 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Combating Data Imbalances in Federated Semi-supervised Learning with Dual Regulators
Jul 16, 2023



Federated learning has become a popular method to learn from decentralized heterogeneous data. Federated semi-supervised learning (FSSL) emerges to train models from a small fraction of labeled data due to label scarcity on decentralized clients. Existing FSSL methods assume independent and identically distributed (IID) labeled data across clients and consistent class distribution between labeled and unlabeled data within a client. This work studies a more practical and challenging scenario of FSSL, where data distribution is different not only across clients but also within a client between labeled and unlabeled data. To address this challenge, we propose a novel FSSL framework with dual regulators, FedDure.} FedDure lifts the previous assumption with a coarse-grained regulator (C-reg) and a fine-grained regulator (F-reg): C-reg regularizes the updating of the local model by tracking the learning effect on labeled data distribution; F-reg learns an adaptive weighting scheme tailored for unlabeled instances in each client. We further formulate the client model training as bi-level optimization that adaptively optimizes the model in the client with two regulators. Theoretically, we show the convergence guarantee of the dual regulators. Empirically, we demonstrate that FedDure is superior to the existing methods across a wide range of settings, notably by more than 11% on CIFAR-10 and CINIC-10 datasets.
Variational Relational Point Completion Network for Robust 3D Classification
Apr 18, 2023Real-scanned point clouds are often incomplete due to viewpoint, occlusion, and noise, which hampers 3D geometric modeling and perception. Existing point cloud completion methods tend to generate global shape skeletons and hence lack fine local details. Furthermore, they mostly learn a deterministic partial-to-complete mapping, but overlook structural relations in man-made objects. To tackle these challenges, this paper proposes a variational framework, Variational Relational point Completion Network (VRCNet) with two appealing properties: 1) Probabilistic Modeling. In particular, we propose a dual-path architecture to enable principled probabilistic modeling across partial and complete clouds. One path consumes complete point clouds for reconstruction by learning a point VAE. The other path generates complete shapes for partial point clouds, whose embedded distribution is guided by distribution obtained from the reconstruction path during training. 2) Relational Enhancement. Specifically, we carefully design point self-attention kernel and point selective kernel module to exploit relational point features, which refines local shape details conditioned on the coarse completion. In addition, we contribute multi-view partial point cloud datasets (MVP and MVP-40 dataset) containing over 200,000 high-quality scans, which render partial 3D shapes from 26 uniformly distributed camera poses for each 3D CAD model. Extensive experiments demonstrate that VRCNet outperforms state-of-the-art methods on all standard point cloud completion benchmarks. Notably, VRCNet shows great generalizability and robustness on real-world point cloud scans. Moreover, we can achieve robust 3D classification for partial point clouds with the help of VRCNet, which can highly increase classification accuracy.
An Empirical Study of Pseudo-Labeling for Image-based 3D Object Detection
Aug 15, 2022


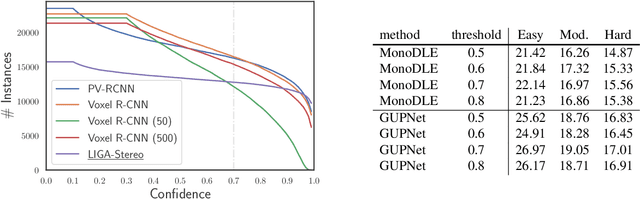
Image-based 3D detection is an indispensable component of the perception system for autonomous driving. However, it still suffers from the unsatisfying performance, one of the main reasons for which is the limited training data. Unfortunately, annotating the objects in the 3D space is extremely time/resource-consuming, which makes it hard to extend the training set arbitrarily. In this work, we focus on the semi-supervised manner and explore the feasibility of a cheaper alternative, i.e. pseudo-labeling, to leverage the unlabeled data. For this purpose, we conduct extensive experiments to investigate whether the pseudo-labels can provide effective supervision for the baseline models under varying settings. The experimental results not only demonstrate the effectiveness of the pseudo-labeling mechanism for image-based 3D detection (e.g. under monocular setting, we achieve 20.23 AP for moderate level on the KITTI-3D testing set without bells and whistles, improving the baseline model by 6.03 AP), but also show several interesting and noteworthy findings (e.g. the models trained with pseudo-labels perform better than that trained with ground-truth annotations based on the same training data). We hope this work can provide insights for the image-based 3D detection community under a semi-supervised setting. The codes, pseudo-labels, and pre-trained models will be publicly available.
