 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Attention: Self-Attention with Linear Complexities
Paper and Code



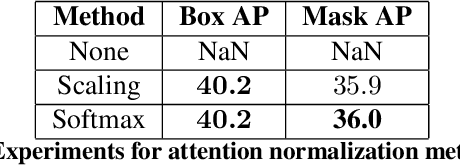
Recent works have been applying self-attention to various fields in computer vision and natural language processing. However, the memory and computational demands of existing self-attention operations grow quadratically with the spatiotemporal size of the input. This prohibits the application of self-attention on large inputs, e.g., long sequences, high-definition images, or large videos. To remedy this, this paper proposes a novel factorized attention (FA) module, which achieves the same expressive power as previous approaches with substantially less memory and computational consumption. The resource-efficiency allows more widespread and flexible application of it. Empirical evaluations on object recognition demonstrate the effectiveness of these advantages. FA-augmented models achieved state-of-the-art performance for object detection and instance segmentation on MS-COCO. Further, the resource-efficiency of FA democratizes self-attention to fields where the prohibitively high costs currently prevent its application. The state-of-the-art result for stereo depth estimation on the Scene Flow dataset exemplifies this.