 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Image-based Mutual Gaze Detection using Pseudo 3D Gaze
Oct 15, 2020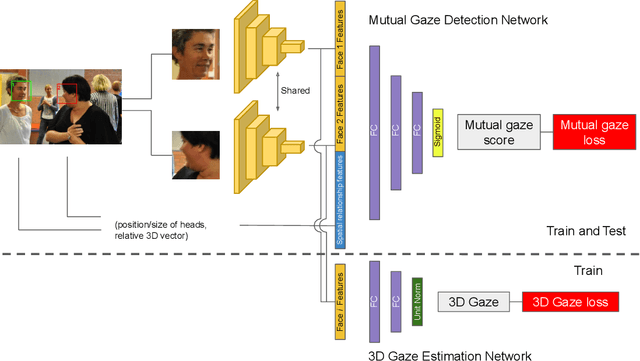
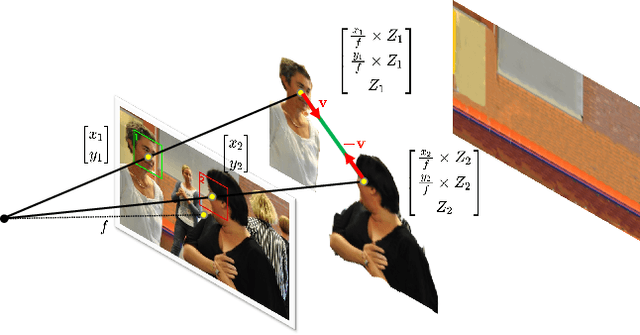


Mutual gaze detection, i.e., predicting whether or not two people are looking at each other, plays an important role in understanding human interactions. In this work, we focus on the task of image-based mutual gaze detection, and propose a simple and effective approach to boost the performance by using an auxiliary 3D gaze estimation task during training. We achieve the performance boost without additional labeling cost by training the 3D gaze estimation branch using pseudo 3D gaze labels deduced from mutual gaze labels. By sharing the head image encoder between the 3D gaze estimation and the mutual gaze detection branches, we achieve better head features than learned by training the mutual gaze detection branch alone. Experimental results on three image datasets show that the proposed approach improves the detection performance significantly without additional annotations. This work also introduces a new image dataset that consists of 33.1K pairs of humans annotated with mutual gaze labels in 29.2K images.
Global Self-Attention Networks for Image Recognition
Oct 14, 2020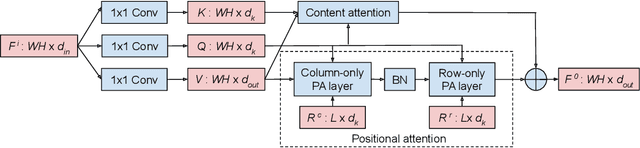
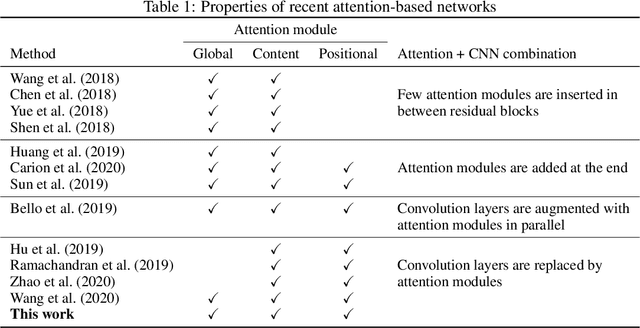
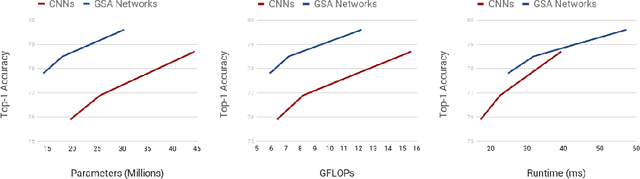

Recently, a series of works in computer vision have shown promising results on various image and video understanding tasks using self-attention. However, due to the quadratic computational and memory complexities of self-attention, these works either apply attention only to low-resolution feature maps in later stages of a deep network or restrict the receptive field of attention in each layer to a small local region. To overcome these limitations, this work introduces a new global self-attention module, referred to as the GSA module, which is efficient enough to serve as the backbone component of a deep network. This module consists of two parallel layers: a content attention layer that attends to pixels based only on their content and a positional attention layer that attends to pixels based on their spatial locations. The output of this module is the sum of the outputs of the two layers. Based on the proposed GSA module, we introduce new standalone global attention-based deep networks that use GSA modules instead of convolutions to model pixel interactions. Due to the global extent of the proposed GSA module, a GSA network has the ability to model long-range pixel interactions throughout the network. Our experimental results show that GSA networks outperform the corresponding convolution-based networks significantly on the CIFAR-100 and ImageNet datasets while using less parameters and computations. The proposed GSA networks also outperform various existing attention-based networks on the ImageNet dataset.
An Automatic System for Unconstrained Video-Based Face Recognition
Dec 10, 2018

