 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Fusion Transformer for Semantic Segmentation
Jan 11, 2022
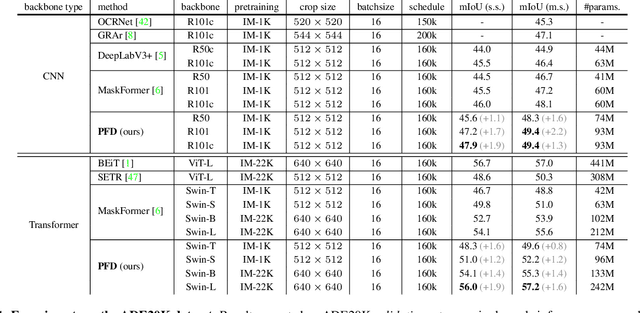
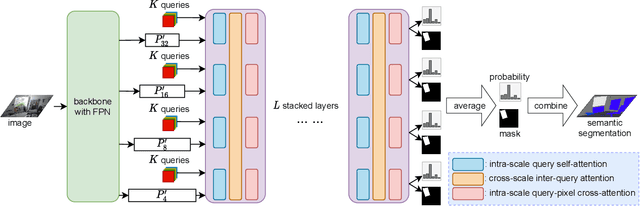
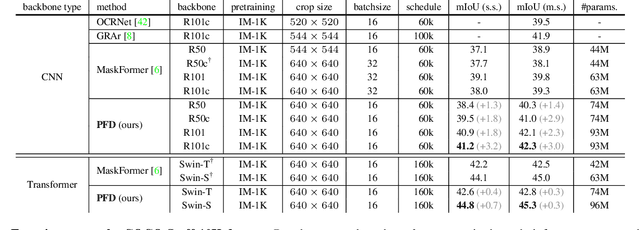
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.
Encoder-decoder with Multi-level Attention for 3D Human Shape and Pose Estimation
Sep 06, 2021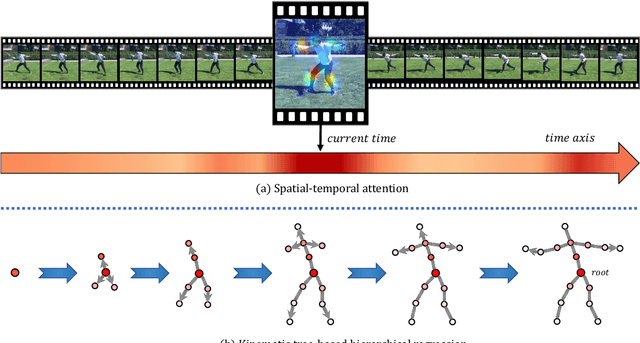
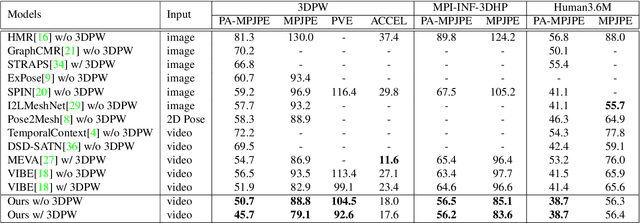
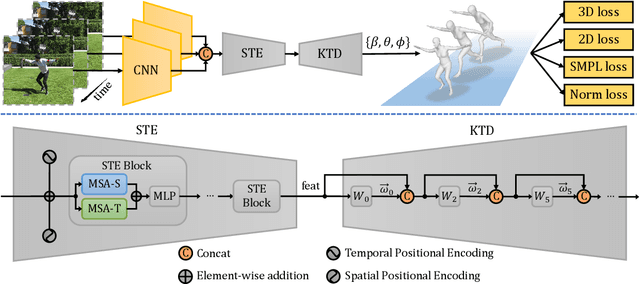
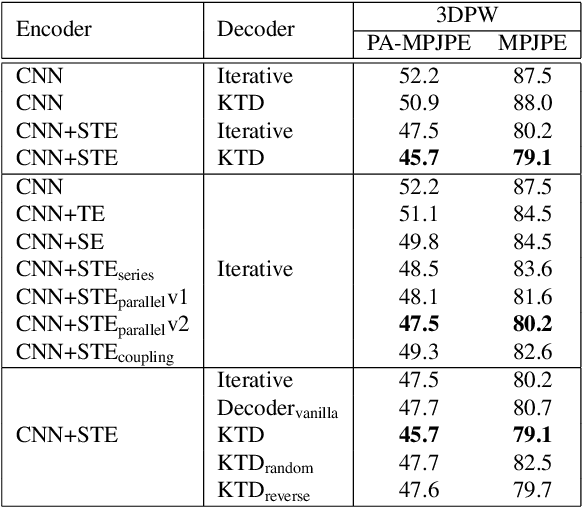
3D human shape and pose estimation is the essential task for human motion analysis, which is widely used in many 3D applications. However, existing methods cannot simultaneously capture the relations at multiple levels, including spatial-temporal level and human joint level. Therefore they fail to make accurate predictions in some hard scenarios when there is cluttered background, occlusion, or extreme pose. To this end, we propose Multi-level Attention Encoder-Decoder Network (MAED), including a Spatial-Temporal Encoder (STE) and a Kinematic Topology Decoder (KTD) to model multi-level attentions in a unified framework. STE consists of a series of cascaded blocks based on Multi-Head Self-Attention, and each block uses two parallel branches to learn spatial and temporal attention respectively. Meanwhile, KTD aims at modeling the joint level attention. It regards pose estimation as a top-down hierarchical process similar to SMPL kinematic tree. With the training set of 3DPW, MAED outperforms previous state-of-the-art methods by 6.2, 7.2, and 2.4 mm of PA-MPJPE on the three widely used benchmarks 3DPW, MPI-INF-3DHP, and Human3.6M respectively. Our code is available at https://github.com/ziniuwan/maed.