StyleFlow For Content-Fixed Image to Image Translation
Jul 05, 2022

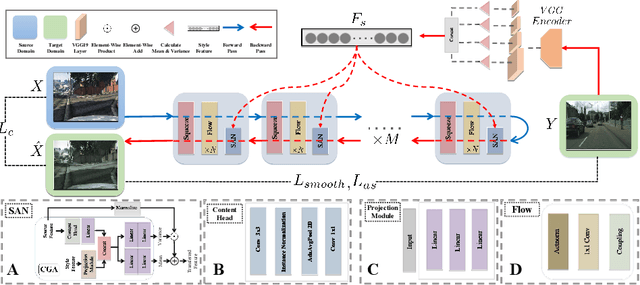

Image-to-image (I2I) translation is a challenging topic in computer vision. We divide this problem into three tasks: strongly constrained translation, normally constrained translation, and weakly constrained translation. The constraint here indicates the extent to which the content or semantic information in the original image is preserved. Although previous approaches have achieved good performance in weakly constrained tasks, they failed to fully preserve the content in both strongly and normally constrained tasks, including photo-realism synthesis, style transfer, and colorization, etc. To achieve content-preserving transfer in strongly constrained and normally constrained tasks, we propose StyleFlow, a new I2I translation model that consists of normalizing flows and a novel Style-Aware Normalization (SAN) module. With the invertible network structure, StyleFlow first projects input images into deep feature space in the forward pass, while the backward pass utilizes the SAN module to perform content-fixed feature transformation and then projects back to image space. Our model supports both image-guided translation and multi-modal synthesis. We evaluate our model in several I2I translation benchmarks, and the results show that the proposed model has advantages over previous methods in both strongly constrained and normally constrained tasks.
Probing Visual-Audio Representation for Video Highlight Detection via Hard-Pairs Guided Contrastive Learning
Jun 21, 2022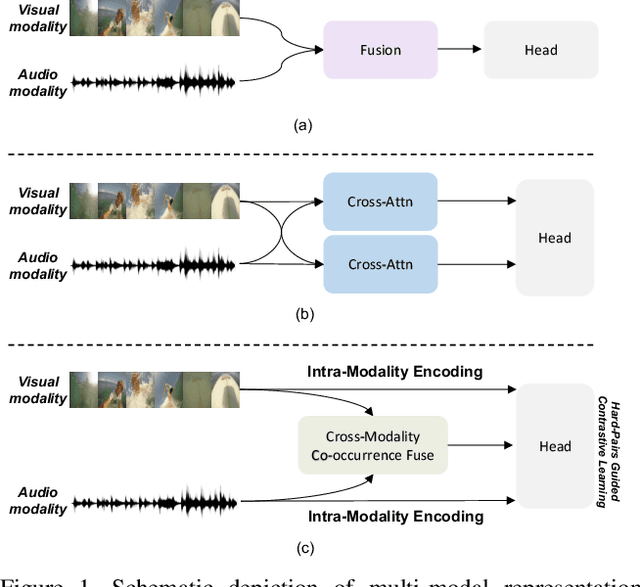

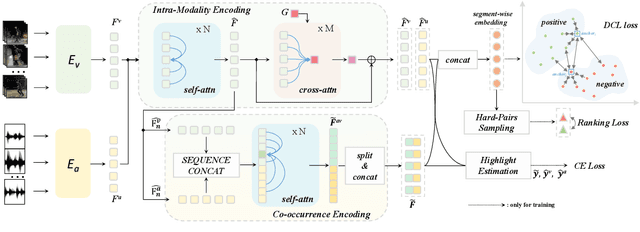
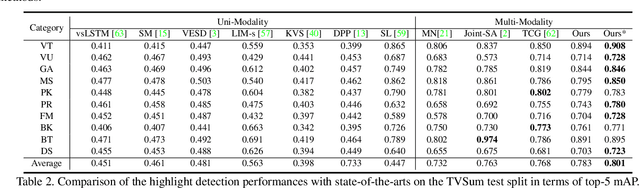
Video highlight detection is a crucial yet challenging problem that aims to identify the interesting moments in untrimmed videos. The key to this task lies in effective video representations that jointly pursue two goals, \textit{i.e.}, cross-modal representation learning and fine-grained feature discrimination. In this paper, these two challenges are tackled by not only enriching intra-modality and cross-modality relations for representation modeling but also shaping the features in a discriminative manner. Our proposed method mainly leverages the intra-modality encoding and cross-modality co-occurrence encoding for fully representation modeling. Specifically, intra-modality encoding augments