predicting whether or not two people are looking at each other, plays an important role in understanding human interactions. In this work, we focus on the task of image-based mutual gaze detection, and propose a simple and effective approach to boost the performance by using an auxiliary 3D gaze estimation task during training. We achieve the performance boost without additional labeling cost by training the 3D gaze estimation branch using pseudo 3D gaze labels deduced from mutual gaze labels. By sharing the head image encoder between the 3D gaze estimation and the mutual gaze detection branches, we achieve better head features than learned by training the mutual gaze detection branch alone. Experimental results on three image datasets show that the proposed approach improves the detection performance significantly without additional annotations. This work also introduces a new image dataset that consists of 33.1K pairs of humans annotated with mutual gaze labels in 29.2K images.
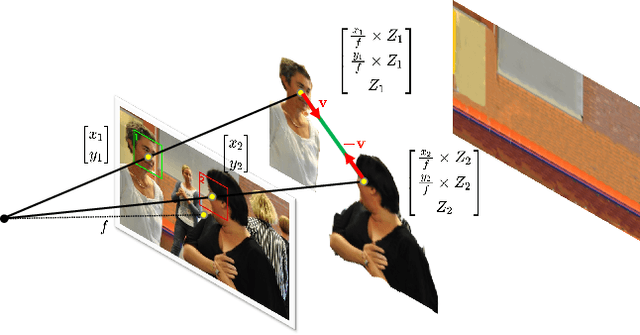
C-SL: Contrastive Sound Localization with Inertial-Acoustic Sensors
Jun 09, 2020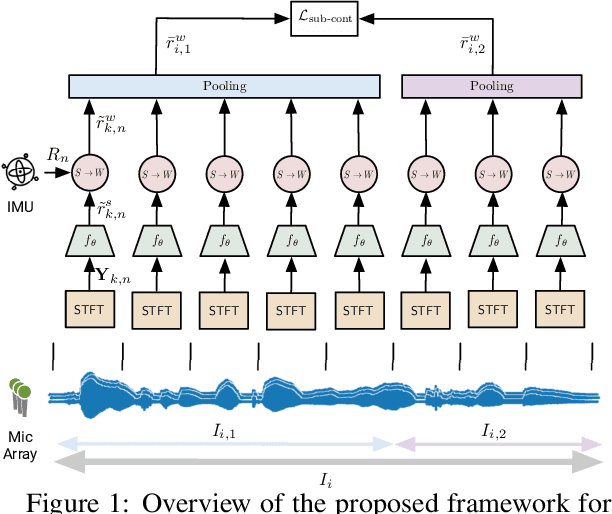
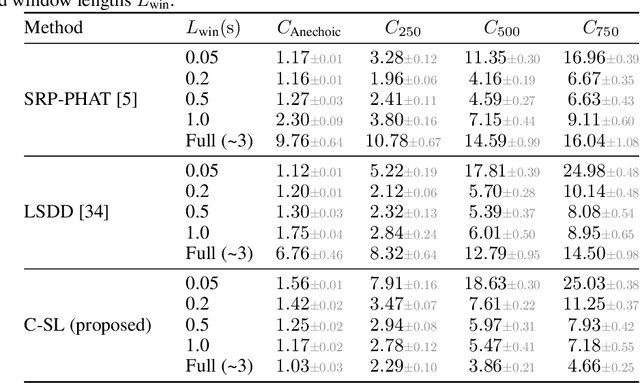
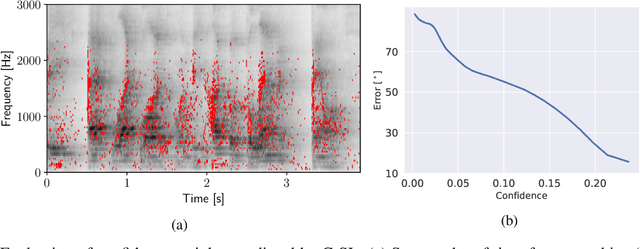

