 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomeWorld: A Unified Floorplan-to-Furnished Framework for Generating Controllable, Densely Interactive Whole-Home Scenes
Jun 04, 2026Indoor scene generation is crucial for robot simulation and modern interior design. However, complex layouts together with scarce 3D scene data make learning-based generation challenging. Existing methods often rely on hand-crafted rules or focus on isolated sub-tasks (e.g., floorplan synthesis or single-room furnishing), producing whole-home scenes that lack global coherence, realism, and simulation readiness. To mitigate these limitations, we propose a unified hierarchical framework that decomposes indoor scene synthesis into controllable stages. First, we curate a large-scale dataset of 300K real residential floorplans to train a large language model for whole-home floorplan generation. With detailed descriptions and a K-D tree-based representation, our method enables fine-grained, controllable whole-home floorplan generation. Building upon the generated whole-home floorplan, we leverage image generation models to draft furniture layouts from multi-level roaming viewpoints, and then generate the layouts of small manipulable objects on different supporting surfaces (e.g., cabinets, desks, and dining tables) for embodied AI simulation. During furniture and object layout generation, a VLM-based refiner iteratively corrects furniture and object placement, and a 3D generative model enables flexible replacement of individual assets. We further attach basic physical attributes and simple surface texture and lighting setups to complete the pipeline for embodied AI use. Experiments and user studies demonstrate that our pipeline produces indoor spaces with greater layout diversity and stronger 3D design appeal, outperforming prior methods on both quantitative and qualitative metrics. Finally, alongside our generation pipeline, we will release the floorplan dataset and 5K fully furnished scenes to the community. Project Page: https://kairos-homeworld.github.io/
Solving Challenging Math Word Problems Using GPT-4 Code Interpreter with Code-based Self-Verification
Aug 15, 2023



Recent progress in large language models (LLMs) like GPT-4 and PaLM-2 has brought significant advancements in addressing math reasoning problems. In particular, OpenAI's latest version of GPT-4, known as GPT-4 Code Interpreter, shows remarkable performance on challenging math datasets. In this paper, we explore the effect of code on enhancing LLMs' reasoning capability by introducing different constraints on the \textit{Code Usage Frequency} of GPT-4 Code Interpreter. We found that its success can be largely attributed to its powerful skills in generating and executing code, evaluating the output of code execution, and rectifying its solution when receiving unreasonable outputs. Based on this insight, we propose a novel and effective prompting method, explicit \uline{c}ode-based \uline{s}elf-\uline{v}erification~(CSV), to further boost the mathematical reasoning potential of GPT-4 Code Interpreter. This method employs a zero-shot prompt on GPT-4 Code Interpreter to encourage it to use code to self-verify its answers. In instances where the verification state registers as ``False'', the model shall automatically amend its solution, analogous to our approach of rectifying errors during a mathematics examination. Furthermore, we recognize that the states of the verification result indicate the confidence of a solution, which can improve the effectiveness of majority voting. With GPT-4 Code Interpreter and CSV, we achieve an impressive zero-shot accuracy on MATH dataset \textbf{(53.9\% $\to$ 84.3\%)}.
JourneyDB: A Benchmark for Generative Image Understanding
Jul 03, 2023While recent advancements in vision-language models have revolutionized multi-modal understanding, it remains unclear whether they possess the capabilities of comprehending the generated images. Compared to real data, synthetic images exhibit a higher degree of diversity in both content and style, for which there are significant difficulties for the models to fully apprehend. To this end, we present a large-scale dataset, JourneyDB, for multi-modal visual understanding in generative images. Our curated dataset covers 4 million diverse and high-quality generated images paired with the text prompts used to produce them. We further design 4 benchmarks to quantify the performance of generated image understanding in terms of both content and style interpretation. These benchmarks include prompt inversion, style retrieval, image captioning and visual question answering. Lastly, we assess the performance of current state-of-the-art multi-modal models when applied to JourneyDB, and provide an in-depth analysis of their strengths and limitations in generated content understanding. We hope the proposed dataset and benchmarks will facilitate the research in the field of generative content understanding. The dataset will be available on https://journeydb.github.io.
Pyramid Fusion Transformer for Semantic Segmentation
Jan 11, 2022
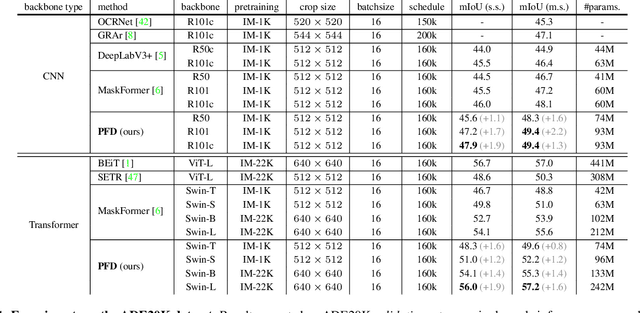
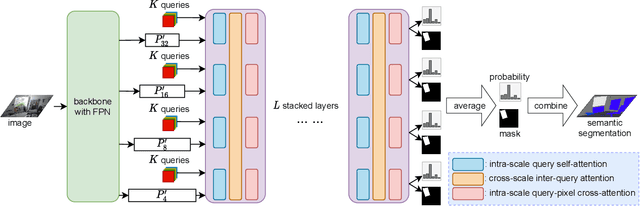
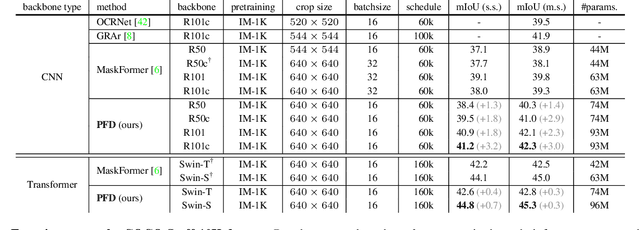
The recently proposed MaskFormer \cite{maskformer} gives a refreshed perspective on the task of semantic segmentation: it shifts from the popular pixel-level classification paradigm to a mask-level classification method. In essence, it generates paired probabilities and masks corresponding to category segments and combines them during inference for the segmentation maps. The segmentation quality thus relies on how well the queries can capture the semantic information for categories and their spatial locations within the images. In our study, we find that per-mask classification decoder on top of a single-scale feature is not effective enough to extract reliable probability or mask. To mine for rich semantic information across the feature pyramid, we propose a transformer-based Pyramid Fusion Transformer (PFT) for per-mask approach semantic segmentation on top of multi-scale features. To efficiently utilize image features of different resolutions without incurring too much computational overheads, PFT uses a multi-scale transformer decoder with cross-scale inter-query attention to exchange complimentary information. Extensive experimental evaluations and ablations demonstrate the efficacy of our framework. In particular, we achieve a 3.2 mIoU improvement on COCO-Stuff 10K dataset with ResNet-101c compared to MaskFormer. Besides, on ADE20K validation set, our result with Swin-B backbone matches that of MaskFormer's with a much larger Swin-L backbone in both single-scale and multi-scale inference, achieving 54.1 mIoU and 55.3 mIoU respectively. Using a Swin-L backbone, we achieve 56.0 mIoU single-scale result on the ADE20K validation set and 57.2 multi-scale result, obtaining state-of-the-art performance on the dataset.