the modality-wise features and dampens irrelevant modality via within-modality relation learning in both audio and visual signals. Meanwhile, cross-modality co-occurrence encoding focuses on the co-occurrence inter-modality relations and selectively captures effective information among multi-modality. The multi-modal representation is further enhanced by the global information abstracted from the local context. In addition, we enlarge the discriminative power of feature embedding with a hard-pairs guided contrastive learning (HPCL) scheme. A hard-pairs sampling strategy is further employed to mine the hard samples for improving feature discrimination in HPCL. Extensive experiments conducted on two benchmarks demonstrate the effectiveness and superiority of our proposed methods compared to other state-of-the-art methods.
Better Teacher Better Student: Dynamic Prior Knowledge for Knowledge Distillation
Jun 14, 2022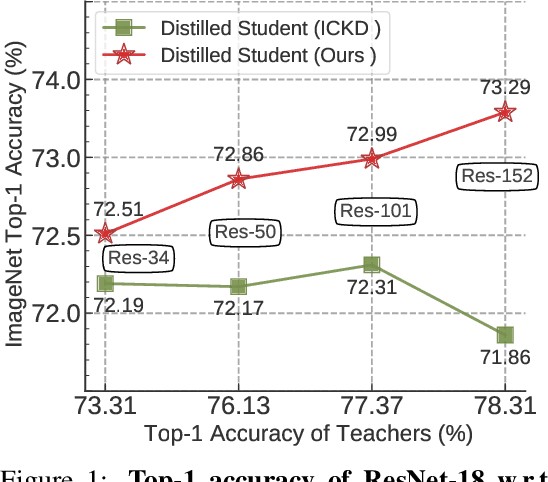
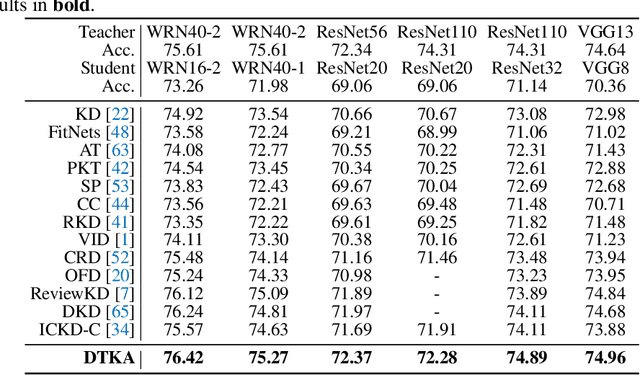
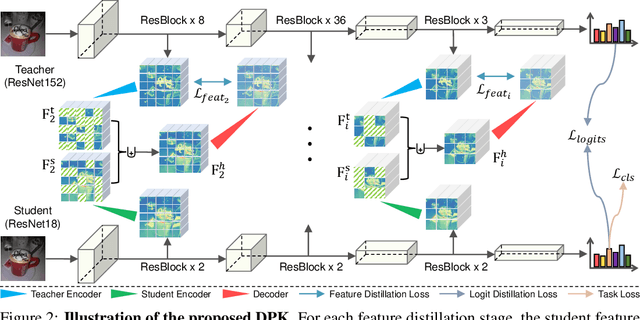

Knowledge distillation (KD) has shown very promising capabilities in transferring learning representations from large models (teachers) to small models (students). However, as the capacity gap between students and teachers becomes larger, existing KD methods fail to achieve better results. Our work shows that the 'prior knowledge' is vital to KD, especially when applying large teachers. Particularly, we propose the dynamic prior knowledge (DPK), which integrates part of the teacher's features as the prior knowledge before the feature distillation. This means that our method also takes the teacher's feature as `input', not just `target'. Besides, we dynamically adjust the ratio of the prior knowledge during the training phase according to the feature gap, thus guiding the student in an appropriate difficulty. To evaluate the proposed method, we conduct extensive experiments on two image classification benchmarks (i.e. CIFAR100 and ImageNet) and an object detection benchmark (i.e. MS COCO). The results demonstrate the superiority of our method in performance under varying settings. More importantly, our DPK makes the performance of the student model is positively correlated with that of the teacher model, which means that we can further boost the accuracy of students by applying larger teachers. Our codes will be publicly available for the reproducibility.