Human brain employs perceptual information about the head and eye movements to update the spatial relationship between the individual and the surrounding environment. Based on this cognitive process known as spatial updating, we introduce contrastive sound localization (C-SL) with mobile inertial-acoustic sensor arrays of arbitrary geometry. C-SL uses unlabeled multi-channel audio recordings and inertial measurement unit (IMU) readings collected during free rotational movements of the array to learn mappings from acoustical measurements to an array-centered direction-of-arrival (DOA) in a self-supervised manner. Contrary to conventional DOA estimation methods that require the knowledge of either the array geometry or source locations in the calibration stage, C-SL is agnostic to both, and can be trained on data collected in minimally constrained settings. To achieve this capability, our proposed method utilizes a customized contrastive loss measuring the spatial contrast between source locations predicted for disjoint segments of the input to jointly update estimated DOAs and the acoustic-spatial mapping in linear time. We provide quantitative and qualitative evaluations of C-SL comparing its performance with baseline DOA estimation methods in a wide range of conditions. We believe the relaxed calibration process offered by C-SL paves the way toward truly personalized augmented hearing applications.
HOPE-Net: A Graph-based Model for Hand-Object Pose Estimation
Mar 31, 2020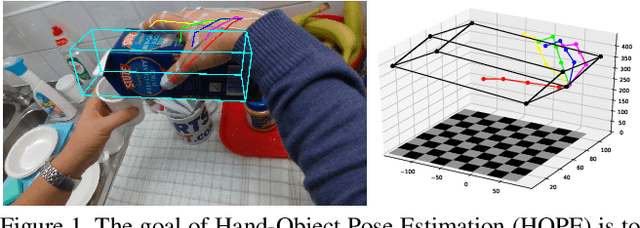



Hand-object pose estimation (HOPE) aims to jointly detect the poses of both a hand and of a held object. In this paper, we propose a lightweight model called HOPE-Net which jointly estimates hand and object pose in 2D and 3D in real-time. Our network uses a cascade of two adaptive graph convolutional neural networks, one to estimate 2D coordinates of the hand joints and object corners, followed by another to convert 2D coordinates to 3D. Our experiments show that through end-to-end training of the full network, we achieve better accuracy for both the 2D and 3D coordinate estimation problems. The proposed 2D to 3D graph convolution-based model could be applied to other 3D landmark detection problems, where it is possible to first predict the 2D keypoints and then transform them to 3D.
Hand Pose Estimation: A Survey
Mar 03, 2019
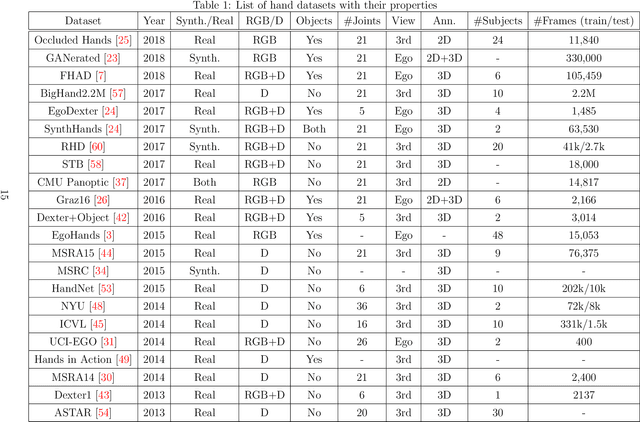

The success of Deep Convolutional Neural Networks (CNNs) in recent years in almost all the Computer Vision tasks on one hand, and the popularity of low-cost consumer depth cameras on the other, has made Hand Pose Estimation a hot topic in computer vision field. In this report, we will first explain the hand pose estimation problem and will review major approaches solving this problem, especially the two different problems of using depth maps or RGB images. We will survey the most important papers in each field and will discuss the strengths and weaknesses of each. Finally, we will explain the biggest datasets in this field in detail and list 21 datasets with all their properties. To the best of our knowledge this is the most complete list of all the datasets in the hand pose estimation field.
A Computational Method for Evaluating UI Patterns
Jul 11, 2018
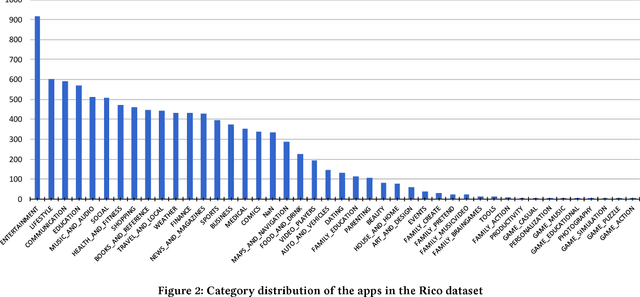


UI design languages, such as Google's Material Design, make applications both easier to develop and easier to learn by providing a set of standard UI components. Nonetheless, it is hard to assess the impact of design languages in the wild. Moreover, designers often get stranded by strong-opinionated debates around the merit of certain UI components, such as the Floating Action Button and the Navigation Drawer. To address these challenges, this short paper introduces a method for measuring the impact of design languages and informing design debates through analyzing a dataset consisting of view hierarchies, screenshots, and app metadata for more than 9,000 mobile apps. Our data analysis shows that use of Material Design is positively correlated to app ratings, and to some extent, also the number of installs. Furthermore, we show that use of UI components vary by app category, suggesting a more nuanced view needed in design debates.