 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Open-Vocabulary Object Detection with Vision Transformers
May 12, 2022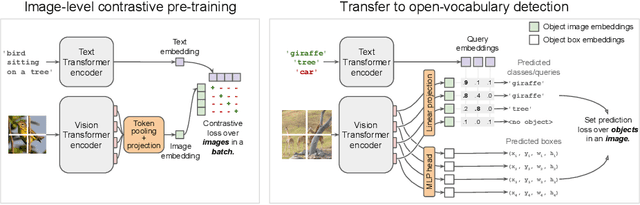
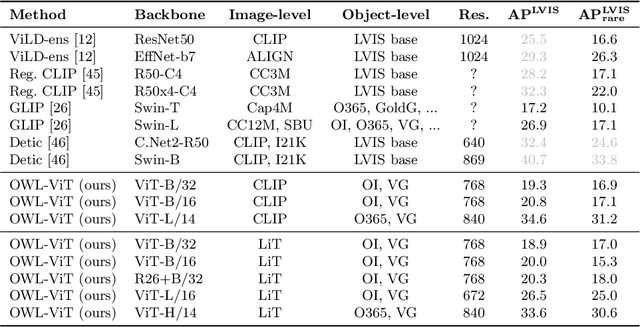
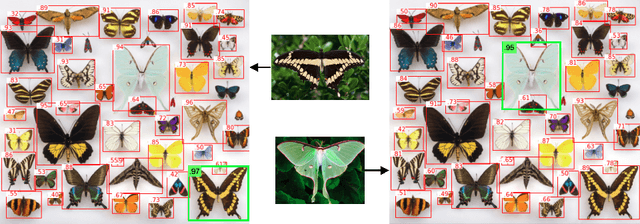
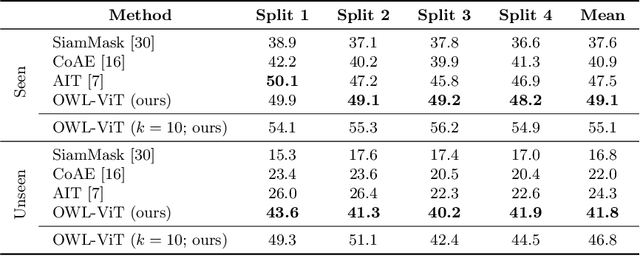
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.
Global Self-Attention Networks for Image Recognition
Oct 14, 2020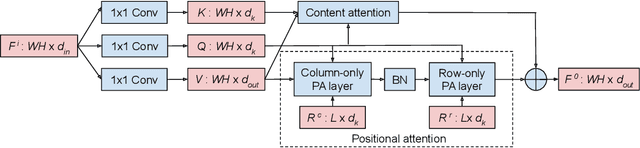
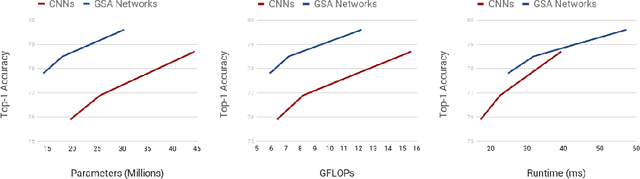