Federated Unsupervised Domain Adaptation for Face Recognition
Apr 09, 2022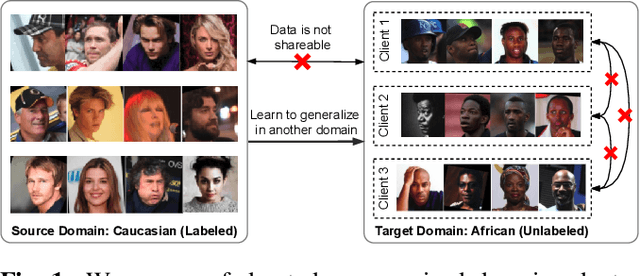

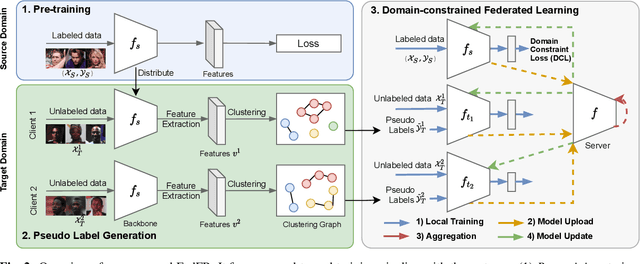
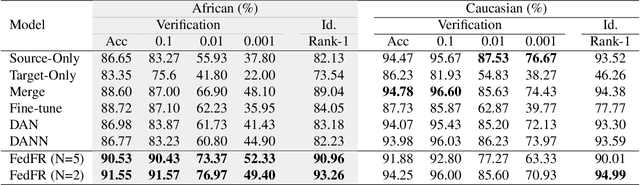
Given labeled data in a source domain, unsupervised domain adaptation has been widely adopted to generalize models for unlabeled data in a target domain, whose data distributions are different. However, existing works are inapplicable to face recognition under privacy constraints because they require sharing of sensitive face images between domains. To address this problem, we propose federated unsupervised domain adaptation for face recognition, FedFR. FedFR jointly optimizes clustering-based domain adaptation and federated learning to elevate performance on the target domain. Specifically, for unlabeled data in the target domain, we enhance a clustering algorithm with distance constrain to improve the quality of predicted pseudo labels. Besides, we propose a new domain constraint loss (DCL) to regularize source domain training in federated learning. Extensive experiments on a newly constructed benchmark demonstrate that FedFR outperforms the baseline and classic methods on the target domain by 3% to 14% on different evaluation metrics.