MagnifierNet: Towards Semantic Regularization and Fusion for Person Re-identification
Feb 26, 2020
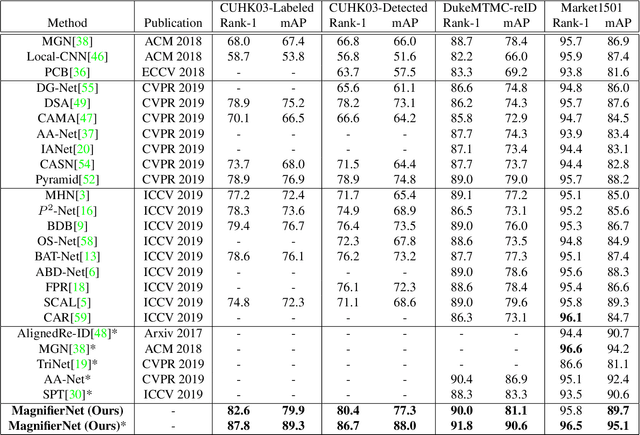
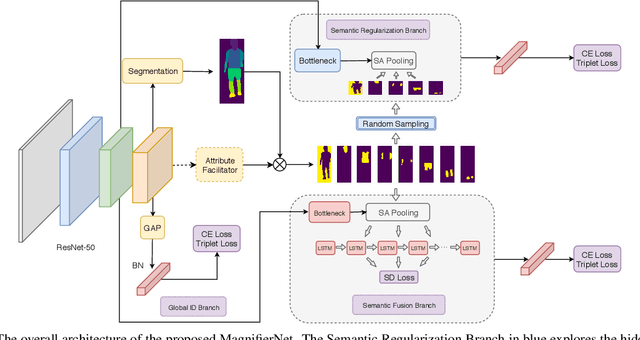
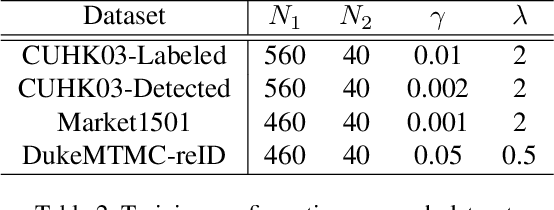
Although person re-identification (ReID) has achieved significant improvement recently by enforcing part alignment, it is still a challenging task when it comes to distinguishing visually similar identities or identifying occluded person. In these scenarios, magnifying details in each part features and selectively fusing them together may provide a feasible solution. In this paper, we propose MagnifierNet, a novel network which accurately mines details for each semantic region and selectively fuse all semantic feature representations. Apart from conventional global branch, our proposed network is composed of a Semantic Regularization Branch (SRB) as learning regularizer and a Semantic Fusion Branch (SFB) towards selectively semantic fusion. The SRB learns with limited number of semantic regions randomly sampled in each batch, which forces the network to learn detailed representation for each semantic region, and the SFB selectively fuses semantic region information in a sequential manner, focusing on beneficial information while neglecting irrelevant features or noises. In addition, we introduce a novel loss function "Semantic Diversity Loss" (SD Loss) to facilitate feature diversity and improves regularization among all semantic regions. State-of-the-art performance has been achieved on multiple datasets by large margins. Notably, we improve SOTA on CUHK03-Labeled Dataset by 12.6% in mAP and 8.9% in Rank-1. We also outperform existing works on CUHK03-Detected Dataset by 13.2% in mAP and 7.8% in Rank-1 respectively, which demonstrates the effectiveness of our method.