Recently, a series of works in computer vision have shown promising results on various image and video understanding tasks using self-attention. However, due to the quadratic computational and memory complexities of self-attention, these works either apply attention only to low-resolution feature maps in later stages of a deep network or restrict the receptive field of attention in each layer to a small local region. To overcome these limitations, this work introduces a new global self-attention module, referred to as the GSA module, which is efficient enough to serve as the backbone component of a deep network. This module consists of two parallel layers: a content attention layer that attends to pixels based only on their content and a positional attention layer that attends to pixels based on their spatial locations. The output of this module is the sum of the outputs of the two layers. Based on the proposed GSA module, we introduce new standalone global attention-based deep networks that use GSA modules instead of convolutions to model pixel interactions. Due to the global extent of the proposed GSA module, a GSA network has the ability to model long-range pixel interactions throughout the network. Our experimental results show that GSA networks outperform the corresponding convolution-based networks significantly on the CIFAR-100 and ImageNet datasets while using less parameters and computations. The proposed GSA networks also outperform various existing attention-based networks on the ImageNet dataset.
Fast Video Object Segmentation using the Global Context Module
Jan 30, 2020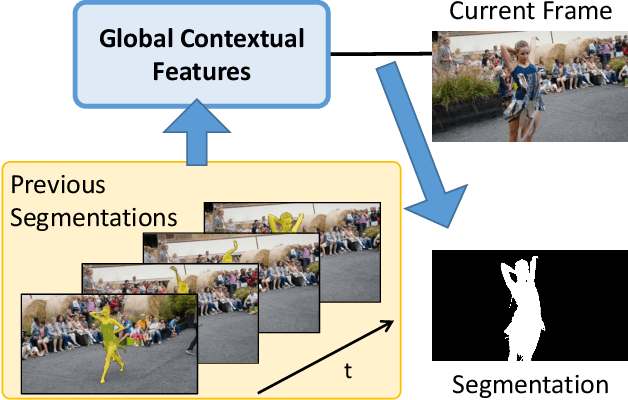
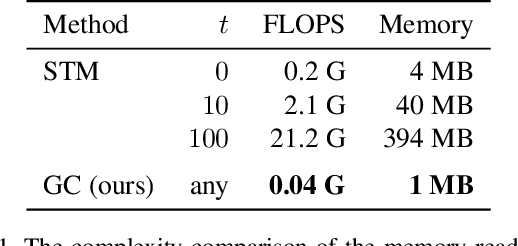
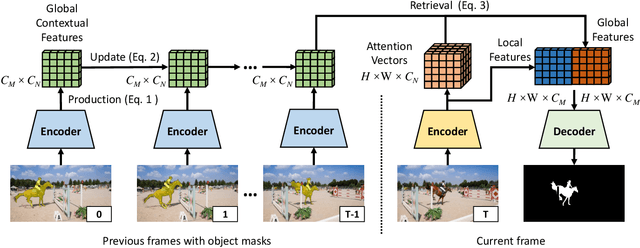

We developed a real-time, high-quality video object segmentation algorithm for semi-supervised video segmentation. Its performance is on par with the most accurate, time-consuming online-learning model, while its speed is similar to the fastest template-matching method which has sub-optimal accuracy. The core in achieving this is a novel global context module that reliably summarizes and propagates information through the entire video. Compared to previous approaches that only use the first, the last, or a select few frames to guide the segmentation of the current frame, the global context module allows us to use all past frames to guide the processing. Unlike the state-of-the-art space-time memory network that caches a memory at each spatiotemporal position, our global context module is a fixed-size representation that does not use more memory as more frames are processed. It is straightforward in implementation and has lower memory and computational costs than the space-time memory module. Equipped with the global context module, our method achieved top accuracy on DAVIS 2016 and near-state-of-the-art results on DAVIS 2017 at a real-time speed.
Factorized Attention: Self-Attention with Linear Complexities
Dec 04, 2018


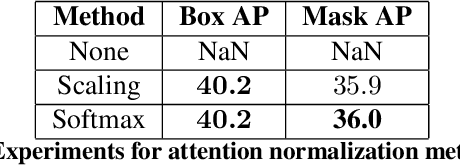
Recent works have been applying self-attention to various fields in computer vision and natural language processing. However, the memory and computational demands of existing self-attention operations grow quadratically with the spatiotemporal size of the input. This prohibits the application of self-attention on large inputs, e.g., long sequences, high-definition images, or large videos. To remedy this, this paper proposes a novel factorized attention (FA) module, which achieves the same expressive power as previous approaches with substantially less memory and computational consumption. The resource-efficiency allows more widespread and flexible application of it. Empirical evaluations on object recognition demonstrate the effectiveness of these advantages. FA-augmented models achieved state-of-the-art performance for object detection and instance segmentation on MS-COCO. Further, the resource-efficiency of FA democratizes self-attention to fields where the prohibitively high costs currently prevent its application. The state-of-the-art result for stereo depth estimation on the Scene Flow dataset exemplifies this.