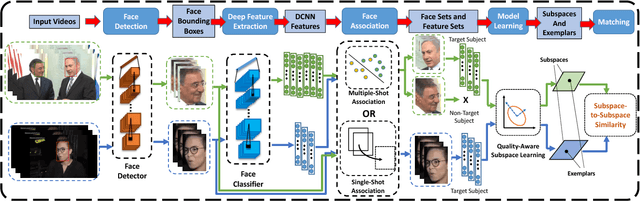

Although deep learning approaches have achieved performance surpassing humans for still image-based face recognition, unconstrained video-based face recognition is still a challenging task due to large volume of data to be processed and intra/inter-video variations on pose, illumination, occlusion, scene, blur, video quality, etc. In this work, we consider challenging scenarios for unconstrained video-based face recognition from multiple-shot videos and surveillance videos with low-quality frames. To handle these problems, we propose a robust and efficient system for unconstrained video-based face recognition, which is composed of face/fiducial detection, face association, and face recognition. First, we use multi-scale single-shot face detectors to efficiently localize faces in videos. The detected faces are then grouped respectively through carefully designed face association methods, especially for multi-shot videos. Finally, the faces are recognized by the proposed face matcher based on an unsupervised subspace learning approach and a subspace-to-subspace similarity metric. Extensive experiments on challenging video datasets, such as Multiple Biometric Grand Challenge (MBGC), Face and Ocular Challenge Series (FOCS), JANUS Challenge Set 6 (CS6) for low-quality surveillance videos and IARPA JANUS Benchmark B (IJB-B) for multiple-shot videos, demonstrate that the proposed system can accurately detect and associate faces from unconstrained videos and effectively learn robust and discriminative features for recognition.
Unconstrained Still/Video-Based Face Verification with Deep Convolutional Neural Networks
Jul 18, 2017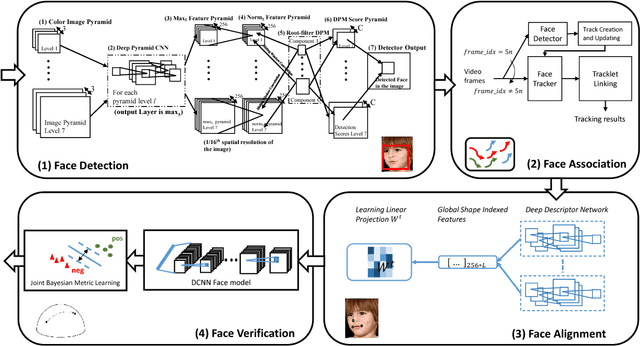
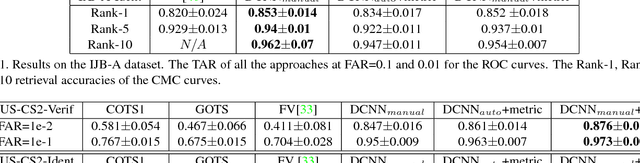


