 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Fusion Transformer for Semantic Segmentation
Paper and Code
Jan 11, 2022
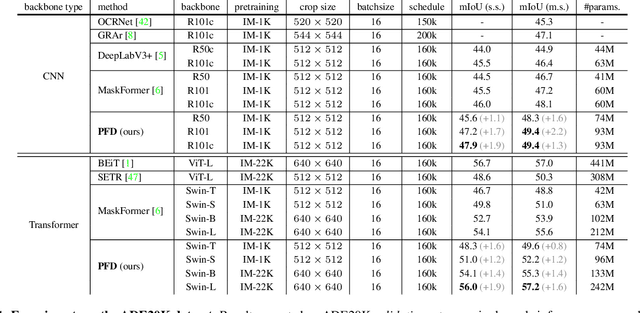
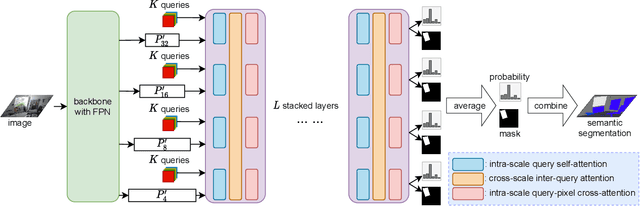
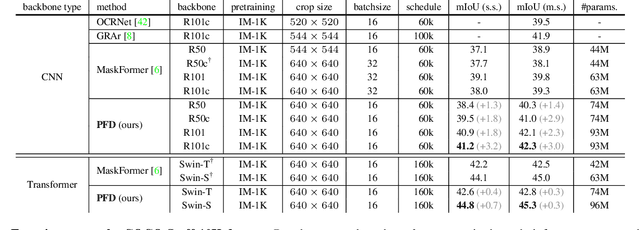
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.