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
Sep 28, 2017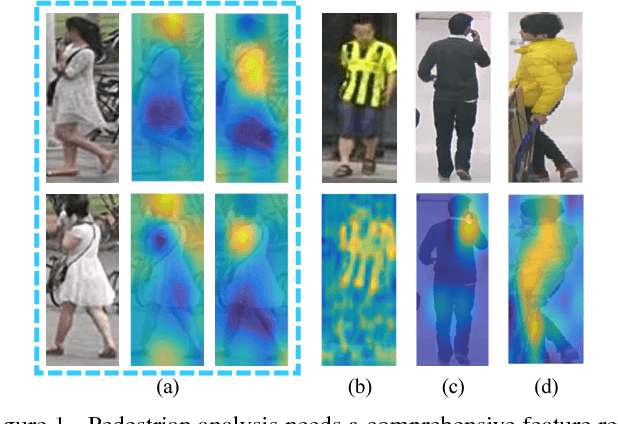

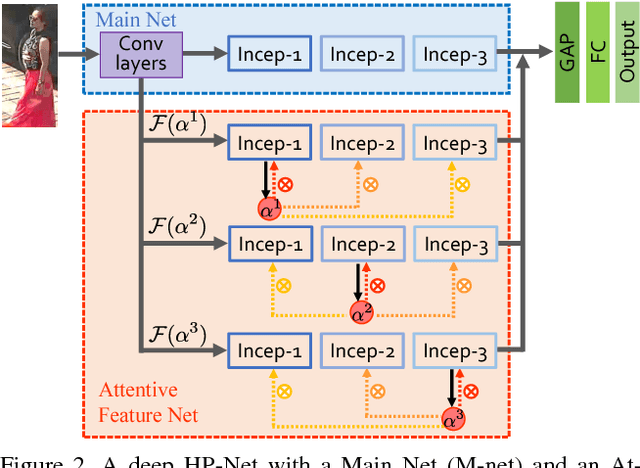

Pedestrian analysis plays a vital role in intelligent video surveillance and is a key component for security-centric computer vision systems. Despite that the convolutional neural networks are remarkable in learning discriminative features from images, the learning of comprehensive features of pedestrians for fine-grained tasks remains an open problem. In this study, we propose a new attention-based deep neural network, named as HydraPlus-Net (HP-net), that multi-directionally feeds the multi-level attention maps to different feature layers. The attentive deep features learned from the proposed HP-net bring unique advantages: (1) the model is capable of capturing multiple attentions from low-level to semantic-level, and (2) it explores the multi-scale selectiveness of attentive features to enrich the final feature representations for a pedestrian image. We demonstrate the effectiveness and generality of the proposed HP-net for pedestrian analysis on two tasks, i.e. pedestrian attribute recognition and person re-identification. Intensive experimental results have been provided to prove that the HP-net outperforms the state-of-the-art methods on various datasets.