Over the last five years, methods based on Deep Convolutional Neural Networks (DCNNs) have shown impressive performance improvements for object detection and recognition problems. This has been made possible due to the availability of large annotated datasets, a better understanding of the non-linear mapping between input images and class labels as well as the affordability of GPUs. In this paper, we present the design details of a deep learning system for unconstrained face recognition, including modules for face detection, association, alignment and face verification. The quantitative performance evaluation is conducted using the IARPA Janus Benchmark A (IJB-A), the JANUS Challenge Set 2 (JANUS CS2), and the LFW dataset. The IJB-A dataset includes real-world unconstrained faces of 500 subjects with significant pose and illumination variations which are much harder than the Labeled Faces in the Wild (LFW) and Youtube Face (YTF) datasets. JANUS CS2 is the extended version of IJB-A which contains not only all the images/frames of IJB-A but also includes the original videos for evaluating the video-based face verification system. Some open issues regarding DCNNs for face verification problems are then discussed.
Learning from Ambiguously Labeled Face Images
Jul 01, 2017
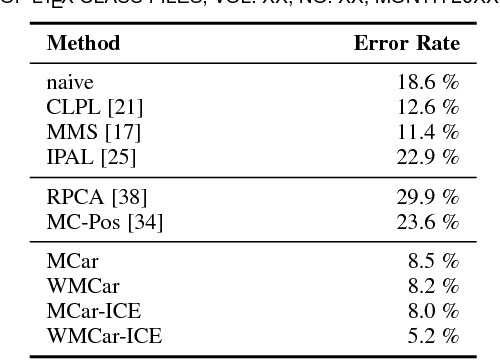
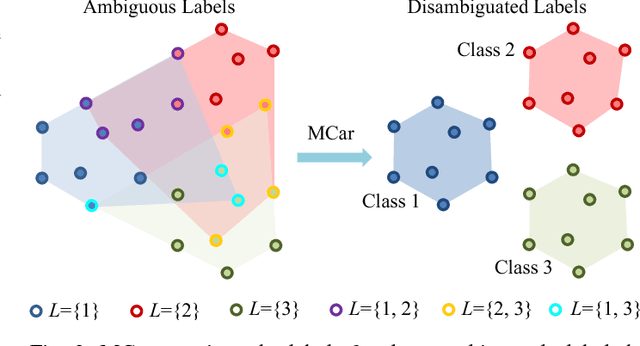
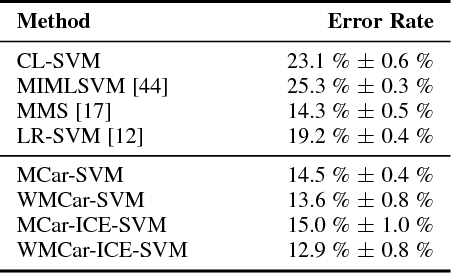
Learning a classifier from ambiguously labeled face images is challenging since training images are not always explicitly-labeled. For instance, face images of two persons in a news photo are not explicitly labeled by their names in the caption. We propose a Matrix Completion for Ambiguity Resolution (MCar) method for predicting the actual labels from ambiguously labeled images. This step is followed by learning a standard supervised classifier from the disambiguated labels to classify new images. To prevent the majority labels from dominating the result of MCar, we generalize MCar to a weighted MCar (WMCar) that handles label imbalance. Since WMCar outputs a soft labeling vector of reduced ambiguity for each instance, we can iteratively refine it by feeding it as the input to WMCar. Nevertheless, such an iterative implementation can be affected by the noisy soft labeling vectors, and thus the performance may degrade. Our proposed Iterative Candidate Elimination (ICE) procedure makes the iterative ambiguity resolution possible by gradually eliminating a portion of least likely candidates in ambiguously labeled face. We further extend MCar to incorporate the labeling constraints between instances when such prior knowledge is available. Compared to existing methods, our approach demonstrates improvement on several ambiguously labeled datasets.
Domain-invariant Face Recognition using Learned Low-rank Transformation
Aug 01, 2013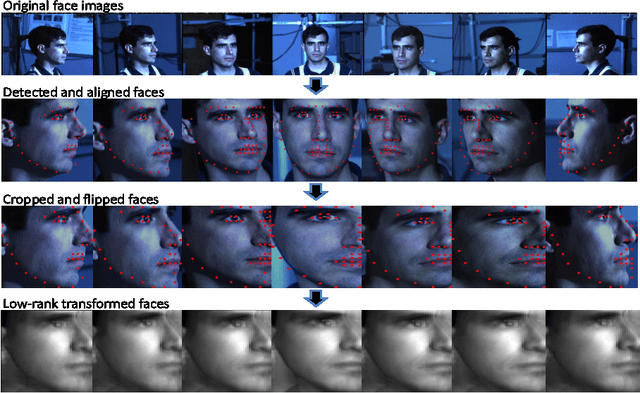
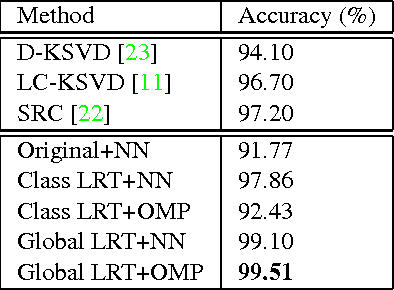

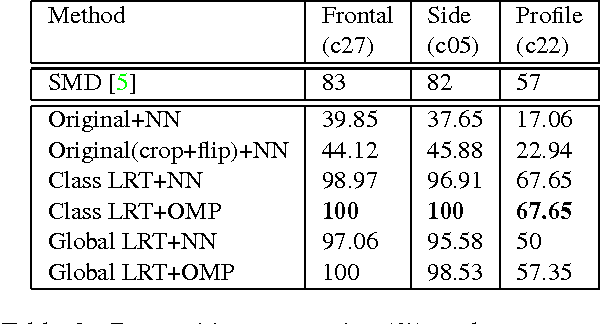
We present a low-rank transformation approach to compensate for face variations due to changes in visual domains, such as pose and illumination. The key idea is to learn discriminative linear transformations for face images using matrix rank as the optimization criteria. The learned linear transformations restore a shared low-rank structure for faces from the same subject, and, at the same time, force a high-rank structure for faces from different subjects. In this way, among the transformed faces, we reduce variations caused by domain changes within the classes, and increase separations between the classes for better face recognition across domains. Extensive experiments using public datasets are presented to demonstrate the effectiveness of our approach for face recognition across domains. The potential of the approach for feature extraction in generic object recognition and coded aperture design are discussed as well.