Pyramid Fusion Transformer for Semantic Segmentation
Jan 11, 2022
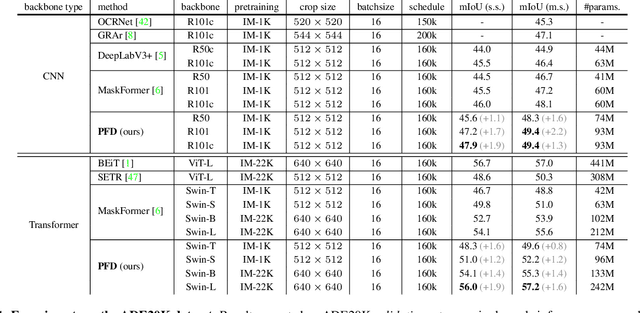
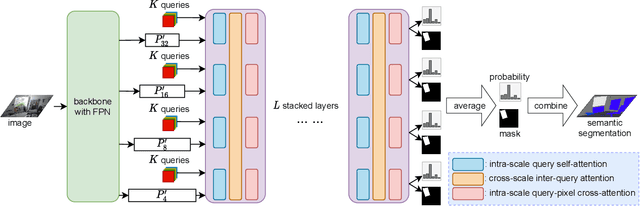
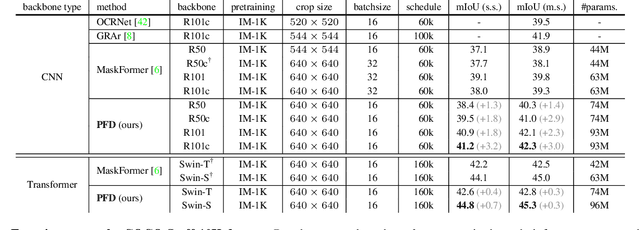
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.
Playing for 3D Human Recovery
Oct 14, 2021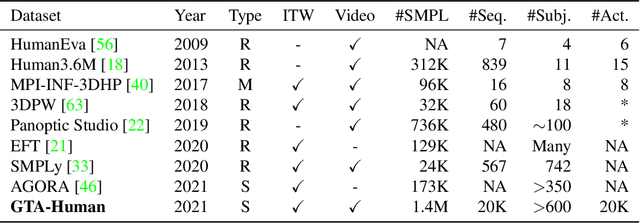

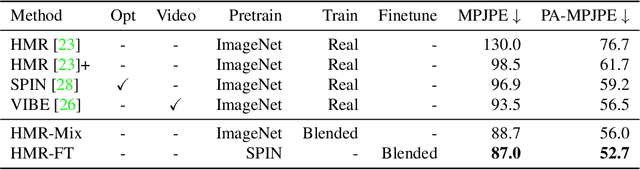
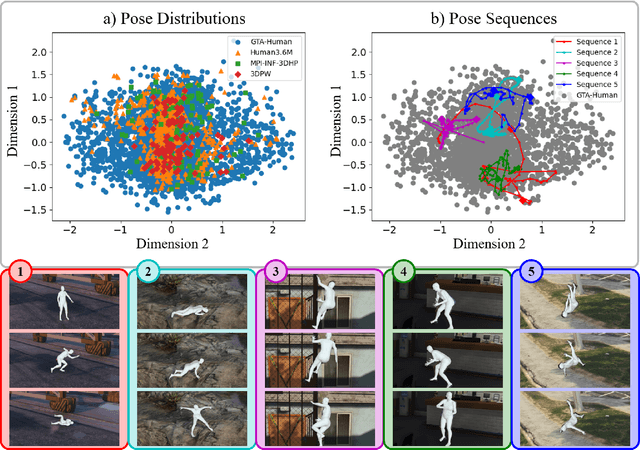
Image- and video-based 3D human recovery (i.e. pose and shape estimation) have achieved substantial progress. However, due to the prohibitive cost of motion capture, existing datasets are often limited in scale and diversity, which hinders the further development of more powerful models. In this work, we obtain massive human sequences as well as their 3D ground truths by playing video games. Specifically, we contribute, GTA-Human, a mega-scale and highly-diverse 3D human dataset generated with the GTA-V game engine. With a rich set of subjects, actions, and scenarios, GTA-Human serves as both an effective training source. Notably, the "unreasonable effectiveness of data" phenomenon is validated in 3D human recovery using our game-playing data. A simple frame-based baseline trained on GTA-Human already outperforms more sophisticated methods by a large margin; for video-based methods, GTA-Human demonstrates superiority over even the in-domain training set. We extend our study to larger models to observe the same consistent improvements, and the study on supervision signals suggests the rich collection of SMPL annotations is key. Furthermore, equipped with the diverse annotations in GTA-Human, we systematically investigate the performance of various methods under a wide spectrum of real-world variations, e.g. camera angles, poses, and occlusions. We hope our work could pave way for scaling up 3D human recovery to the real world.